|
Search | Back Issues | Author Index | Title Index | Contents |
![]()
D-Lib Magazine
|
|
|
Edward T. O'Neill,
<oneill@oclc.org> |
![]()
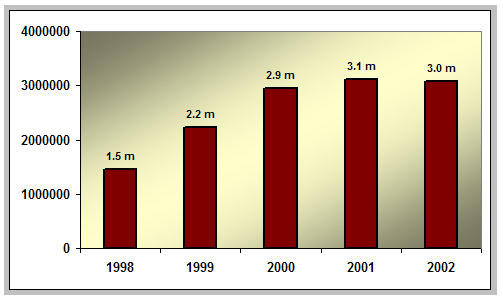
IntroductionThe swiftness of the World Wide Web's ascension from obscure experiment to cultural icon has been truly remarkable. In the space of less than a decade, the Web has extended into nearly every facet of society, from commerce to education; it is employed in a variety of uses, from scholarly research to casual browsing. Like other transformational technologies that preceded it, the Web has spawned (and consumed) vast fortunes. The recent "dot-com bust" was a sobering indication to organizations of all descriptions that the nature and extent of the Web's impact is still unsettled. Although the Web is still a work in progress, it has accumulated enough of a history to permit meaningful analysis of the trends characterizing its evolution. The Web's relatively brief history has been steeped in predictions about the direction of its future development, as well as the role it will ultimately play as a communications medium for information in digital form. In light of the persistent uncertainty that attends the maturation of the Web, it is useful to examine some of the Web's key trends to date, in order both to mark the current status of the Web's progression and to inform new predictions about future developments. This article examines three key trends in the development of the public Web — size and growth, internationalization, and metadata usage — based on data from the OCLC Office of Research Web Characterization Project [1], an initiative that explores fundamental questions about the Web and its content through a series of Web samples conducted annually since 1998. II. Characterizing the Public WebIn 1997, the OCLC Office of Research initiated a project aimed at answering fundamental questions about the Web: e.g., how big is it? what does it contain? how is it evolving? The project's objective was to develop and implement a methodology for characterizing the size, structure, and content of the Web, making the results available to both the library community and the public at large. The strategy adopted for characterizing the Web [2] was to harvest a representative sample of Web sites, and use this sample as the basis for calculating estimates and making inferences about the Web as a whole. Using a specially configured random number generator, a 0.1% random sample of IP (Internet Protocol) addresses was taken from the IPv4 (32-bit) address space. For each of these IP addresses, an HTTP connection attempt was made on Port 80, the standard port for Web services. An IP address identified a Web site if it returned an HTTP response code of 200 and a document in response to the connection attempt. Each Web site identified in the sample was harvested using software developed at OCLC. Following the collection of the Web sites, several diagnostic tests were applied to identify sites duplicated at multiple IP addresses. This yielded an estimate of the total number of unique Web sites. Finally, the set of unique Web sites from the sample was analyzed to identify public Web sites. A public Web site offers to all Web users free, unrestricted access to a significant portion of its content. Public Web sites may also contain restricted portions, but in order for the site to be considered public, a non-trivial amount of unrestricted content must be available as well. Completion of this analysis yielded a representative sample of unique public Web sites. The set of all public Web sites is called the public Web. It is this portion of the Web that is the most visible and readily accessible to the average Web user. The public Web is the focus of the analysis and discussion in this paper. After a pilot survey in 1997, the project conducted five consecutive surveys (1998 - 2002) of the Web, based on the sampling methodology described above. III. Size and GrowthAccording to the results of the Web Characterization Project's most recent survey, the public Web, as of June 2002, contained 3,080,000 Web sites, or 35 percent of the Web as a whole. Public sites accounted for approximately 1.4 billion Web pages. The average size of a public Web site was 441 pages. Is the public Web remarkable by virtue of its size? By at least one account, the answer is no — Shapiro and Varian [3] recently estimated that the static HTML text on the Web was equivalent to about 1.5 million books. They compared this figure to the number of volumes in the University of California at Berkeley Library (8 million), and, noting that only a fraction of the Web's information can