|
|
|
| P R I N T E R - F R I E N D L Y F O R M A T | Return to Article |
D-Lib Magazine
November/December 2015
Volume 21, Number 11/12
Efficient Table Annotation for Digital Articles
Matthias Frey
Graz University of Technology, Austria
freym@sbox.tugraz.at
Roman Kern
Know-Center GmbH, Austria
rkern@know-center.at
DOI: 10.1045/november2015-frey
Abstract
Table recognition and table extraction are important tasks in information extraction, especially in the domain of scholarly communication. In this domain tables are commonplace and contain valuable information. Many different automatic approaches for table recognition and extraction exist. Common to many of these approaches is the need for ground truth datasets, to train algorithms or to evaluate the results. In this paper we present the PDF Table Annotator, a web based tool for annotating elements and regions in PDF documents, in particular tables. The annotated data is intended to serve as a ground truth useful to machine learning algorithms for detecting table regions and table structure. To make the task of manual table annotation as convenient as possible, the tool is designed to allow an efficient annotation process that may spawn multiple session by multiple users. An evaluation is conducted where we compare our tool to three alternative ways of creating ground truth of tables in documents. Here we found that our tool overall provides an efficient and convenient way to annotate tables. In addition, our tool is particularly suitable for complex table structures, where it provided the lowest annotation time and the highest accuracy. Furthermore, our tool allows annotating tables following a logical or a functional model. Given that using our tool, ground truth datasets for table recognition and extraction are easier to produce, the quality of automatic tables extraction should greatly benefit.
Keywords: Table Recognition, Document Analysis, Unsupervised Learning, PDF Extraction, Text Mining
1 Introduction
In the field of information extraction, the detection and extraction of tables play an important role. Especially, complex table layouts are still a big challenge for automatic approaches. For example, a table may contain nested sub tables or various kinds of row and column spawns. Such tables are a common means of communication within scientific publications, due to the compactness of the presented information. For example in the biomedical domain, tables that spawn pages with a complex structure, which is hard to decipher even for humans are common. Today, scientific publications typically are available only as PDF documents, where individual characters are plotted onto a page. Information about the table structure is not available.
Automatic table recognition and extraction algorithms often follow a supervised machine learning approach. To train and evaluate these algorithms, a table ground truth is necessary. Such data is not sufficiently available to date, therefore unsupervised methods are primarily used [6, 7]. In this work, a software system named PDF Table Annotator is presented, that enables users to interactively annotate table structures in PDF documents. The primary goal of the application is to speed up and make more convenient an otherwise cumbersome process — that of creating large amounts of suitable ground truth data for training and evaluating table detection algorithms. The annotation tool runs in a standard web browser using the mouse as primary input device. The final annotation can then be exported in a number of formats. The tool itself is made available under an open-source license (Apache 2.0 License).
2 Related Work
Many approaches for automatic tables recognition and extraction have been proposed in literature. An overview of automatic table recognition can be found in [19] and [12]. In [5], a tool called the Wang Notation Tool is described, a semi-automatic tool to generate ontologies from tables. The tool assists in converting tables from HTML pages to Wang- and XML- notation, and further on to a semantic format. Hu et al. [4] published work dedicated to the creation of ground truth table data, mainly for documents in ASCII and TIFF format — a tool named Daffy was designed to create ground truth, with a table model that uses directed acyclic graphs (DAG). In [16], a tool is described that encodes table ground truth as visual information in images for comparison and evaluation, next to an XML format specifying table rows and cells. The tool is designed to only work with images.
In [9], the software system TableSeer is presented alongside a quantitative study on tables in documents and a dataset of PDF documents with ground truth table data (the dataset, however is not directly available). An online extractor allows uploading PDF documents and attempts automatic extraction of tabular data, which can then be downloaded in the CSV format.
Oro et al. [14] describe an approach to table detection in PDF documents and provide a set of 100 documents meant as a standardized dataset for comparison of table recognition and extraction algorithms, however the data does not contain a ground truth for tables.
