|
Search | Back Issues | Author Index | Title Index | Contents |
![]()
D-Lib Magazine
|
|
|
Theo van Veen Bill Oldroyd |
![]()
AbstractThe objective of the European Library (TEL) project [TEL] was to set up a co-operative framework and specify a system for integrated access to the major collections of the European national libraries. This has been achieved by successfully applying a new approach for search and retrieval via URLs (SRU) [ZiNG] combined with a new metadata paradigm. One aim of the TEL approach is to have a low barrier of entry into TEL, and this has driven our choice for the technical solution described here. The solution comprises portal and client functionality running completely in the browser, resulting in a low implementation barrier and maximum scalability, as well as giving users control over the search interface and what collections to search. In this article we will describe, step by step, the development of both the search and retrieval architecture and the metadata infrastructure in the European Library project. We will show that SRU is a good alternative to the Z39.50 protocol and can be implemented without losing investments in current Z39.50 implementations. The metadata model being used by TEL is a Dublin Core Application Profile, and we have taken into account that functional requirements will change over time and therefore the metadata model will need to be able to evolve in a controlled way. We make this possible by means of a central metadata registry containing all characteristics of the metadata in TEL. Finally, we provide two scenarios to show how the TEL concept can be developed and extended, with applications capable of increasing their functionality by "learning" new metadata or protocol options. 1. IntroductionThe European Library Project (TEL) is partly funded by the European Commission as an accompanying measure under the cultural heritage applications area of Key Action 3 of the Information Society Technologies (IST) research programme. TEL is a collaboration of a number of European national libraries under the auspices of CENL (Conference of European National Libraries). Co-ordinated by the British Library, the TEL project partners include: At the start of the TEL project, we formulated the following primary objectives for TEL:
By following these objectives, the TEL project has developed, sometimes in unexpected ways, into a very powerful starting point for an operational service. 2. Development of search and retrieval in TELThe steps towards a new search and retrieve protocol based on http and XMLAlthough the use of Z39.50 is widespread, it was anticipated that an obvious alternative would be to search using standardised URL parameters and to provide responses using XML1. The Koninklijke Bibliotheek already had experience with this type of search and retrieval and so TEL started with the specification and development of a protocol for search and retrieval using URLs and XML. The early ideas for such a protocol had already been described in a paper by van Veen presented at the 2001 ELAG conference [ELAG]. By the time the TEL http/URL/XML protocol was specified and implemented, the Z39.50 Implementers Group [Z39.50] had developed a similar concept: Search and Retrieve via the Web (SRW). SRW was announced as an alternative to Z39.50 under the umbrella of the Z39.50 international Next Generation [ZiNG] Two access mechanisms were proposed: 1) SRW (Search and Retrieve via the Web), based on the use of SOAP2 and 2) SRU (Search and Retrieve via URLs), based on the use of URLs. Both approaches offer a lower implementation barrier than Z39.50 and are more amenable to implementation in modern systems. SRU is the simpler of the two mechanisms. With SRU, a search request takes the form of a base-URL and associated parameters, such as the query, the start record, the maximum number of returned records and the record schema. By varying the base-URL the same SRU search request can be sent to different targets (see Figure 1).
Figure 1. A simple example of a search command using the SRU protocol
Figure 2. A simplified example of the XML returned by the SRU server As shown in Figure 2, the response is in XML, which allows it to be processed automatically. By varying the stylesheet3, the presentation of the content can be changed (for example, as shown in Figure 3). The power of the SRU approach is that by simply changing the stylesheet parameter, the user interface of the search service can be completely altered (for example, to provide an interface in a different language).