be considered "useful", concluded that "the Web isn't all that impressive as an information resource." But Shapiro and Varian's assessment seems harsh. The Web encompasses digital resources of many varieties beyond plain text, often combined and re-combined into complex multi-media information objects. To assess the Web's size based solely on static text is to ignore much of the information on the Web. Furthermore, many Web analysts now recognize the distinction between the "surface Web" and the "deep Web". While this terminology suffers from different shades of meaning in different contexts, the surface Web can be interpreted as the portion of the Web that is accessible using traditional crawling technologies based on link-to-link traversal of Web content. This approach is used by most search engines in generating their indexes. The deep Web, on the other hand, consists of information that is inaccessible to link-based Web crawlers: in particular, dynamically-generated pages created in response to an interaction between site and user. For example, online databases that generate pages based on query parameters would be considered part of the deep Web. Although an authoritative estimate of the size of the deep Web is not available, it is believed to be large and growing [4]. In another study, Varian and Lyman [5] estimate that in 2000, the surface Web accounted for between 25 - 50 terabytes of information, based on the assumption that the average size of a Web page is between 10 and 20 kilobytes. However, Varian and Lyman make no distinction between public and other types of Web sites. Combining their estimate with results from the 2000 Web Characterization Project survey, and assuming that Web sites of all types are, on average, the same size in terms of number of pages, 41 percent of the surface Web, or between 10 - 20 terabytes, belonged to the public Web in 2000. In comparison, the surface Web in 2002 accounted for 14 - 28 terabytes (combining the page count from the Web Characterization Project's 2002 survey with an average Web page size of between 10 - 20 KBs). Varian and Lyman estimate that a 300-page, plain text book would account for 1 MB of storage space. This in turn implies that as of June 2002, the information on the surface Web was roughly equivalent in size to between 14 and 28 million books. This would seem to suggest that the Web is indeed an information collection of significant proportions: consider that in 2001, the average number of volumes held by the 112 Association of Research Libraries (ARL)-member university libraries [6] was approximately 3.7 million. The largest number of volumes, held by Harvard University, was just under 15 million. The conclusion, however, that the Web is equivalent, or perhaps even surpasses, the largest library collections is probably unwarranted. A significant percentage of the surface Web is taken up by "format overhead" — for example, HTML or XML tagging. In addition, Shapiro and Varian's point that a significant portion of the information on the Web is not generally useful cannot be dismissed lightly. What is probably most remarkable about the size of the Web is how rapidly it rose from relatively insignificant proportions to a scale at least comparable to that of research library collections. A widely-cited estimate [7] placed the size of the Web as a whole in 1996 at about 100,000 sites. Two years later, the Web Characterization Project's first annual survey estimated the size of the public Web alone to be nearly 1.5 million sites. By 2000, the public Web had expanded to 2.9 million sites, and two years later, in 2002, to over 3 million sites. In the five years spanning the series of Web Characterization Project surveys (1998 - 2002), the public Web more than doubled in size.
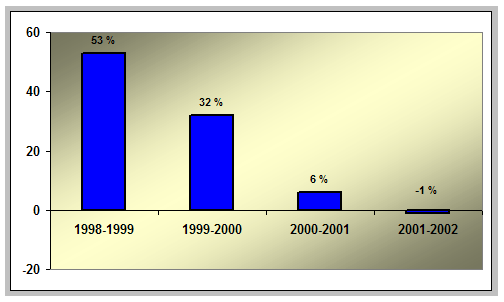
But this impressive overall growth masks an important trend: that the public Web's rate of growth has been slowing steadily over the five-year period covered by the Web Characterization Project surveys. Examination of year-on-year growth rates (measured in terms of the number of Web sites) for the period 1998 - 2002 reveals this decline: between 1998 and 1999, the public Web expanded by more than 50 percent; between 2000 and 2001, the growth rate had dropped to only 6 percent, and between 2001 and 2002, the public Web actually shrank slightly in size. Most of the growth in the public Web observed during the five years covered by the surveys occurred in the first three years of the survey (1998 - 2000). In 1998, the public Web was a little less than half its size in 2002; by 2000, however, it was about 96 percent of its size in 2002.