In [2], Göbel et al. describe evaluation techniques for the tasks of table detection, table structure recognition and functional analysis of tables. An output model for each step is presented, as well a dataset of 59 PDF documents with annotations for table regions and table structure. Furthermore, a tool that allows creating table annotation data and comparing the results of table-detections to that ground-truth has been made available [2].With the Tabula and Okular software systems, tabular data can be extracted semi-automatically and processed further using a spreadsheet application to craft data suitable for evaluating the quality of detection algorithms. Tabula works by having the user select the table region, and from that it extracts the tabular data. The data is displayed in a spreadsheet-like form and can be downloaded as comma- or tab-separated values formats (CSV, TSV). Okular is a PDF reader with functionality for selecting table regions and either doing an automatic detection of the structure, denoting the rows and columns of a table grid manually, or using a combined approach.
The main two tasks of table recognition are table detection and structure recognition. The authors of [19] describe the process in terms of observations, transformations and inferences. In [17], Wang presents a model for tables, which has frequently been reused. Figure 1 shows the often cited example of that model. Wang's model describes the presentational form of a table and uses the concepts cells, columns, rows and blocks.
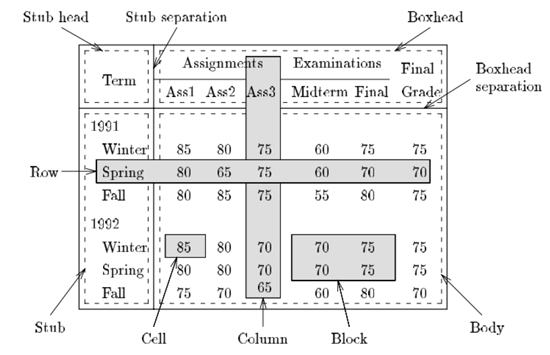
Figure 1: The table presentation model of Wang [17]. Wang uses primarily the terms row, column, cell and block to denote parts of the table. To denote the parts of table that contain headers and labels, the terms stub head and box head are used.
To evaluate an information extraction task, it is necessary to compare the output of the analysis system (the observed variable) to some reference variable (the ground truth), which is the desired output [13]. Besides considering what the size and nature of the sample set should be, the kind of data to be used as reference data needs to be determined. Such data can either be created artificially, or it can be derived from existing documents by adding annotations. For table recognition, reference data will most likely be instances of the table model. The ground truth must use the same formalism as the output of the recognition system. To evaluate, there must exist a metric (binary or continuous, e.g. the editing distance from one model instance to the other).
Common measures in the field of information retrieval and machine learning are precision, recall and the combined F-measure [8, 19]. These were already used in the context of table recognition and extraction to evaluate a number of systems [19, 14, 3].
When comparing systems, it is important to consistently handle errors in scoring a result; fine-grained analysis of errors allows for later re-evaluation and weighting to match metrics used by other research groups for comparison [3].
In the literature, the lack of freely available datasets to evaluate table detection algorithms has been mentioned many times [18, 14, 3, 2, 4, 10, 11]. Efforts to make results of systems comparable have been limited. There is one dataset including PDF documents and a table ground truth that is freely available: the dataset, created by Göbel et al. [2] consists of 59 ground-truthed PDF documents (excerpts) that contain a total of 117 tables. The table data is provided as a domain-generic model, specified in XML Schema Definition (XSD). They omitted excerpts with tables that where considered ambiguous by the ground-truthers.
3 System
This section describes the functionality and usage of the PDF Table Annotator tool.
3.1 Functionality
The software is implemented in two parts: i) a Java based server component and ii) a web-based frontend component. The server is implemented as a Java servlet. The server component parses the documents using the Apache PDFBox library and exposes a webservice to consume and query the data, as well as to submit annotations, which are then stored by the server. The frontend leverages the pdfjs library to display PDF documents within a web browser. Tables, additional information regarding the document and annotations are rendered using plain JavaScript.
Using the web based tool, the user is able to create, view and edit ground truth data regarding tables in PDF documents. The user can enter table region and table structure with a graphical user interface. The contents of PDF documents are displayed, one page at a time, along with any previously added table data as an overlay. The user can add tables by drawing a box to denote the location of the table region; and continue editing the table structure region; and continue editing the table structure by dividing the table region into rows and columns. In the succeeding steps, the resulting cells can be resized and merged, until the table and its cells are correctly aligned with the underlying document page.