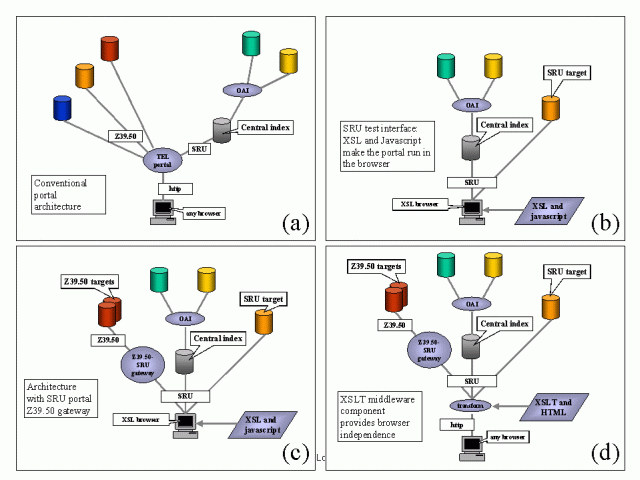
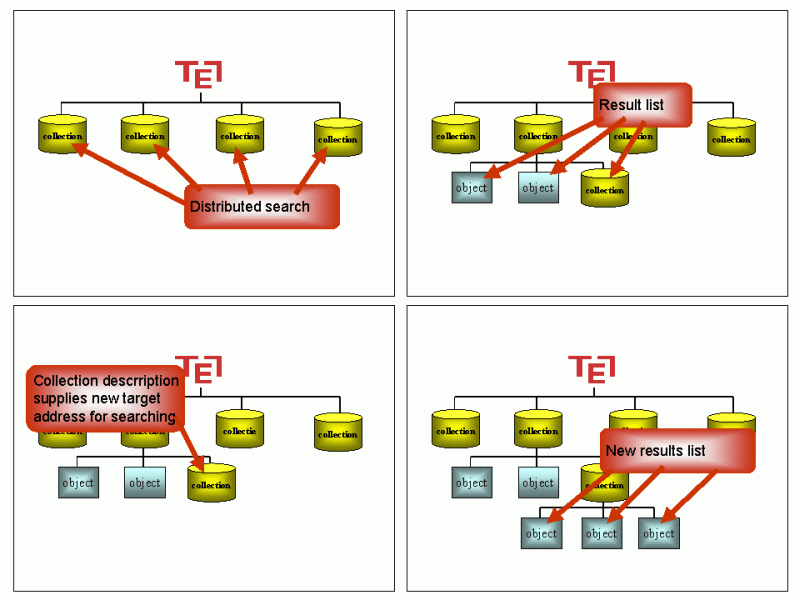
(Click here to see a larger version of Figure 3.) The SRW approach uses SOAP as an extra protocol layer, the main difference in the protocol being that a search is defined using XML. SRW can therefore provide for more complex search parameters. An advantage of SRW is that it can be integrated into the service framework provided by SOAP web services. On the other hand, a benefit of SRU is that it is very similar to most web-based search and retrieval applications, with the exception that those interfaces respond with HTML rather than XML. In the interest of standardisation, TEL adopted SRU as the http/XML search and retrieval protocol by implementing the first draft specifications of SRU. At the start of the TEL project, SOAP did not provide the same advantages as SRU. In addition, SRU has a low implementation barrier compared to SRW. A test interface for SRU access to the TEL central index was implemented using XSLT4 and JavaScript5. We also anticipated TEL would require SRU access to more databases than just the TEL central index, so we developed the test interface into a testbed running in the browser and giving simultaneous access to services supporting SRU. Using Internet Explorer it was quite easy to send a single query simultaneously to different targets and present the results asynchronously as the results were returned to the browser. The architecture of this concept is shown in Figure 4b. In order to meet the objective of merging the SRU and Z39.50 testbeds, a very obvious approach was to extend the services accessed by the SRU testbed by introducing a gateway to allow SRU access to Z39.50 targets. The architecture for this is shown in Figure 4c. Once the gateway was developed, we were able to use the architecture for testing the results of the metadata development, and it became clear that this architecture could also offer the desired functionality for the TEL portal. One of the objectives of the TEL project was to select a portal for The European Library and for this purpose we compared ten commercial portals as potential candidates. However, the SRU portal proved to be more promising than the commercial portals—with the specific benefits of low cost and low risks—providing TEL with a low barrier of entry for new partners and new collections, and giving TEL full control over the functionality of the portal. The potential for further development will be explained in more detail later in this article. One drawback of the SRU portal is its browser dependence. The user's browser must be able to support XSLT and JavaScript. In addition, MS Internet Explorer has one annoying drawback as a browser for SRU. XML responses from one server cannot be transformed by an XSLT script obtained from another server unless a specific security permission is set. Whilst it is easy to set the permission, the user must be aware of the need to do so. Both these issues are addressed by adding an extra central component that transforms the SRU responses from XML to HTML with minimal browser dependencies. Doing this results in the architecture shown in Figure 4d. In this way, the SRU approach can target different audiences using different architectures. We can serve users who require full control over functionality at the cost of those users having to pay more attention to security and to their browser environment. We can also serve users who have limited control over their environment or have browsers with limited capabilities (for example, a mobile device).