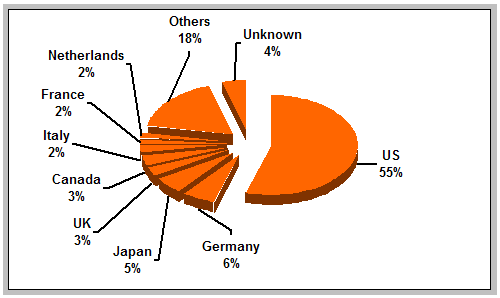
The slowdown in growth of the public Web is even more dramatically evident in absolute terms. Between 1998 and 1999, the public Web exhibited a net growth of 772,000 sites; a similar number (713,000) were added between 1999 and 2000. After this point, however, absolute growth dropped off precipitously: between 2000 and 2001, only 177,000 new public Web sites were added, and between 2001 and 2002, the public Web shrank by 39,000 sites. The evidence suggests, then, that the public Web's growth has stagnated, if not ceased altogether. What factors can explain this? One key reason is simply that the Web is no longer a new technology: those who wish to establish a Web presence likely have already done so. In this sense, the rush to "get online" witnessed during the Web's early years has likely been replaced with a desire to refine and develop existing Web sites. Indeed, estimates from the Web Characterization Project's June 2002 data suggest that while the public Web, in terms of number of sites, is getting smaller, public Web sites themselves are getting larger. In 2001, the average number of pages per public site was 413; in 2002, that number had increased to 441. In addition to a slower rate of new site creation, the rate at which existing sites disappear may have increased. Analysis of the 2001 and 2002 Web sample data suggests that as much as 17 percent of the public Web sites that existed in 2001 had ceased to exist by 2002. Many of those who created Web sites in the past have apparently determined that continuing to maintain the sites is no longer worthwhile. Economics is one motivating factor for this: the "dot-com bust" resulted in many Internet-related firms going out of business; other companies scaled back or even eliminated their Web-based operations [8]. Other analysts note a decline in Web sites maintained by private individuals — the so-called "personal" Web sites. Some attribute this decline to the fact that many free-of-charge Web hosting agreements are now expiring, and individuals are unwilling to pay fees in order to maintain their site [9]. In sum, the dual effect of fewer entities creating Web sites, combined with entities discontinuing or abandoning existing Web sites, combine to dampen the public Web's rate of growth. This, of course, is not to say that the public Web is definitively shrinking: by other measures, e.g., the number of pages, or number of terabytes, it may in fact be growing. But in terms of the number of Web sites, which is roughly equivalent to the number of individuals, organizations, and business entities currently maintaining a presence on the Web in the form of a public site, the numbers suggest that growth in the public Web, at least for the time being, has reached a plateau. IV. InternationalizationAs its name suggests, the World Wide Web is a global information resource in the sense that anyone, regardless of country or language, is free to make information available in this space. Ideally, then, the Web's content should reflect the international community at large, originating from sources all over the world, and expressed in a broad range of languages. In 1999, the second year of the Web Characterization Project survey, the public Web sites identified in the sample were traced back to entities — individuals, organizations, or business concerns — located in 76 different countries, suggesting that the Web's content at that time was fairly inclusive in terms of the global community. A closer examination of the data, however, belies this conclusion. In fact, approximately half of all public Web sites were associated with entities located in the United States. No other country accounted for more than 5 percent of public Web sites, and only eight countries, apart from the US, accounted for more than 1 percent. Clearly, in 1999, the Web was a US-centric information space.
