
Data Distribution Over the Web
In the last year, many Web surfers interested in VRML (Virtual Reality Modeling Language) files have found themselves visiting the NCSA Astronomy Digital Image Library (ADIL) [1] to view 3-D visualizations [2] of a galaxy or an interstellar cloud. Others, perhaps looking for images of the Milky Way, have caught a glimpse of what the center of our galaxy [3] looks like in radio waves. It would seem that a such an image-ready medium like the World Wide Web would be a perfect fit for such an image-oriented field as astronomy. Indeed, judging from the public response to the ADIL and related astronomy resources (such as the hugely popular Mars Pathfinder site from NASA [4] and public gallery from the Hubble Space Telescope [5]), the Web has proved to be extremely successful in distributing science to the general public. The Web, of course, has also been important for distributing that same science throughout the scientific community as well; however, making the network an effective tool for scientists through the distribution of research-quality data presents a number of challenges.
The NCSA Astronomy Digital Image Library was developed with support from NASA and the National Science Foundation to address some of the challenges of distributing scientific data over the network. Its specific mission is to collect fully processed astronomical images in FITS format (a standard astronomical image format [6]) and make them available to the research community and the interested public via the World Wide Web. The research component itself has two sides, which I will discuss in this story: on the one side, the ADIL allows users to search, browse, and download astronomical images. This can be non-trivial when the images are not in the usual GIF or JPEG formats. On the other side, the ADIL provides researchers with a place to archive and share their fully-processed images with the community by allowing them to add the images to the Library's collection.
ADIL can be thought of as a place to search for and store data. But it is also a tool that strives to work at a high conceptual level, providing a bridge between data and astronomical ideas. This is accomplished in part through links between the images and other electronic data including, in particular, scientific literature. In fact, today, the majority of current refereed journal literature is available on-line, either as abstracts or full articles. Interconnecting astronomical resources on the network has been the topic of considerable effort within the community which I will discuss in a follow-up story (to appear in the February 1998 issue of D-Lib). With such connections to the scientific literature, the ADIL can be more than just a repository for astronomical images; it can be a part of the presentation of scientific results. Astronomers can now publish scientific data to a level not previously possible. In this way, we hope that the ADIL and resources like it will change the way astronomers do research.
Many of the complications of running a scientific data library trace back to two characteristics of the basic data items being serverd: the item's file type and size. The ADIL stores and distributes its images in FITS format, which is not a file type generally supported by the Web. Why not use GIF or JPEG? To understand why these formats are not appropriate for scientific data, consider the difference between scientific images and the usual sort of images one finds on the network.
The biggest difference is that, to a scientist, an image is multi-dimensional, regularly-sampled array of measurements. This means first of all that the image is not restricted to two (or even three) dimensions. Second, the value at each pixel represents a scientific measurement or quantity, such as brightness, temperature, or magnetic field strength. The value could be an integer or floating-point number or something more complex. In contrast, the value in GIF pixel is an index into some color table. A scientific image often contains no notion of color. The application of a color table to a scientific images is usually applied only during visualization. The visualization process usually causes a loss of information in the image (e.g. one might only have 256 colors) in order to highlight some particular feature of the data.
The other important feature of a scientific image is its associated metadata. The metadata are the ancillary data needed to properly interpret the basic image data. They include basic information like the number of dimensions in the image, image size, and data type contained in each pixel which allow the data to be read in properly by application programs. They also include information necessary to properly analyze the data. For an astronomical image, the metadata might include information like the telescope used, the observing frequency, the position in the sky, and the name of the object in the image. Such information plays an important role when searching for and browsing images in a library. Thus, a scientific format must not only be able to support a scientist's notion of an image, it must also be able to store necessary metadata needed to handle that image.
The other important concern for handling scientific data is the size of the individual data items. There is no restriction on how big a FITS file can be, and in practice, they can be between a few hundred kilobytes to several hundreds of megabytes in size. Downloading such files through today's Internet is a slow operation; therefore, the data library must have effective ways of browsing the data -- that is, finding out what's in the data without downloading it all.