(Click here for a larger view of Figure 4.) Both architectures as shown in Figures 4c and 4d will be used in TEL. The TEL PortalThe TEL Portal runs in a standard browser using JavaScript and XSLT. A set of service and collection descriptions encoded in XML are loaded into the browser either from a URL or from a local file. An XSLT stylesheet presents the collection descriptions to the user and the user selects the services or collections required for the search. The search query is defined using CQL (Common Query Language) [CQL]. CQL may vary from simply searching for one or more words to complex Boolean expressions using different indexsets. An example of a more complex CQL query is:
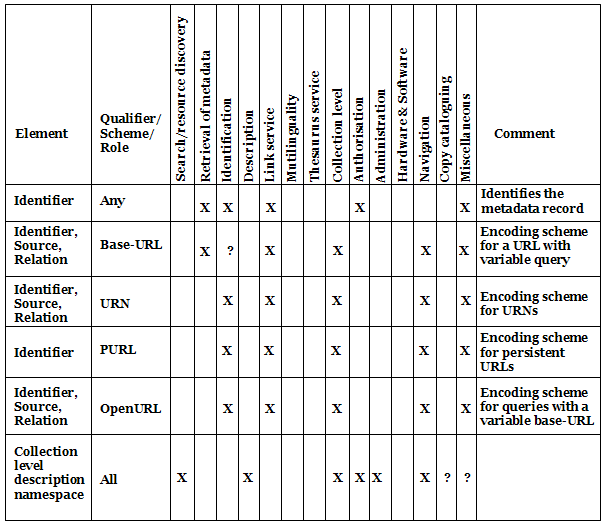
A search form is used to create the query, which is human readable. The bold words in the example above are CQL keywords and the unbold text is entered by the user. Truncation, Boolean expressions, fuzzy searching can all be expressed in CQL. The prefix "dc." defines an indexset. Servers may use different indexsets, which are defined together with other information describing the server configuration in a record called the "explain" record. Using the query, a JavaScript function initiates parallel searching across the services for all the selected collections. The results are received by the browser asynchronously as independent SRU responses in XML. The XML is transformed using a stylesheet selected by the user. The stylesheets contain the logic to present the XML elements using characteristics from the TEL registry and to offer the user specific functionality for each type of element, such as providing access to digital objects, document ordering, translation and further searching. The detail of this functionality is described later in this article. The Z39.50-SRU gatewayThe Z39.50-SRU gateway allows the adoption of the SRU protocol by TEL partners whose library systems can only support Z39.50. To do this, the gateway has to perform a number of transformations. For example, it will perform the necessary transformation between the SRU search query language and the Z39.50 query accepted by the target. This includes character set processing and matching with appropriate indexes. Transformations also take place on output, (for example, conversion of the record format from MARC to the TEL metadata profile and/or a character set conversion from MARC8 to Unicode). The implementation of the gateway is straightforward and the source code and information about installation can be downloaded from the British Library [Z-gateway]. We anticipate that SRW and SRU will gradually replace Z39.50, and we hope the Z39.50-SRU gateway will stimulate the acceptance SRU/SRW, as it allows existing Z39.50 services to be made available as SRU services without any change. While both protocols exist in a mixed environment, using a Z39.50-SRU gateway allows existing investments in Z39.50 targets to be retained. This integration means Z39.50 targets are accessible in the same environment as SRU targets, for example the service, or a specific search, could be accessed by a hypertext link on a web page. A central source of generalised XSLT transformations for the SRU responses would help to promote this idea. 3. Metadata developmentSteps towards a TEL Application Profile based on analysis of functionality.After our initial analysis of the metadata standards used by the TEL project participants, we decided to adopt XML as the common record syntax and to use a Dublin Core [Dublin Core] based model for object description. Resource Description Framework (RDF) was considered as a future option for encoding the metadata. We chose the DC Library Application [DC-Lib] Profile as the starting point, modifying it as necessary to support the functionality required by an operational TEL service during the course of the project. The concept of application profiles emerged from the DCMI [Dublin Core] as a means of combining elements from different element sets for use in a specific application. In order to simplify the establishment of both testbeds and gain experience with this approach, we used simple Dublin Core for the pilot implementations. At a later point in the project, and following on from the functional requirements, the extended Library Application Profile [DC-Lib] was adopted. To check whether the Library Application Profile met functional requirements, the elements from the Library Application Profile were mapped to a number of basic functions required by the TEL portal. A matrix with all the elements on one axis and all the functions on the other showed all possible combinations and, for each combination, we established whether it was relevant to TEL, and—when needed—we added new elements. This mapping process is illustrated in Figure 5. In addition to looking at the combinations, this exercise also indicated which elements were required for specific functions. Finally, as a third way of looking at this, the functionality that could be offered as a result of receiving specific metadata became evident. For example, if an abstract is present, not only can it be displayed but it can also be translated into another language. The end result of this process is to reveal all the elements needed for specific functionality and to identify the total behaviour of the TEL portal that depends on the presence of specific metadata. The mapping process produced two different application profiles, one for objects and one with additional elements for collections. The most significant additional elements concerned collection level descriptions [CLD] is linking to objects and services and record identification.