Table cells can be tagged as containing data or header information. The data entered by the user is stored and can be edited at a later time. To allow the annotations to be used by different consumers, they can be exported in a number of data exchange formats. In addition, the system is capable of importing table data from files in one of these formats, thus allowing examination, comparison and refinement of externally created table extraction data. The formats that are currently supported are described in Section 3.1.2. Due to its design as client-server architecture the tool is multi-user capable. For carrying out administrative tasks such as importing whole directories of documents, or exporting annotations in bulk, an additional command line interface is provided.
3.1.1 Entering and Editing Table Data
Tables are rendered as an overlay to the document. The table can be moved, and columns and rows can be added to it, if it is in editable mode. To make a table editable it is sufficient for the user to double click on it.
A new table annotation is started by first defining a region, and then slicing up that region into a grid. To begin the process, the user has to click the Add button from the Table section of the main control bar. The user can then press and hold the left mouse button, while moving the mouse, to define the table region. On release, bars — used to define the grid — and Ok and Close buttons are placed next to the table region.
The partitions of the grid can be set by mouse clicks at the desired positions in the bars to the top and left of the table. Figure 2 shows this part of the application's interface.
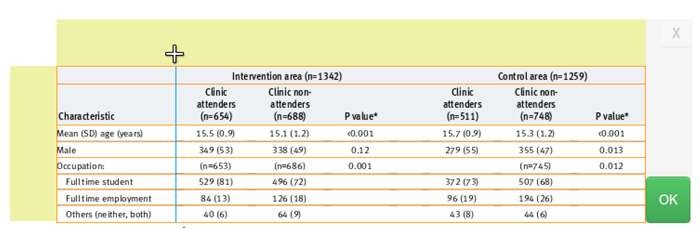
Figure 2: Starting from the previously defined table region, the user sets the position of lines that divide the region into a grid, which will later be the basis for the row and cell structure of the table.
When the table is in edit mode it can be moved as a whole (region) by using the bar on the top of the table as a 'handle'. Furthermore, the table structure can be edited: rows and columns can be added or removed, the dimensions of cells can be changed, cells can be merged and split up again, and cells can be classified (tagged). Those operations are available through the a menu that is visible when a table is being edited.
From the Row/Col section of the menu, options to add or remove rows, columns or cells can be chosen. Add row will add a whole table row (TR) above the position of the (first) selected cell. Similarly add column adds a new column to the table. Remove row and remove cell will remove all rows that contain a selected cell, or all selected cells respectively.
Cells can be resized with a 'click-and-drag' operation at the handle in the corner of a cell; all selected cells will be resized. Selected cells can be merged by choosing the appropriate option from the Merge menu. Before the merging is done, an expansion of the selection is carried out — the smallest rectangular area that contains all selected cells will be merged into one cell. With the options hSplit and vSplit (for 'horizontal' and 'vertical' split), a previous merge operation can be reversed.
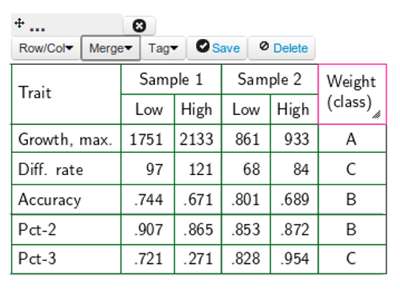
Figure 3: Merging cells to obtain complex table topology.
Lastly, cells can be classified and be given 'tags'. This is done by selecting cells, then choosing the appropriate cell-class from the Tag-menu. The cells will subsequently be displayed in a different color to allow for a visual distinction. Different table models work with different types of cells [17, 15]. The primary benefit is to be able to derive a logical or functional model, by distinguishing header and data cells. By default, the two options available are header- and data-cell.
3.1.2 Supported Models
Two of the formats intended to be used as ground truth for training and evaluation are the models for region and structure described in [2]. To make comparison with arbitrary formats easier, the ability to create another representation of the tables is available as well: an export to CSV format. Here, spanning cells are denoted by empty cells following the spanning cell. This format is also the basis for the accuracy measure used in the evaluation section.
