The previous sections have described how digital library information can be represented in terms of basic concepts: digital objects, handles, and repositories. This section gives technical information about these concepts and how they are implemented.
The digital object
Section 3 described how different categories of information are organized as sets of digital objects for use in the digital library system. This section gives a more technical outline of the main parts of the digital library system, beginning with digital objects. The implementation of the digital object in the prototype system, scheduled for early 1997, is more flexible than the implementation in the earlier pilot system. This section describes the design of the digital object that is being implemented the prototype.
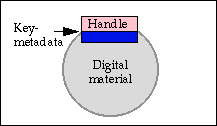
A digital object is a fundamental unit of the digital library architecture. The figure shows the visible parts of a digital object when used in a networked environment.
The figure shows the following components:
The digital material within a digital object is used to store digital library materials. For example, a digital object might store a text with SGML mark-up, or a record from an abstracting service. Digital objects may also contain less traditional library materials, such as computer programs, or mobile agents.
Digital objects have internal structure. This section describes the architecture of the structure that will be used in the prototype digital library system. The overall arrangement within a digital object is as follows.
Every element, package, and digital object has an identifier. The identifier for a digital object is a handle, which is known to the world. The identifiers for elements and packages are relative to the digital object and are not for general use.
Elements
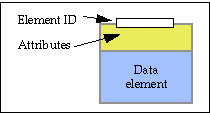
The figure shows:
Here are some examples of how various categories of information might be represented as elements within a single digital object.
Packages
Packages are used to group or associate elements and other packages. For example, one element might contain metadata about another element; the two could be grouped together into a single package. The next figure shows the parts of a package.
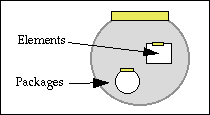
A package has a package ID. If the package is a digital object, the package ID is a handle. Otherwise, it is the internal identifier of the package within the digital object. Unlike a handle, which is unique and known publicly, such a package ID is of local importance only. The content of a package consists of elements and other packages.
Here are some examples of how packages could be used to represent library materials:
For a discussion of how packages can be used to represent metadata in digital libraries, see [9].
A digital object as a package
As stated earlier, a digital object is itself a package. The difference between a digital object and any other package is the existence of key-metadata. In particular, the digital object is identified by a handle. The key-metadata allows a digital object to be managed in a networked environment.
The digital library is assembled from a great variety of components. They include people, computers, networks, repositories, databases, search systems, Web servers, digital objects, elements of objects, bibliographic records, and many more. Keeping track of these components requires a systematic approach to identification.
CNRI has developed a set of general purpose identifiers, called handles, and a distributed computer system called the handle system for managing handles on the Internet. For full information about handles, see the Handle Home Page [6]. Handles are sometimes called "Uniform Resource Names (URN)" because they identify Internet resources by name, in contrast to the widely used Uniform Resource Location (URL) which identifies resources by location.
In the digital library system, handles are used to identify digital objects and repositories. However, handles are general purpose identifiers and can be used to identify almost any Internet resource (e.g., Web pages).
The Handle System
Handles are names that persist for long periods of time, but the resource that they identify may change its form, may be stored in many locations, move its location, or otherwise be altered with time. The handle system is a distributed computer system that stores handles and associated data that is used to locate or access the item named by the handle. Here is a simple example:

In this example, the handle is "cnri.dlib/july95-arms", which identifies an article in D-Lib Magazine. Two fields of handle data are stored in the handle system for this item, indicating that this article is available in two locations. Each data field consists of two parts. The first part is a data type; the second is the data. Thus the first data field is of type "URL"; the associated data is a conventional URL. The second is of type "RAP", indicating that the item can be accessed using the protocol known as RAP; the data is the address of the repository in which the item is stored.
Note that the handle for this article never changes. The handle data, however, may vary with time. For example, if this article is replicated in another location, another data field will be added. If an existing version is moved to a different location, the data will be changed.
Here is an example of how handles can be used to access items on the World Wide Web. An image is stored on a World Wide Web server at the Library of Congress and can be accessed with the URL:
This can be given the handle "loc.pp/4a32371". The corresponding record in the handle system is shown below (simplified):

If, later, this image is moved or stored in another repository, the data part of the handle record is changed. However, the handle itself, which is the name by which the outside world refers to the object, remains unchanged.
To resolve a handle is to present a handle to the handle system and receive as a reply information about the item identified. A common use of the handle system is, given a name (handle), find the location or locations of the digital object with that name.
The handle system is a distributed computer system, with many computers distributed across the world. CNRI manages a global handle registry and there are local handle services operated by other organizations. For the Library of Congress, a local handle service has been created. After testing at CNRI, it is being moved to a computer at the library at the beginning of 1997. (For technical details, see the Handle Home Page [6].)
Naming Authorities
Handles are created by naming authorities, administrative units that are authorized to create and edit handles. The name of a naming authority consists of one or more strings, separated by periods. Examples are:
The handle system provides two mechanisms to control who has permission to create naming authorities and create and edit handles: individual administrators and administrative groups. The latter are recommended as more flexible and convenient.