During the mapping process, we realised that TEL would evolve over time, and a snapshot of the functional requirements at any one time could quickly become outdated. Once TEL has become an operational service, new collections will become available and new functionality may be required, and this functionality may depend on using new elements. Collections of different types of material—possibly by the extension of TEL into new sectors—may also require specific elements of which we are not currently aware. Therefore, the TEL Application Profile should not be static. TEL should have a mechanism to enable the Application Profile to evolve in a controlled way. We developed the TEL metadata registry to fulfil this need. The TEL metadata registryThe TEL metadata registry should not be confused with a registry that has the sole purpose of recording the valid elements within a particular scheme (for example, the DCMI registry). The TEL registry sets out to record all the metadata activity associated with TEL. It therefore contains not only all the elements that are part of the TEL application profiles, but also elements that have been proposed but have not yet been accepted for one of the application profiles and those elements that have been rejected. Each entry in the registry is defined by the triple: "element name, qualifier and encoding scheme", each combination being described separately with its own characteristics. The characteristics include the element source namespace, descriptions and definitions made in the application profiles, additional information related to conversions and functionality useful in operating the TEL portal. For example, the registry contains translations of element names into different languages, and declares whether the element is repeatable, searchable, and mandatory. The purposes and aims of this registry and the tools related to it are to:
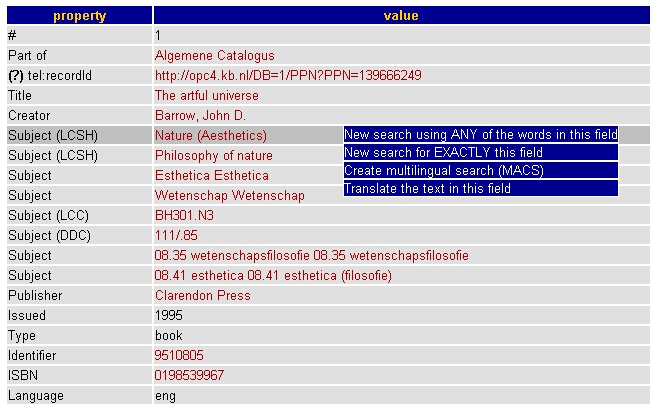
All the registry contents are made available as XML to the various tools that support the maintenance of the registry and the use of the registry information by the TEL portal. Whilst the registry is an essential part of TEL, it may also serve the much wider purpose of sharing metadata definitions outside the TEL service. It may provide a way for the European national libraries to share metadata and the functionality of metadata for overlapping application areas related to European cultural heritage beyond the requirements of the TEL portal. Adding a new element to the registry often implies adding functionality such as presentation, search functionality and navigation. These functions can be part of the groups of functions that were used in the mapping process described above or can be new functions. Sharing the meaning of an element in the registry means that different applications can apply the same functionality off a term. Both the definitions of an element and the actual usage are relevant for sharing elements with a minimum of ambiguity. This is especially true when we try to make this information usable in a machine-readable way, and it is expected that the mechanism for using the information in the registry will evolve gradually, based on incremental experience. Service providers may update their applications based on an inspection of the registry triggered by the occurrence of new terms or settings, or applications may use this information automatically. For example, from the moment an element in the registry is indicated as displayable, an application utilising the registry may use this information to automatically determine whether or not to display that element. How this may be achieved is explained later in this article, but the SRU Portal [TEL portal] provides an initial illustration of the concept. Whilst the SRU portal was developed in order to test the SRU service, it also proved suitable for testing the results of the metadata development. For this purpose, we created stylesheets to utilise the registry to check whether an element is part of the application profile and is encoded correctly. It is also possible to show metadata elements that are not in the registry, which can be useful to alert the user to new elements that are not yet known to the application but that might contribute useful functionality in the future. This method of "learning and understanding standards"—which can be used in addition to the usual standardisation processes—is more in line with the way human beings learn to use new features. If client applications can recognise and present new elements found in a metadata record, it may trigger the ability of humans to recognise new functionality. 