From the table structure and the information about the type of cells, a full functional model can be created. The 'logical' export functionality is an example for such a model: it creates a list of data cells along with their access-path as an unordered set of labels (Figure 4 gives an example of such an export). For some instances of tables, to correctly determine the label hierarchy, more than one class of header cells needs to be defined, as it might otherwise not be clear whether a header (box-head, stub-head) refers to a row or a column. Refining this functional format, and aligning it with other representations such as [17], is left for future work.
|
<document filename ="abc.pdf"> |
The example above is an excerpt of the logical structure export of a table with two dimensions. This table model is related to the abstract table format by Wang [17]. A table consists of a list of values, that contain the actual value (here named 'data') alongside the ancestor cells, named 'dimension'.
4 Evaluation
To assess the usefulness and practicability of our PDF Table Annotation tool, we conducted a user based evaluation, comparing the software to three other means of creating table annotations from documents.
Two factors are being evaluated: the time it takes to annotate a document, and the accuracy of the annotations. Furthermore, qualitative feedback, experience reports, and suggestions from the testers were collected. All the time spent by a user working on a document was taken into account. This includes such activity as browsing pages and looking for tables or verifying the correctness of the results of the annotation process, as well as any post-processing steps necessary that were outside the main tool under evaluation. The time was measured automatically through log-files (for PDF Table Annotator), or separately and manually by the experimenter (for the other approaches). To test the quality of the annotations, they were compared against a gold standard.
4.1 Evaluated Systems
In addition to the PDF Table Annotator tool, three other approaches to creating table ground truth data were evaluated: DocWrap Annotator, Tabula and Okular. (The exact versions used in the evaluation were DocWrap Annotator 1.4, Tabula 0.9.3 and Okular 0.17.5.) Table 1 summarizes the qualitative differences of the four tools, regarding design, usage and the table model that can be produced. For example, not all tools create the same table model as output. Thus, to make all results comparable, the table data was converted into a grid-based format, and stored as CSV files. The final CSV files were then compared against our gold standard. For Okular and Tabula, an additional external editing tool had to be used in the process. DocWrap Annotator, Okular and Tabula implement optional automatic or semi-automatic detection of table structure, once the user has defined the region of a table. Okular does not support storing the data at all and only supports a copy-to-clipboard functionality. Tabula offers only a mode of auto-detection, but no editing functionality and hence makes an external editor the only option for making any corrections.
| Feature | DocWrap | Okular | Tabula | PTA |
| Auto-detection | Yes | Part. | Yes | No |
| Editable | Part. | Part. | No | Yes |
| Post-processing required | No | Yes | Yes | No |
| Cell-classification | No | No | No | Yes |
| Spatial information | Yes | No | No | Yes |
Table 1: Comparison of features of the four tested approaches, including our tool (PTA). The features are: is a mechanism for auto-detection of table structure provided, are tables editable in the primary tool, is a secondary editor required for editing the results, can elements of the table be labeled (for instance to be header cells), and lastly, can spatial information be kept and exported.
4.2 Evaluation Dataset
The documents used in our evaluation were selected from the dataset annotated by Göbel et al. [2]. This dataset has the advantage of having table data in structural and functional form which allows for a comparison of table data and table interpretation. The table data was converted, then revised and manually corrected where necessary. It should be noted, that overly complex and ambiguous tables have already been excluded from the original dataset, as well as large sections of pages that did not include any tables [2].
To allow a more fine-grained evaluation, the tables are categorized regarding complexity — a table with more than one hundred cells in total (large table) or a table with at least one spanning cell is regarded as 'complex' ('type-A'). In addition, a second distinction between different table-complexities is derived from Fang et al. [1]: tables with multi-line cells or multi-line headers; and tables that are multi-dimensional or otherwise irregular, long or folded are regarded as complex ('type-B'). The examination on a random sample drawn from the CiteSeer database (sample size = 135) revealed that 60% of tables were complex tables using this classification [1].