Each naming authority, has at least one administrator or administrative group with full privileges for that naming authority, including permission to create a sub-naming authority. The administrator creates permissions for administration of handles within that naming authority, and can also create new naming authorities. Administrators can delegate privileges to other administrators, including the privilege of creating sub-naming authorities.
The creation of naming authorities is delegated in a hierarchy. For example, the global naming authority created the high-order naming authority, "loc", for use by the Library of Congress. The administrator for "loc", created "loc.ndlp" for use by the National Digital Library Program, and the administrator of "loc.ndlp" created the naming authority "loc.ndlp.amrlp" for the Coolidge Consumerism compilation.
Structure of a Repository
A repository is a system for networked based storage and access to digital objects. All interaction with the repository uses a simple protocol, known as the Repository Access Protocol (RAP). RAP has a small number of fundamental operations, such as "deposit", which stores a digital object in the repository, and "access", which provides access to a digital object. Thus RAP provides a clearly defined, open interface for the repository that allows others to write clients and higher level interfaces.
The repository makes no assumptions about the content of digital objects. It can store digitized text, images, audio, binary data, etc.. The repository stores a data type for every element of every digital object, but does not comprehend the internal structure of any particular format, such as jpeg or SGML. All requirements for conversion between formats or presentation for users are external to the repository. In general, the stored form of a digital object may be different from the form in which it is disseminated or presented to a user.
Security is an integral part of the repository design and of RAP. Rights and permissions are associated with both the repository as a whole and its stored digital objects. Deposit of a digital object in a repository associates rights and permissions with that object and the implementation of every RAP command includes an explicit validation of the terms and conditions for access.
The next figure shows how the repository is implemented as three layers.
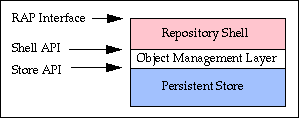
As shown is the previous figure, the interfaces between the three layers are clearly defined Application Program Interfaces (APIs). This permits individual layers to be changed independently.
Implementation
We have designed and implemented an object-oriented version of the RAP protocol, using a distributed object model. A simple repository class was defined with the RAP commands as methods of this class.
There was some discussion whether to use a lower level design, which did not presume an object-oriented interface. This would allow a greater selection of languages and interface tools but, on balance, we considered that the advantages of an object-oriented approach outweighed these concerns. An object-oriented approach promotes good software engineering and has allowed rapid development of a powerful set of services. Being able to pass high level structures such as objects (in the object-oriented sense) across the network provides real advantages, particularly if other system components are also using an object-oriented software paradigm.
The network-based object-oriented design is uses the CORBA distributed object standard. CORBA is becoming widely accepted in the software industry, but CORBA is not yet universally accepted. Therefore the RAP commands are implemented as methods on object classes in a way that does not depend on specific features of CORBA.
The Repository Access Protocol
All interactions with the repository use the Repository Access Protocol (RAP). For the pilot repository, the following RAP commands were implemented. Each is implemented as a method on the repository class.
In addition, a small number of methods have been implemented to administer the repository. These methods are not part of RAP.
Identifying Repositories
The internal organization of a repository is not made public and can therefore be changed transparently to the client. For example, during development of the repository for the NDLP the internal storage method is being completely revised, but clients using the repository did not need to be modified. This is achieved by giving each repository and every digital object a handle. The next figure shows how the data stored in the corresponding handle records is used to execute a typical RAP command.
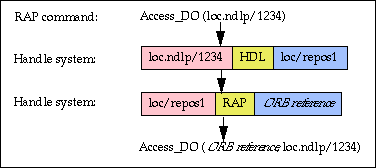
In this example, the RAP command "Access_DO" is used to access the digital object with handle "loc.ndlp/1234". It goes through the following steps:
Since the digital object is identified by a handle, if it is moved to another repository the only change required is to alter the data in the first of the handle records in the figure. Since the repository is identified by a handle, if the repository is moved to a different computer or otherwise changed, but its handle remains the same, altering the single data item in the second handle record in the figure is the only change needed, for all the digital objects stored in the repository.
Further Information about the Implementation
In both the pilot and prototype systems, the repository shell uses Xerox's ILU system as its CORBA library. ILU provides a good selection of language bindings for a range of hardware platforms. ILU is also being used by several universities for related work in the NSF/DARPA/NASA Digital Library Initiative (DLI), e.g., the Stanford University InfoBus[10]. The pilot repository shell was originally written in C++ but has since been recoded in Python, which is better supported by ILU.
There are two major changes between the pilot and the prototype versions of the repository shell.