4. Combining SRU and metadata based functionalityWe will now describe how SRU and the metadata approach have been successfully combined. The response to an SRU search is an XML document. An XSLT stylesheet can be used to define how the different elements of the document are processed and displayed. This can also be derived from the characteristics defined in the registry where, based on the functionality specified against a specific element, the portal can take a number of actions. For example, the presence of the element "isPartOf" may trigger the portal to offer navigation to a parent object, or an abstract may trigger translation services, and so on. Figure 6 shows a screen dump of a sample record along with some functions offered based on the presence of a specific subject element. For most elements, several functions are possible. In the TEL portal, different stylesheets are used for different types of presentation and based on information from the registry, variations such as element name translations. Users may also choose different stylesheets based on their specific preferences or to obtain specific functionality. The impacts of this are that portal functions are implemented in the browser and the central service is not aware of the other services a user might be accessing. With the TEL approach, it is possible to obtain machine-readable data from the TEL service and use these data as input to services of the user' choice. This is a significant advantage of the TEL portal: the portal function runs in the browser and so all integration takes place at the user's workstation.
The services shown in Figure 6 are just examples. The powerful aspect of the "portal in browser" approach is the ability for institutions, or even individual users, to control their own functionality by specifying their own stylesheets. CollectionsThe TEL application profile for collections enables a collection to be described by a metadata record within the central index. TEL participants can incorporate new collections and catalogues into the TEL service simply by adding new records to the index. Apart from elements containing descriptive information, the application profile contains elements that define how to perform a SRU search of the collection, such as the base-URL of the collection's SRU service. The functionality associated with this base-URL is to offer the user the option to make this service one of the portal's new targets. This is illustrated in Figure 7. The services offered through the TEL portal are therefore data-driven, both in terms of the material for which the user can search and in the functions a user can perform on the retrieved records.
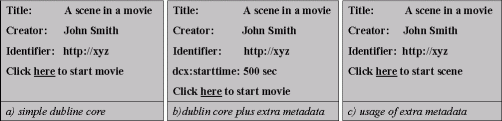
(Click here for a larger view of Figure 7.) 5. Future ScenariosWhen SRU is more widely adopted by the Internet community we expect there will be a need for further development. An important feature of the TEL concept—the combination of SRU, the metadata registry and the implementation of the portal in the user's browser—is to simplify development to meet new functional requirements. We will illustrate this by presenting two scenarios. Handling extensions to Dublin CoreWe expect that many applications will use Simple Dublin Core or—to meet specific functional requirements—Dublin Core with local extensions. The schemas defining such extended records are generally unknown to other applications. Client applications using the SRU and OAI-PMH protocol can only request known record schemas from the server and will probably never be aware of the potentially useful extensions to the standard DC record schema. Now, imagine a scenario in which a client application could request a record that comprises Dublin Core plus unknown local extensions. The target system responds with a message saying, "Here is DC, plus some additional fields." The client (or portal) displays the known terms and indicates that there are also data fields unknown to the client. These fields may be of interest, and the user may want to investigate the exact meaning of these new terms. As a result, he may choose to use these extra fields to trigger extra functionality that is not offered by the original application but which can be realised by selecting another stylesheet. For example, consider a record describing a scene in a movie. The movie object is not under the control of the provider of the metadata. Next, suppose the database record has a local field identifying the start of a particular scene. Further suppose the user requests the local format and discovers that all elements are DC elements, which he already understands, plus the local element for the start time of the scene. The user may choose to use the content of this element to trigger a special external application that starts the movie from the beginning of the specified scene rather than from the beginning of the movie. This scenario is shown in Figure 8.