A table can fall into both complexity classes A and B at the same time, if both conditions are met. Tables that do not meet the conditions of any of the two complexity classes are regarded as simple tables. The final test dataset used for evaluation contains six documents with 14 tables on 23 pages. 35.7% and 71.4% of the tables fall into the category complex type A and B, respectively (Table 2), where one table has been classified as both class A and B.
| Doc. | Pages | Table | Complex tables (A) | Complex tables (B) |
| 1 | 4 | 1 | 1 | 1 |
| 2 | 3 | 2 | 1 | 2 |
| 3 | 4 | 5 | 1 | 5 |
| 4 | 4 | 1 | 0 | 0 |
| 5 | 4 | 1 | 0 | 0 |
| 6 | 4 | 4 | 2 | 2 |
| Total | 23 | 14 | 5 (35.71%) | 10 (71.43%) |
Table 2: An overview of the data set that was used in the evaluation. The table lists the number of pages, tables and types of tables (complexity regarding two different definitions) found in each document.
4.3 Evaluation Setup
Five human subjects were asked to perform the table annotation task on the test dataset four times, using a different work flow each time. All of the subjects work with computers on a daily basis. There was no special domain knowledge of the domain(s) of the test documents by any of the subjects. Before evaluating a specific work flow, all the necessary steps and the provided functionality of the respective tools were explained, and at least one document was annotated by the test subject before conducting the actual study. During the evaluation, the testers could ask questions regarding the task or the tools at any time.
4.3.1 Verifying Correctness and Accuracy
Starting from the basic table model (grid of cells), the measure for correctness is given through the F1 score, for which precision and recall are measured on the level of table cells. To do that, tables are first converted into a one-dimensional structure, a list of cells (disregarding the information identifying what row a cell belongs to). When comparing the elements of the lists one by one, every cell agreement — i.e., the cells contain the same string of characters — is counted as a positive retrieval. In cases where the cells at the current position do not agree, the list pointer is moved forward (consecutively for both lists) until an agreement is reached again. The process then continues at the position of agreement that is closest the the original position. This method is less complex to implement than some other methods discussed in literature (like graph-probing or edit-distance), but still has some stability and robustness regarding errors like skipped or merged cells. In addition, some normalization steps are made to reduce errors stemming from the post-processing step, for instance the evaluation process skips empty cells at the end of a line; and all white-space characters are furthermore stripped from the cell contents before the comparison.
5 Results
In this section, the results of the evaluation of the four annotation systems regarding annotation time and accuracy are presented.
As a measure of usability and efficiency, the time it takes to annotate a document was measured and the results are depicted in Figure 5 and summarized in Table 3. The presented time is the average time for the human annotators for each document reported separately. The time includes the selection of the table regions, the annotation of the table structure, as well as the correction of the errors.
| Tool | µ | 1 | 2 | 3 | 4 | 5 | 6 |
| DWr | 6:56 | 4:05 | 9:48 | 11:06 | 3:28 | 2:30 | 10:40 |
| Ok | 3:01 | 3:36 | 5:47 | 3:19 | 1:18 | 0:52 | 3:16 |
| Tab | 4:46 | 4:13 | 7:30 | 9:20 | 1:53 | 1:04 | 4:36 |
| PTA | 2:58 | 3:32 | 3:34 | 3:39 | 1:42 | 0:58 | 4:23 |
Table 3: Mean annotation time. Measuring the time it took to create the annotations for the documents, using the specific approaches (DWr = DocWrap, Ok = Okular, Tab = Tabula, PTA = PDF Table Annotator).
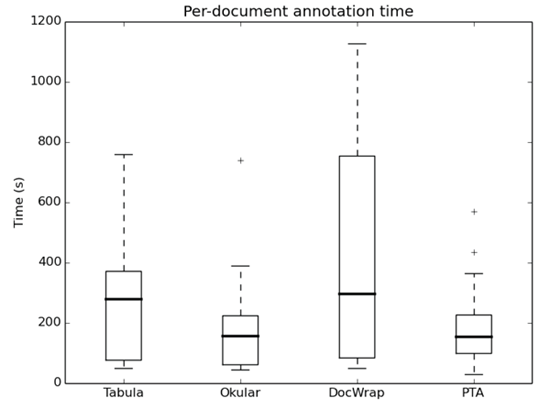
Figure 5: Measured time to annotation with the four tools as box plot. For the PDF Table Annotator (PTA) tool and Okular the annotation times are similar, while for the other two tools the measured times where generally higher.
