|
|
|
| P R I N T E R - F R I E N D L Y F O R M A T | Return to Article |
D-Lib Magazine
November/December 2014
Volume 20, Number 11/12
Annota: Towards Enriching Scientific Publications with Semantics and User Annotations
Michal Holub, Robert Moro, Jakub Sevcech, Martin Liptak and Maria Bielikova
Slovak University of Technology in Bratislava, Slovakia
{michal.holub, robert.moro, jakub.sevcech, maria.bielikova}@stuba.sk and mliptak@gmail.com
doi:10.1045/november14-holub
Abstract
Digital libraries provide an access to a vast amount of valuable information, mostly in the form of scientific publications. The large volume of documents poses challenges regarding their effective organization, search and means of accessing them. In this paper we present Annota — a collaborative tool enabling the researchers to annotate and organize the scientific publications on the Web and to share them with their colleagues. Annota is also a research platform for evaluation of the methods dealing with automatic organization of the collections of the documents, aiding the users with navigation in large information spaces, as well as the methods of intelligent search for relevant entities based on the content of the information artifacts, user activity and corresponding metadata. We describe the available infrastructure together with examples of the research methods we have realized.
Keywords: Digital Library, User Model, Domain Model, Scientific Publication, Annotation, Search, Navigation, Semantics, Annota
1. Motivation
The number of documents in digital libraries in general is so large that it is difficult or even impossible to navigate, search and organize them effectively manually. Additionally, research is increasingly becoming a teamwork. Researchers need to cooperate with each other, for which the suitable tools are needed. These are the challenges the modern digital libraries should address.
There are many examples of systems which allow researchers to search, organize and reference scientific publications. CiteSeerX focuses on crawling and indexing research papers in the domain of computer science [4]. Its primary goal is to provide (personalized) search capabilities to its users. Similarly, CiteULike is an online service for organization of scholarly references allowing to store bookmarks and share them with friends or colleagues [3].
Recently, Mendeley has become popular for organization of personal collections of scientific publications. It can automatically extract metadata from them; the users are able to highlight parts of the text and annotate them [13]. Other solutions similar to Mendeley include Paperpile or ReadCube; they both focus on management of references and scientific publications in the form of PDFs. Docear on the other hand, approaches the problem differently, by allowing the users to create mind maps [2].
However, the challenges present in digital libraries are addressed only partially by the presented existing solutions. They often rely solely on the text mining and processing omitting advanced semantics. We have identified the following limitations of the current approaches:
- Limited support for personalization — existing digital libraries systems often lack a proper user model built from user actions as an overlay over the domain model of the information space.
- Limited support for effective navigation and exploration of the scientific publications space — most of the existing approaches rely on the fulltext search, which in many cases does not utilize metadata available for the scientific publications. In addition, fulltext search is not suitable for all the scenarios, in which exploration, information space travelling [9] and making sense of a domain are prevalent, such as exploratory search [6].
- Limited support for organization of personal collections of scientific publications — the approaches support only folders or tags, which rely on the manual classification of new resources and are demanding with respect to reorganizing the collection.
- Lack of collaboration and support of active participation of users — collaboration in research is a trend that is only slowly addressed by the existing approaches in this domain. Important is also ability to (collaboratively) annotate the documents.
In this demo paper, we present Annota — our contribution to addressing the identified limitations. It serves the researchers as (i) a collaborative tool enabling the researchers to organize, search and effectively work with collections of the documents (scientific publications) and (ii) an evaluation platform for experimenting with methods of personalized navigation, search and organization.
Special focus is given to novice researchers as they are more prone to being overloaded by the available information and therefore need more guidance in order to find relevant publications. We utilize semantics heavily to overcome some of the challenges as well as user actions for advanced personalization and adaptation.
2. Annota — Bookmarking and Annotation
At its core, Annota is a bookmarking service that allows collaborative annotation of the scientific publications. It has two main components: a browser plugin and a web interface.
The plugin allows researchers to directly bookmark and annotate interesting papers, as well as recommend them to other users and share them in groups. It is also used for gathering of the metadata of the scientific publications via a distributed crawling mechanism. The browser plugin sends visited pages of the supported digital libraries, such as ACM DL or IEEE Xplore to the server, where the metadata are extracted. Additionally, it tracks the behavior of the users in these libraries, which is used to infer interests of the users.
The web interface organizes the entire collection of bookmarks into various views (see Figure 1). It also allows the users to search for other documents not included in their personal collection and interact with each other in groups. Annota includes other social features as well, such as following the activities of other users.
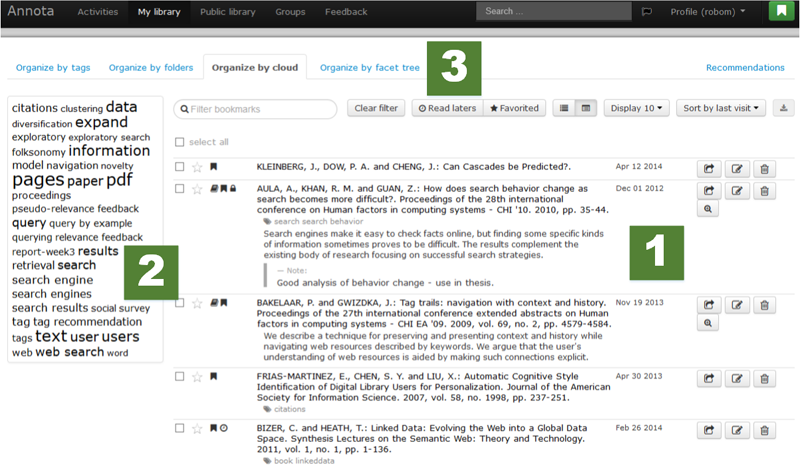
Figure 1. Annota web interface: The users can access their bookmarks together with the associated tags and notes (1). They can organize and navigate in their personal collection using a tag cloud (2) or other available methods, such as a list of tags, folders, or a facet tree (3).