As mentioned above, the pilot used an object-oriented database (Shore) for the persistent store. For the prototype, we evaluated three different approaches for the next generation of persistent store: a relational database (Oracle), another object-oriented database (ObjectStore), and the Unix file system. Each has its advantages and each is compatible with the repository shell. The Unix file system was selected for reasons of simplicity of administration, and widespread availability. In addition, the use of the Unix file system allows us to distribute the software to other libraries and research groups without additional licensing costs. Although this decision forced us to implement transaction integrity for a repository that uses the Unix file system, these advantages were reckoned to outweigh the advantages of the formal databases.
Repository Clients
Repository clients are used to locate and manipulate digital objects contained in repositories. The next figure describes the relationships between the repository, the repository clients, and the handle system.
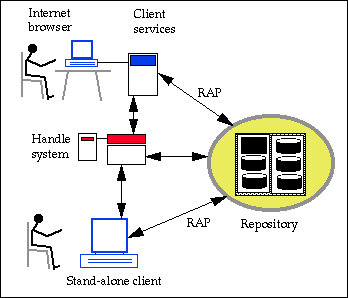
The figure shows the two different types of clients that were implemented for the pilot repository. Early in the project we implemented a stand-alone user interface that communicates directly with the repository using RAP and also manages the actual interactions with the user. It communicates directly with the handle system using the handle client library. The stand-alone client was coded in Python and tk in order to run as a Grail applet. The applet design was tested successfully but was discontinued because of its lack of flexibility.
Indirect user interfaces are now being used exclusively. They consist of an Internet browser for interactions with the user and client services. For the pilot, the client services are sets of cgi-bin scripts. The next figure shows how the client services are implemented.
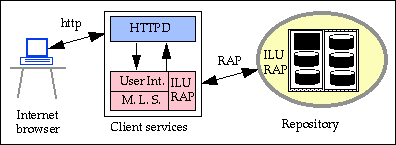
As the figure shows, the scripts can be separated into two different functional sets. The first set is responsible for generating the user interactions to be displayed using the Internet Web browser. The second set is independent of the browser and is responsible for establishing connections with the repository using the RAP protocol. This latter set of scripts is called the Mid Level Software or MLS. The ability to resolve handles is embedded within the user interface scripts.
This architecture provides considerable flexibility since the MLS can be interfaced by third party user interface scripts. This feature allows for future repository users to have multiple choices of interfaces to communicate with the repository. Currently, the supported interfaces to the repository are RAP over ILU and HTTP/HTML. Future implementations could use Java or C++.
User Interfaces for Librarians and System Administrators
For the pilot system, a user interface was developed that has the features required by librarians and system administrators. The user interface is implemented as a set of client services. These services are cgi- bin scripts, written in Python. At present, the interface has the following features.
The use of client services has some important limitations and there are some features not implemented in the pilot. The most serious limitations come from the connection between the browser and the client services. This connection uses the http protocol which is not connection oriented. The state of the repository communications must be passed back and forth between the cgi-bin scripts and the browser adding overhead and potential security problems. In addition, the interface is not as flowing as the stand- alone interface because every time a request is made by the user, a new form needs to be generated for the browser. These are temporary problems and should all be overcome in the prototype system.
Browsing Digital Objects in a Repository
The stand-alone user interface and the librarian client were both designed as administration tools to create, edit, access, and delete digital objects. Both originally suffered from a fairly complicated, unfriendly user interface. A browsing interface has been created for library users that provides different techniques for handling and navigating through sets of digital objects. The digital object structure is hidden from the user, and the interface relies on the structure of the digital objects to organize the information that the user sees.
The digital object browser for the pilot system is implemented as set of client service, also written in Python. It has the following features:
The digital object browser depends upon the organization of the information in the repository. It behaves according to predefined rules for each category of information and assumes that intellectual works have been represented as sets of digital objects according to appropriate rules and conventions. Thus it delegates most of the nature of the digital object browsing to the digital object set builder. This results in the data modifying the behavior of the digital object browser.
The use of sets of digital objects to represent information was introduced in Section 3. Sets are built by linking digital objects together. In the pilot system, sets are assumed to be hierarchical and digital objects are provided with child and parent links. This is shown in the next figure:
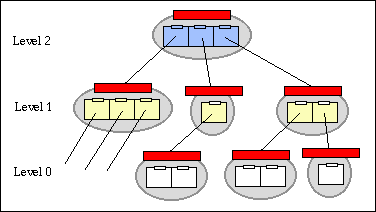
In the pilot, the links are defined as follows:
Although all digital objects within a set share the same structure, there is a need for the digital object browser to distinguish different digital object types. For example, the digital object browser will display and manipulate a meta-object for a scanned photograph differently from the individual versions. For the pilot system we implemented three levels of logical types to support the hierarchy shown in the figure:
This three level structure is excellent for providing access to sets of digital objects that are in a true hierarchy. However, it lacks flexibility. The enhanced digital object structure designed for the prototype has dispensed with the distinction between child and parent links. All links are equal and arbitrarily complex structures can be created.
Return to Sections 1-4
Continue to Section 6. References
Go to Section 7. Acknowledgments
Approved for release, February 14, 1997.




hdl:cnri.dlib/february97-arms