Next, we evaluated the accuracy of the extracted table data. The mean value (over all testers) is reported on a per document basis using our grid based correctness measure in Table 4. For documents with more than one table, the arithmetic mean is calculated from the table based F1 scores. The overall accuracy as mean over all documents is reported in the last row.
| Tool | µ | 1 | 2 | 3 | 4 | 5 | 6 |
| DWr | 0.68 | 0.52 | 0.59 | 0.64 | 0.90 | 0.67 | 0.78 |
| Ok | 0.85 | 0.96 | 0.81 | 0.89 | 0.90 | 1.00 | 0.53 |
| Tab | 0.54 | 0.29 | 0.30 | 0.26 | 0.93 | 1.0 | 0.44 |
| PTA | 0.93 | 0.99 | 0.97 | 0.99 | 0.98 | 1.00 | 0.67 |
Table 4: Correctness — mean accuracy of the annotation per document and tool (DWr = DocWrap, Ok = Okular, Tab = Tabula, PTA = PDF Table Annotator).
Table 5 shows a summary of all annotations times and accuracy. In addition, tables which were classified as lower complexity are reported separately for the time to annotate and their accuracy.
| Tool | t/all | Acc./all | t/simple | Acc./simple |
| DocWrap | 6:56 | 0.68 | 2:59 | 0.78 |
| Okular | 3:01 | 0.79 | 1:05 | 0.95 |
| Tabula | 4:46 | 0.42 | 1:29 | 0.97 |
| PTA | 2:58 | 0.89 | 1:20 | 0.99 |
Table 5: The mean per document annotation time and per document accuracy, shown separately for tables overall and for the subset of non-complex tables (denoted as 'simple').
6 Discussion
For our PDF Table Annotator tool, annotations are completed fastest overall, with only the results of the Okular PDF reader being comparable. The Okular PDF reader performs slightly better for the subset of documents with simple tables. Even more encouraging are the results regarding the accuracy of the annotations: here, the PTA tool performs the best for five out of the six test documents, and has the best performance overall (F1 score of 0.93 versus 0.85 for the Okular PDF reader). The general drop in accuracy in the sixth document occurs mainly due to a misconception by the testers in comparison to the gold standard, when two closely adjacent tables were merged into one. Although the annotation tasks were accomplished fastest using the Okular system for simple tables, annotations with PTA were completed reasonably fast, and with an accuracy that is slightly higher. In addition, with estimates that suggest that around 70% of tables contain complex features (see Section 4.2), the ability to annotate such tables well is of high importance. PTA has the best accuracy and time-per-document for documents containing complex tables.
Comparing the two approaches that rely on post-processing with an external spreadsheet application (Tabula and Okular), better results in both accuracy and annotation time were achieved with Okular. Annotations with the Tabula tool have the highest variance in accuracy-per-table, mainly due to errors introduced in the necessary post-processing step. Comparing the two approaches that are specifically targeted for the task (PTA and the DocWrap application), DocWrap performs very well for some specific tables (in cases where the automatic detection worked well), but is generally less convenient to use when manual corrections need to be performed.
The different capabilities of the tools have an effect on both the table model which is stored as output, and the annotation process itself which is limited by the capabilities of the respective tools. PTA and DocWrap-Annotator provide a richer table model that stores spanning information for cells explicitly, as well as spatial information regarding the absolute position of the elements on the page. Okular and Tabula just store a simple model — the only format that is supported is a grid based model without any additional information. Only DocWrap is capable of expressing multiple regions for a single table. With regard to the functional table model, PDF Table Annotator is the the only tool that allows distinguishing access and data cells (denote header cells) and thereby exporting a functional table model.
Three tools (all but PTA) come with some kind of embedded automatic detection, of which two — Okular and DocWrap — allow editing of the auto detected structure afterwards. In the case of Okular, the editing functionality is grid based (only separation lines can be added or removed); for DocWrap, only single cells can be deleted and added. For systems that use auto detection, multi-row cells will cause a drop in accuracy, increased editing time, or both. On many occasions we observed that every line of text is detected as a separate row. The ability to correct such mistakes depends on the type of editing functionality — for the Okular system, the structure can be corrected relatively easily. The correction process for the DocWrap system is less practical, as cells can only be deleted one-by-one and be re-drawn. This mainly accounts for the rather long annotation time and low accuracy this tool attains. In the evaluation, the external spreadsheet editor proved to be a potential source of introducing new errors in the data. The merging of multi-row cells can result in completely empty rows, which is then interpreted by the evaluation process as a table boundary; or the word or letter order of a merged cell can end up being wrong. This is the main reason for the sometimes particularly low accuracy (and high variance) in the data created with Tabula.