For web surfers, the ADIL home page [1] provides links to various highlights of the Library's contents. An astronomer visiting the ADIL, however, normally would first go to the Library's Query Page [7]. This HTML form allows the user to search for images using a variety of criteria, including:
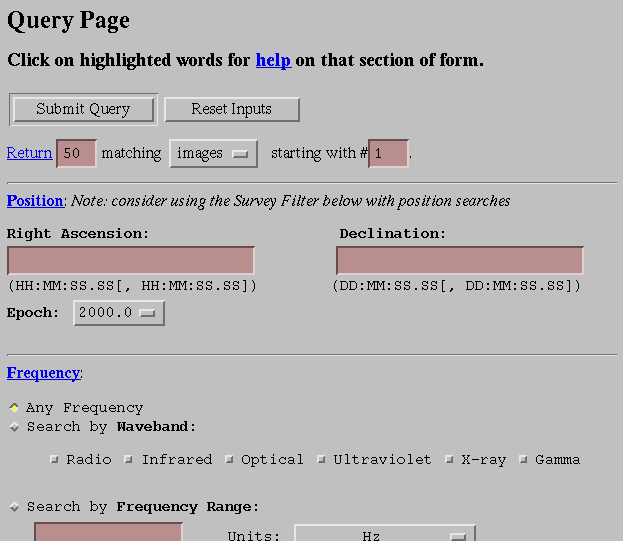
|
| Figure 1. An excerpt from the ADIL Query Page. |
As an example, the user could enter "supernova" in the "Object Type" box and press the "Submit Query" button, and a list of matching images would appear in a Results Page. For each image, the page lists some of the metadata associated with the image so that the user gets some idea of what the image contains. From this page, the user can download any of the matched images; however, most users would browse the images by clicking on the links to their Preview Pages.
The purpose of the Preview page is to give as much information as possible so that the users can determine what is in the image and whether they should download it for further analysis. This is done through the formatted presentation of the image metadata, a preview image, and links to further information. For example, a typical Preview Page contains the title and authors and a digest of the image header (see Figure 2). The preview image is a visualization of the FITS image in GIF format. Often, the image is subsampled to allow it to be downloaded quickly. If the FITS image has more than two dimensions, a typical 2-D subimage is chosen for previewing. There are links for further browsing of related data, including an abstract and the full FITS header. If the image does have more than two dimensions, there is a link to a "Movie Page" which allows the user to browse other 2D frames from the image.

|
| Figure 2. An excerpt from a sample Preview Page [8]. This page contains preview information about the image as well as links to other information. Note the link just below the preview image labeled "Reference"; this anchor links the image to the related journal abstract. |
One important link found on the preview page (located just the preview image) is labeled "Reference". This is a link to the abstract in a related published article. These abstracts are provided by another astronomical data provider, the NASA Astrophysics Data System (ADS) [9]. This link helps facilitate the connection between the data and the science it represents. In cooperation with the ADIL, the ADS provides similar links between the abstracts and related data in the ADIL. Thus, users browsing abstracts at the ADS site can easily access the data that went into that article stored in the ADIL.
It is interesting to note that many of the astronomical data providers available on the network have similar schemes for searching and browsing data. However, the details of the data access differ greatly because they are tailored to the particular data type they serve. Thus, it is difficult to find all the information available everywhere about "supernova"; currently, one must visit each site and use their interface to conduct a search. Efforts are underway to address this problem which I will discuss in the follow-up article.
The standard ADIL scheme for browsing is a kind of server-side browsing. In this type of browsing, the server filters the data and its metadata into a presentation in HTML format. The ADIL has been exploring other techniques for browsing its contents. One technique is the use of imagemaps for "visually searching" through a collection of images. For example, the Library contains a survey of molecular gas in the Milky Way Galaxy made up of 720 images. To browse this collection, the user can access the survey's Project Page [10]. The image shown there represents the entire portion of the sky covered by the survey. By clicking on a location in the image map, one can get a list of nearby images.