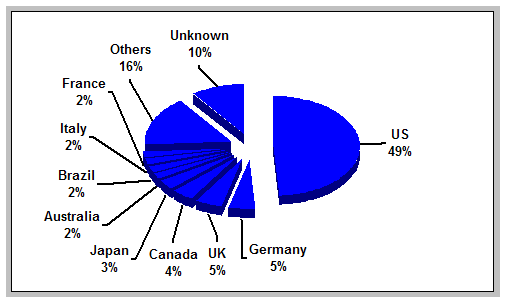
Three years later, little has changed. The proportion of public Web sites originating from US sources actually increased slightly in 2002, to 55 percent, while the proportions accounted for by the other leading countries remain roughly the same. In 2002, as in 1999, the sample contained public sites originating from a total of 76 countries. These results suggest that the Web is not exhibiting any discernable trend toward greater internationalization.
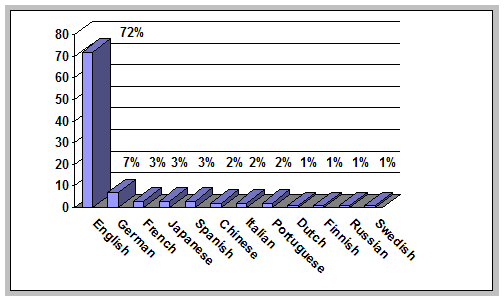
This conclusion is reinforced when the language of textual content is considered. Given the fact that more than half of all public sites originate from US sources, it is easy to predict that English is the most prevalent language on the Web. But to what degree does this dominance extend? How has it evolved over time? Examination of the 1999 and 2002 Web Characterization Project survey data provides insight into these questions. In 1999, 29 different languages were identified among the sample of public Web sites included in the survey, which, taken at face value, suggests that the Web's text-based content is fairly diverse in terms of the languages in which it is expressed. But, as with the geographical origins of public Web sites, the raw total of languages represented in the public Web overstates the degree of internationalization actually achieved. Data from 1999 indicate that nearly three-quarters of all public Web sites expressed a significant portion of their textual content in English. The next most frequently encountered language was German, which appeared on about 7 percent of the sites. Only seven languages, apart from English, were represented on 2 percent or more of the public Web sites identified in the survey.
Not all sites represent their textual content in a single language: in 1999, for example, 7 percent of the public Web sites identified in the sample presented textual content in multiple languages. Interestingly, however, in each instance where textual content was offered in more than one language, English was, without exception, one of the choices. Just as with the geographical origins of public Web sites, the distribution of textual content across languages appears to have changed little between 1999 and 2002. The percentage of public sites offering a significant portion of their content in English remained steady at nearly three-quarters; no other language exceeded 7 percent. The percentage of multilingual sites decreased slightly, from 7 to 5 percent. Perhaps the most significant change is the increase in the number of sites offering content in Japanese: this percentage increased from 3 to 6 percent between 1999 and 2002. This result, combined with the fact that the percentage of sites available from Japanese sources increased from 3 to 5 percent during the same period, suggests that the Japanese presence on the Web has perceptibly expanded over the past few years.