Regarding manual editing, the PTA tool provides the widest range of editing features (grid based, move, resize, merge, add, remove). Taking the experience of our human subjects into account, we can summarize that PTA is the only system that allows to edit tables in a convenient manner. No major usability drawbacks e.g. regarding occurring errors or unexpected behavior were noted. The set of table operations at hand to the annotator has proven to be sufficient to create annotations for most tables quite efficiently. The PDF Table Annotator tools has demonstrated to be convenient to use with both simple and complex tables: for simple and small tables manual creating does not take up much time, and the evaluation showed that with complex tables, manual annotation is often the only option.
7 Conclusions
We presented a web based tool designed to facilitate the creation of ground truth data for tabular information in PDF files. Because of a lack of large datasets suitable for training detection algorithms, or comparing detection results, progress in that area of information extraction has been hindered. The development of the PDF Table Annotator tool intends to make the creation of table ground truth data in various formats more convenient.
We conducted a user based evaluation and compared our tool against three other tools to create table annotations. In the evaluation we found that our tool is convenient and efficient to use and out-performs the compared approaches in accuracy. Furthermore, it has been found to be competitive in annotation time per document for simple tables and performs best regarding annotation time per document for large and complex tables. Compared to the other evaluated tools, our tool offers a more integrated and intuitive work flow in which tables can be edited, visual feedback of detection attempts can be shown, and table models of different formats can be stored and exported. The application provides functionality for making distinctions between cell-types, thus allowing the creation of functional table ground truth — a feature that is not available in any of the other tools that were evaluated.
As future work, we plan to follow up on the possibility of annotating headers and header structure in more detail. First, create a functional data model by correctly interpreting headers. Next, continue adding more options to the tagging part of the annotation process so that the user can begin to label the hierarchy of headers in cases where there is disambiguation. This information can then be used to improve the quality and expressiveness of the functional table model the system is able to produce. Furthermore, an increase in usability of our tool would help to increase overall efficiency, by adding features such as the ability to split cells or the addition of automatic table structure detection. A combination of the two annotation steps (grid line, table editing) or the possibility to switch back and forth between the two, would also be an improvement worth making.
Acknowledgements
The presented work was in part developed within the CODE project (grant no. 296150) and within the EEXCESS project (grant no. 600601) funded by the EU FP7, as well as the TEAM IAPP project (grant no. 251514) within the FP7 People Programme. The Know-Center is funded within the Austrian COMET Program — Competence Centers for Excellent Technologies — under the auspices of the Austrian Federal Ministry of Transport, Innovation and Technology, the Austrian Federal Ministry of Economy, Family and Youth and by the State of Styria. COMET is managed by the Austrian Research Promotion Agency FFG.
References
[1] J. Fang, P. Mitra, Z. Tang, and C. Giles. Table Header Detection and Classification. AAAI, pages 599-605, 2012.
[2] M. Göbel, T. Hassan, E. Oro, and G. Orsi. A methodology for evaluating algorithms for table understanding in PDF documents. Proceedings of the 2012 ACM symposium on Document engineering, pages 45-48, 2012. http://doi.org/10.1145/2361354.2361365
[3] T. Hassan. Towards a common evaluation strategy for table structure recognition algorithms. Proceedings of the 10th ACM symposium on Document engineering — DocEng '10, page 255, 2010. http://doi.org/10.1145/1860559.1860617
[4] J. Hu, R. Kashi, D. Loprestil, G. Wilfongt, A. Labs, and M. Hill. Why Table Ground-Truthing is Hard, pages 129-133, 2001. http://doi.org/10.1109/ICDAR.2001.953768
[5] P. Jha. Wang Notation Tool: A Layout Independent Representation of Tables. PhD thesis, 2008.