The advent of Java allows us to explore techniques for client-side browsing. As an example, we have developed a Java Applet for browsing large images in the Library [11]. This applet presents two views: a subsampled view of the image on the left and a "zoomed" image on the right. The zoomed view can be updated by clicking on locations in the subsampled view. The applet also tracks coordinate positions as the user moves the mouse over the image. From our explorations of Java, we have found a number of operations that are common to browsing all kinds of scientific images. This has led to a project at NCSA to develop a package of reusable Java classes for browsing scientific images. This package, called the Horizon Image Data Browser Package [12] is currently available as an alpha release. A production release is expected by Summer 1998.
The ADIL has also been exploring VRML as a way of browsing images. As a 3-D equivalent to a GIF image, VRML can be used to create static visualizations of 3D images. The Library contains a number of VRML visualizations [2]. In addition, we are now testing a VRML Server [13] that allows users to create their own 3D visualizations of images in the ADIL.
Adding to the Library's Collection
The ADIL is more than a tool for astronomers looking for images to augment their research. It is also useful for authors who wish to share their images with the community. While many of the Library's images come from observatories, the core of the collection comes from individual authors. The ADIL provides a way to upload the images to the Library, along with any supporting data, where it can be processed and made available to the Library users.
Authors deposit images into the Library in the form of collections we refer to as "projects". Normally, an author would make a deposit at the end of some scientific study when the resulting publication is going to press; all the fully processed images associated with that paper would make up the project. The main requirements for making a deposit are:
In addition to the FITS images, the author can also include other kinds of data files related to the project. This could include table data or special visualizations of the data, such as GIF images, PostScript figures, animations, or VRML renderings.
When the author is ready to deposit, he or she first fills out an on-line submission form. Then, the author may either manually FTP the files to the ADIL anonymous FTP server or, if running on a UNIX platform, can download a customized script that uploads all the files automatically.
When a project is processed and placed on the Library's "shelves", it
is given a unique codename (e.g. 95.RP.01 for
the first project deposited by Raymond Plante in 1995). When this
codename is appended to a standard URL base (e.g.
http://imagelib.ncsa.uiuc.edu/document/95.RP.01), the
corresponding Project Page can be accessed directly. Items within the
project also have codenames (e.g. 95.RP.01.02 for the second image in
that project). Thus, every item in the library can be accessed via a
unique URL. We encourage authors to cite these URLs in their
published articles. For example, one might refer to an animation
sequence that illustrates a feature of the data that cannot be
conveyed as well with traditional 2D visualizations.
Behind the Desk: the Library Backend
For more information about what goes on "behind the desk" at the ADIL, consult the "Overview of the ADIL System" [14]. In summary, when an author makes a deposit to the Library, a collection of programs, the "Electronic Librarian", engages to process the deposit. Metadata are extracted from FITS files and the inputs from the submission form and loaded into the database system (PostgreSQL) used for searching for images. The files are then archived in long term storage and moved to the "Library Shelves", making them available over the Web. Although this process is largely automated, the Human Librarian still plays an important role. The metadata, which allow the image to be located in a search, are not always contained in the FITS file or the submission form filled out by the user. The metadata that can be extracted might also be inaccurate. The human, therefore, is important for catching typos and making sure the metadata that get loaded into the database make sense.
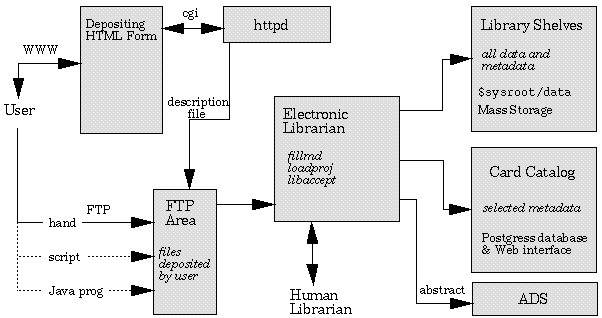
|
| Figure 3. Data Flowing into the Library. Authors use FTP and the Web to deposit data and related information into the Library. Metadata for a searchable database is extracted, and the data is moved to storage. |
The ADIL storage model employs primary, secondary, and tertiary storage to hold the data. The primary storage are locally mounted hard drives containing the database, metadata used for constructing Preview Pages on-the-fly, and GIF preview images. These are kept on disk all the time for immediate user access. The secondary storage is comprised of fourteen gigabytes of local disk operated as a cache and which is used to store the actual FITS images. If the user downloads an image, the system first looks for it in the cache; if it is not there, it is automatically transferred from the tertiary (long-term) storage and delivered to the user. The cache's purging policy is designed to remove the largest files that have not been accessed recently first.