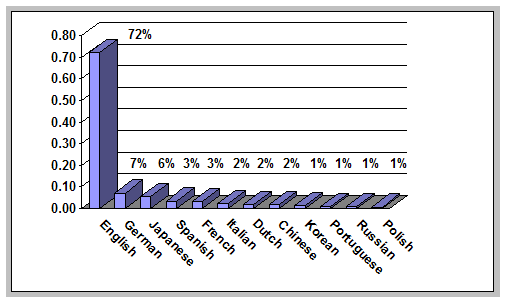
Library collections offer a point of comparison for the distribution of languages found on the Web. Comparison of the Web to a single library collection is problematic, because the latter reflects a collection development strategy unique to a single institution. However, comparison of the Web to an aggregation of many library collections will tend to average out the idiosyncratic features of particular collections, offering a more meaningful comparison to the Web. WorldCat® (the OCLC Online Union Catalog) is the world's largest bibliographic utility, representing content held by libraries all over the world, but predominantly from the US. As of July 2001, WorldCat contained about 45 million bibliographic records [10]. Of these, about 63 percent were associated with English-language content. German and French were the next most common languages, at 6 percent each; Spanish was 4 percent, and Chinese, Japanese, Russian, and Italian were each 2 percent. All other languages were 1 percent or less. This distribution is very similar to that of public Web sites, both in terms of the shape of the distribution (heavily skewed toward English, then immediately dropping off to a long, thin tail), as well as the relative frequency ranking of languages. This suggests that the Web and library collections exhibit roughly the same degree of internationalization in terms of language of textual content. V. Metadata UsageLibraries serve as more than just repositories of information. In addition, the information is organized and indexed to facilitate searching and retrieval. A complaint that has often been made about the Web is that it lacks this organization. Searching is done using "brute force" methods such as keyword indexing, often without context or additional search criteria. Some improvements have been made from the earliest days of the Web: the search engine Google, for example, employs relatively sophisticated algorithms that rank search results based on linkage patterns and popularity. Librarians achieve their organization through the careful preparation and maintenance of bibliographic data — i.e., descriptive information about the resources in their collections. More generally, this descriptive information is called metadata, or "data about data". A movement has been underway for some time to introduce metadata into the Web, most notably through the Dublin Core Metadata Initiative [11]. Has any significant progress been made in this regard? Metadata for Web resources is typically implemented with the META tag, which can be used by creators to embed any information deemed relevant for describing the resource. The META tag consists of two primary components: NAME, which identifies a particular piece of metadata (keyword, author, etc.) and CONTENT, which instantiates, or provides a value for, the metadata element identified in the NAME attribute. Using the data from all five Web Characterization Project surveys, it was possible to examine trends in metadata usage on the public Web over the past five years. The purpose of the analysis was simply to detect the presence of any form of metadata, implemented using the META tag, on public Web sites. Analyzing the public sites collected in the samples between 1998 and 2002 revealed several important characteristics about metadata usage on the Web. First, it seems clear that metadata usage is on the rise: steady increases in the percent of public Web sites containing metadata on the home page (where metadata usage is most common) are observed throughout the five-year period. Similar increases were observed in the percentage of all Web pages harvested from public sites that contained some form of metadata. One caveat should be mentioned, however: with the advent of more sophisticated HTML editors, some META tags are created and populated automatically as part of the document template. It is likely that this accounts for at least part of the perceived increase in META tag usage on public Web sites. A second interesting feature about metadata usage on the Web is that, apparently, it is not becoming more detailed. If it is assumed that one META tag is equivalent to one metadata element, or piece of descriptive information about the Web resource, then it is clear that, on average, Web pages that include metadata contain about two or three elements. Clearly, there is no widespread movement to include detailed description of Web resources on the public Web.