[6] S. Klampfl, M. Granitzer, K. Jack, and R. Kern. Unsupervised document structure analysis of digital scientific articles. International Journal on Digital Libraries, 14(3-4):83-99, 2014. http://doi.org/10.1007/s00799-014-0115-1
[7] S. Klampfl, K. Jack, and R. Kern. A comparison of two unsupervised table recognition methods from digital scientific articles. D-Lib Magazine, 20(11):7, 2014. http://doi.org/10.1045/november14-klampfl
[8] D. D. Lewis. Evaluating and optimizing autonomous text classification systems. In Proceedings of the 18th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR '95, pages 246-254, New York, NY, USA, 1995. ACM. http://doi.org/10.1145/215206.215366
[9] Y. Liu. Tableseer: automatic table extraction, search, and understanding. PhD thesis, 2009.
[10] Y. Liu, P. Mitra, and C. L. Giles. Identifying table boundaries in digital documents via sparse line detection. Proceeding of the 17th ACM conference on Information and knowledge mining — CIKM '08, page 1311, 2008. http://doi.org/10.1145/1458082.1458255
[11] V. Long. An agent-based approach to table recognition and interpretation. PhD thesis, Macquarie University Sydney, Australia, 2010.
[12] D. Lopresti and G. Nagy. A Tabular Survey of Automated Table Processing. In Graphics Recognition, 1999. http://doi.org/10.1007/3-540-40953-X_9
[13] G. Nagy. Document image analysis: Automated performance evaluation. Document analysis systems, (14):137-156, 1995.
[14] E. Oro and M. Ruffolo. PDF-TREX: An Approach for Recognizing and Extracting Tables from PDF Documents. 2009 10th International Conference on Document Analysis and Recognition, pages 906-910, 2009. http://doi.org/10.1109/ICDAR.2009.12
[15] A. Pivk, P. Cimiano, Y. Sure, M. Gams, V. Rajkovič, and R. Studer. Transforming arbitrary tables into logical form with TARTAR. Data & Knowledge Engineering, 60(3):567-595, Mar. 2007. http://doi.org/10.1016/j.datak.2006.04.002
[16] A. Shahab, F. Shafait, T. Kieninger, and A. Dengel. An open approach towards the benchmarking of table structure recognition systems. Proceedings of the 8th IAPR International Workshop on Document Analysis Systems — DAS '10, pages 113-120, 2010. http://doi.org/10.1145/1815330.1815345
[17] X. Wang. Tabular Abstraction, Editing, and Formatting. PhD thesis, 1996.
[18] Y. Wang, I. T. Phillips, and R. Haralick. Automatic Table Ground Truth Generation and A Background-analysis-based Table Structure Extraction Method. Sixth International Conference on Document Analysis and Recognition. Proceedings., 2001. http://doi.org/10.1109/ICDAR.2001.953845
[19] R. Zanibbi, D. Blostein, and J. R. Cordy. A Survey of Table Recognition: Models, Observations, Transformations, and Inferences. pages 1-33, 2003. http://doi.org/10.1007/s10032-004-0120-9
About the Authors
 |
Matthias Frey works as an independent consultant and developer. He holds a BSc in Software Development from the Technical University of Graz. His interests include data mining and information retrieval. |
 |
Roman Kern is the division manager of the Knowledge Discovery area at the Know-Center and senior researcher at the Graz University of Technology, where he works on information retrieval and natural language processing. In addition he has a strong background in machine learning. Previous to working in research he gained experience in industry projects at Hyperwave and Daimler. There he worked as project manager, software architect and software engineer for a number of years. He obtained his Master's degree (DI) in Telematics and his PhD in Informatics at the Technical University of Graz. After his studies he worked at a start-up company in the UK as a Marie Curie research fellow. He participates in a number of EU research projects, where he serves as coordinator and work package leader. He manages a number of large research and development projects in cooperation with the industry. He also gives lectures at the Technical University of Graz for Software Architecture, Knowledge Discovery and Data Science. He also serves as supervisor for Bachelor, Master and PhD students. He published over 40 peer-reviewed publications and achieved top rank results in international scientific challenges like CLEF, ACL SemEval. Most of his publication work can be accessed online. |
|
|
|
| P R I N T E R - F R I E N D L Y F O R M A T | Return to Article |