In this example, requesting a known schema like Dublin Core will retrieve only the Dublin Core record, whereas requesting Dublin Core plus local extensions will also allow retrieval of the unknown term "dcx:starttime". The user or service provider then has the option of finding out how to use this field and can adjust the client application accordingly. In the example shown in Figure 8, the service provider has added functionality related to the term dcx:starttime. The above scenario relies on the ability to request records that comply with DC or qualified DC but which may have local extensions. For this purpose, we have introduced DCX (Dublin Core eXtended) as a generic schema name. We hope the DCX concept will be adopted by DCMI as the standard way of identifying such records. At present, we use a temporary schema name for this purpose with the URI (http://www.kb.nl/persons/theo/dcx), but DCMI would be the most obvious naming authority for a formal DCX schema. The TEL metadata registry will be a possible place to register terms from such schemas and share knowledge on the characteristics of those terms. SRU protocol extensionsThe second scenario is an example related to the SRU protocol. When a user receives "0 hits" in response to a search, it is often very frustrating, as the user has little help on how to improve the search. Services might provide special responses in this case, such as guidance on similar searches, suggestions for correcting a typing error, a list of index entries close to the search terms, or a list of terms that are similar to the search term based on some matching process. Although SRU contains operations that would allow the portal to investigate the server's capabilities in supporting this type of guidance, it would considerably complicate the portal's functionality (bearing in mind the portal is implemented by a stylesheet and associated JavaScript functions). It would be more helpful if the user could request that the server respond to this situation directly. SRU version 1.1 has an extension mechanism in which extra parameters may be supplied; these are identified by means of the "x-" prefix. A server is free to ignore them, but servers that do understand such parameters can respond to them. For example, there may be a parameter "x-nohits=dosomething" that requests the server to respond with extra data to assist the user. If there are no records found by the search request, then the response to the search might include a list of index entries close to the search query (a scan operation). Servers that do not support particular parameters can be recognised by the client because they echo these unknown parameters in the search response. This example shows how SRU can be extended without conflicting with the current standard. When a larger community adopts the extensions, the standard itself can be extended. It allows data and service providers to use the SRU protocol without being limited by the protocol: one can take part in the standard and at the same time add local extensions. Both scenarios described above show how the TEL approach allows data providers to enter their collections into TEL without losing functionality or being restricted in functionality. 6. ConclusionsThe TEL approach and technical solution described in this article—consisting of a SRU portal running in the browser, a gateway and a data model based on the concept of Dublin Core Application Profiles—offers a number of advantages compared to more conventional approaches. The advantages include scalability, functionality, low barrier of entry into TEL, and increased control of functionality for users, data providers and service providers. Last but not least, with the TEL approach there is no longer a need for a central portal. With the combination of concepts like DCX and the SRU extension mechanism, the TEL approach can undergo further development and could become an example for similar projects. Notes[1] XML: eXtendible Markup Language [2] SOAP: Simple Object Access Protocol [3] Stylesheet: a script that defines the transformation of XML documents, for example to HTML [4] XSLT: eXtensible Stylesheet Language Transformation [5] JavaScript: scripting language for web documents [6] LCSH: Library of Congress Subject Heading Bibliography[CLD] RSLP model for collection level descriptions: <http://www.ukoln.ac.uk/metadata/rslp/schema/>. [CQL] Common Query Language <http://www.loc.gov/cql>. [DC-Lib] Library Application Profile <http://dublincore.org/documents/2002/09/24/library-application-profile/>. [Dublin Core] Dublin Core Metadata Initiative <http://dublincore.org/>. [ELAG] Theo vanVeen, 2001, "Linking electronic documents and standardisation of URL's", paper presented at the European Library Automation Group 2001, Integrating Heterogeneous Resources, April 2001 Prague, available online at <http://www.stk.cz/elag2001/Papers/>. [OAI-PMH] OAI-PMH: <http://www.openarchives.org>. [RLSP] Michael Heany, "Comprehensive study on collection level descriptions" (Research Support Libraries Programme, RSLP) <http://www.ukoln.ac.uk/metadata/rslp/model/amcc-v31.pdf>. [TEL] Homepage of the TEL project: <http://www.europeanlibrary.org>. [TEL portal] TEL SRU portal <http://krait.kb.nl/coop/tel/portal>. [Z39.50] Z39.50 Maintenance Agency Page, Library of Congress, <http://www.loc.gov/z3950/agency/>. [Z-gateway] British Library website describing the Z39.50/SRU Gateway. <http://herbie.bl.uk:9080>. [ZiNG] Z39.50 international next Generation <http://www.loc.gov./z3950/agency/zing/>. Copyright © 2004 Theo van Veen and Bill Oldroyd |
||||
| |
||||
|
Top | Contents | ||||
| | ||||
|
D-Lib Magazine Access Terms and Conditions DOI: 10.1045/february2004-vanveen
|

{kind=link}
{kind=link}
{kind=link}