A discouraging aspect of metadata usage trends on the public Web over the last five years is the seeming reluctance of content creators to adopt formal metadata schemes with which to describe their documents. For example, Dublin Core metadata appeared on only 0.5 percent of public Web site home pages in 1998; that figure increased almost imperceptibly to 0.7 percent in 2002. The vast majority of metadata provided on the public Web is ad hoc in its creation, unstructured by any formal metadata scheme. VI. ConclusionIn this paper, three key trends in the evolution of the public Web over the last five years were examined, based on five annual surveys conducted by OCLC's Web Characterization Project. The results of these surveys indicate that the public Web is an information collection of significant proportions, exhibiting a remarkable pattern of growth in its short history. But evidence suggests that growth in the public Web, measured by the number of Web sites, has reached a plateau. The annual rate of growth of the public Web has slowed steadily throughout the five-year period covered by the Web Characterization Project surveys; over the last year, the public Web shrank slightly in size. A second trend concerned the internationalization of the public Web. The Web has been positioned as a global information resource, but analysis indicates that the public Web is dominated by content supplied by entities originating in the US. Furthermore, the vast majority of the textual portion of this content is in English. There are no signs that this US-centric, English-dominated distribution of content is shifting toward a more globalized character. Finally, examination of metadata usage on the public Web over the five-year span of the Web Characterization Project surveys indicates that little if any progress is being made to effectively describe Web-accessible resources, with predictable results for ease of search and retrieval. Although metadata usage (via the HTML META tag) is common, the metadata itself is created largely in an ad hoc fashion. There is no discernable trend toward adoption of formal metadata schemes for public Web resources. As we consider the current status of the Web's evolution, and speculate on its future progression, the trends described in this paper suggest that the public Web may have reached a watershed in its maturation process. The rush to get online is, at least for the time being, over, evidenced by the plateau in the growth of the public Web. Maintaining a Web presence has become a routine, and in many cases, necessary activity for organizations of all descriptions. But the public Web clearly has some distance yet to go to reach its full potential, a point corroborated by the two other trends examined in this paper. The ubiquity of the public Web in other parts of the world has not reached the level realized in the United States. Also, while we have become extremely proficient at making information available on the public Web, progress in terms of making that information more organized and "findable" has been comparatively limited. The past five years have witnessed extraordinary validation of the Web as "proof of concept". Hopefully, the next five years will witness equally remarkable progress in fine-tuning the Web to enhance both the scope of its users, and the utility of its content. Notes and References[1] For more information about the Web Characterization Project, please visit the project Web site at <http://wcp.oclc.org/>. [2] For more information about the Web sampling methodology, please see "A Methodology for Sampling the World Wide Web". Available at <http://www.oclc.org/research/publications/arr/1997/oneill/o%27neillar980213.htm>. [3] Shapiro, C. and H. Varian (1998). Information Rules: A Strategic Guide to the Network Economy, (Harvard Business School Press, Cambridge) [4] Bergman, M. (2001). "The Deep Web: Surfacing Hidden Value" Journal of Electronic Publishing, Volume 7, Issue 1. Available at <http://www.press.umich.edu/jep/07-01/bergman.html>. [5] Information on this study, "How Much Information?", along with the study's findings, are available on the project Web site: <http://www.sims.berkeley.edu/research/projects/how-much-info/>. [6] All ARL-member statistics were obtained at the ARL Statistics and Measurement Program Web site at <http://www.arl.org/stats/index.html>. [7] Statistics from Gray, M., "Web Growth Summary". Available at <http://www.mit.edu/people/mkgray/net/web-growth-summary.html>. [8] Kane, M. (2002). "Web Hosting: Only the Strong Survive" ZDNet News. Available at <http://zdnet.com.com/2100-1105-938347.html>. [9] Mariano, G. (2002). "The Incredible Shrinking Internet" ZDNet UK News. Available at <http://news.zdnet.co.uk/story/0,,t269-s2101890,00.html>. [10] WorldCat statistics were obtained from the OCLC Annual Report 2000/2001. The report is available at <http://www.oclc.org/about/annualreport/2001.pdf>. [11] For more information about the Dublin Core Metadata Initiative, please visit the DCMI Web site at <http://dublincore.org/>. Copyright ©
OCLC Online Computer Library Center. Used with permission.
|
|||||||||||||||||||||||||||||||||||||||||||
| |
|||||||||||||||||||||||||||||||||||||||||||
|
Top | Contents | |||||||||||||||||||||||||||||||||||||||||||
| | |||||||||||||||||||||||||||||||||||||||||||
|
D-Lib Magazine Access Terms and Conditions DOI: 10.1045/april2003-lavoie
|
|||||||||||||||||||||||||||||||||||||||||||