The ADIL uses the NCSA Mass Storage System (MSS) for its tertiary, long-term storage. This system is based on a bank of fast IBM Magstar tape drives (loaded by a robotic juke box) and more than 285 Gigabytes of its own disk cache. The drives feature a data rate of 9 Megabytes/second, and they can seek to any position in their 10-Gigabyte tapes in less than 60 seconds. The MSS is connected to the ADIL server with an FDDI network connection providing 100 Megabits/second transfer rates. Because of the cache's purging policy, transfer from MSS usually happens for only the larger images. Given the performance of the MSS, the bottleneck during the download of a large file to a remote workstation is almost always the Internet itself.
Data Archiving and Data Publishing
Prior to the Web and the ADIL, sharing data with one's colleagues was a difficult task. If an astronomer needed copy of someone else's data, he would have to contact the author of the data directly. Unless the author had been working with the data recently, she might have to go to considerable effort to locate the data on tape, make a copy, and then send it to the colleague who made the request. Given the effort necessary, there was a good chance that the data would not get transferred in a timely period--if at all.
Today, there are a number of centers distributing data over the network, including image data. Some serve as archives for raw or unprocessed data (such as the ASCA X-ray Telescope archive [15]) while others serve data that are essentially fully processed and ready for analysis. An example of the latter is the NASA SkyView archive [16] which serves data from a number of large survey projects. It is important to note that it is not the goal ADIL to mirror data that is available from other (permanent) archives. Such archives are usually associated with large observatories or projects (such as NASA space observing missions) which can afford to include data repository as part of the overall mission. However, many images that produce published results come from smaller observatories that do not have publicly available archives. A resource like the ADIL is particularly important to astronomers conducting smaller-scale surveys, such as a recent chemical study of the Taurus Molecular cloud which includes images of over 20 different chemical species [17]. Such comprehensive projects can form the cornerstone of many future studies as long as the data can be effectively distributed.
The availability of a variety of astronomical data on-line is already beginning to affect the way astronomers do research. At this time, the ADIL contains about 5,000 images representing over 13 gigabytes of data. These numbers are small compare to the library's capacity as well as its potential as a research tool; however, as the collection grows, the power of the Library will become more apparent. With a large variety of data available, astronomers can carry out multi-frequency studies of objects or a class of objects, comparing previously observed data with new data. Many questions in science can only be effectively addressed when a large amount of data exists, spanning many different objects, positions in the sky, or frequency bands. Previous observations are also very valuable in planning new projects.
The unique URLs for ADIL items provide a way to link the data to other information on the Web including the scientific literature. Transparent links between the literature and the data serve to pull the data into the publishing process. We envision a major shift in the norms of publishing in which data is published at same time as a refereed article.
This future, of course, requires a cultural change within the community. Admittedly, many scientists might feel overly exposed to scrutiny if their images were available in an analyzable format. Some are concerned that publishing the data might "give away" research they might do in the future. Such concerns may never go away, preventing some data from ever becoming public. Nevertheless, astronomers are becoming more accustomed to having easy access to data. I, therefore, see that having one's images available on-line will help promote the scientific results they produced, because other researchers that make use of the images are obligated to cite the previous work. In the end, a resource like the ADIL helps to complete the loop of scientific investigation: easy access to previous data makes it easier pose new questions and initiate new studies.
Roberts, D.A. and Goss, W.M. 1995. Multiconfiguration VLA H92alpha Observations of Sgr A West at 1 arcsec Resolution (http://imagelib.ncsa.uiuc.edu/document/95.DR.01).



hdl:cnri.dlib/october97-plante