Domain and User's Interests Models
Both user and domain models are represented by a unified graph, which includes all types of user and domain data available in Annota. The graph has two main layers; the first layer represents the domain model which consists of terms (in normalized, i.e. stemmed form) on one hand and papers (documents) on the other. Between these vertices are weighed edges, which reflect the relevancy of the term for the paper computed based on different associated metadata, such as tags, folders, or annotations as well as automatically extracted keywords. These metadata are also represented by vertices in the graph.
The second, overlay layer comprises the actual user model. The principal vertices in the model are user and term. All of the logged user's interactions (e.g. creating a folder, formulating a query) are transformed to the respective graph edges with weights indicating the strength of the relation. Weights estimate user interest in a particular term. The edge on the highest level of hierarchy is of type user-term (see Figure 2). Its weights are computed as a function of all the weights on the path from a given user vertex to a given term vertex and indicate user's interests.
The graph model is extensible and flexible enough to include new types of user interactions or content metadata. The user-term edge can be adjusted to include the new edge or a new type of the user-term edge can be introduced. The latter means that two user models would co-exist in the graph. This way, the models can be experimentally compared. For example, our new keyword extraction service [11] can be easily evaluated using this feature.
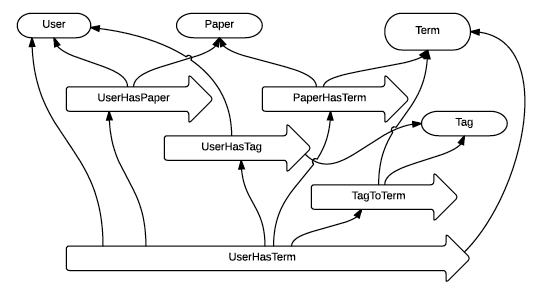
Figure 2. The schematic representation of the user model graph: The UserHasTerm relationship between the User and the Term combines all the partial relationships on the way from the User to the Term.
In addition, our graph-based approach has advantage over vector-space model approach in that we can keep partial results of all the computations. It allows us to reuse and share them among multiple user models and try different research methods while requiring less computation power. This approach scales well when dealing with large quantities of data. It also allows us to model different (typed) relations between the entities that would not be possible using the vector-space model approach.
By tracking the visited pages from digital libraries together with metadata about papers and authors we map the information space that is being searched and navigated by researchers. Thus, the huge information space is being reduced and it contains only entities (papers, authors, etc.) interesting to the community. This information can be used for recommendation of papers to novice users and to improve the search results accuracy for particular community of researchers.
Collaborative Annotation
Annota allows its users to create various types of annotations directly from the web browser: textual notes (comments) linked to whole papers as well as to their parts, tags, and highlights of the text. These can be made public or visible only to certain users (if the paper is shared within a group). This way annotations become effective tool of collaboration, e.g. between the supervisors and their students.
The supervisors can also easily recommend important publications to their students and track the students' progress using periodic reports listing the papers together with annotations and comments. Collaboration support is not limited to the supervisor-student scenario; researchers can create groups and share publications as well as other online scientific resources.
In addition, annotations can be utilized for further personalization, since highlighting or adding a note to a fragment of a document can serve as an indicator of the users' interests as shown in our related documents search approach [12].
Adding Semantics via Linking Entities
We process metadata of the visited documents in the selected digital libraries by extracting papers' title, authors, keywords, publication name and year, etc. The gathered data is then transformed into RDF form which uses standard BIBO ontology. This semantic-rich representation allows us to realize and improve various methods used in the adaptive web domain, such as support of natural language querying or exploratory search.
3. Annota — Evaluation Platform
Apart from being a bookmark-organization tool, Annota is also a platform for evaluation of various research methods. Its main advantage is in configurable and easily extensible user and domain model discussed in the previous section as well as in support of different experimental setups that allows A/B testing. Thus, we can easily divide the users of Annota into experimental groups based on different criteria (e.g. the amount of their activity within the system in order to create balanced groups) and set up, what the users will see (i.e. what interface or specific method will be used) as well as what relations from the domain and user model will be considered in inferring the users' interests. Altogether, this allows us to evaluate the research methods on separate layers [10].
In addition to the provided evaluation infrastructure, there are currently more than 50,000 scientific publications (papers) from the domain of informatics and computer science in our Annota dataset, together with 230,000 authors and 140,000 author-added keywords. The dataset also contains usage data from 198 users in Annota who have bookmarked 8,400 documents, added more than 3,400 tags to them and shared them in more than 110 groups. The whole dataset is publicly available here for research purposes.
We also work on anonymization of the collected activities of the researchers (such as their clicks in the digital libraries, search queries etc.) for extending our public dataset. However, there is already an implicit information on the researchers' behavior as the dataset consists of metadata on the related publications concerning the researchers' interests as they were all part of the researchers' navigations performed within the supported digital libraries.
We have successfully employed the evaluation infrastructure and the dataset in various studies and experiments. We have developed a facet tree method for personalized organization of the collection of the scientific publications [8]. The method groups the papers into facets based on the selected features allowing the users to explore various dimensions of the data. It is thus possible to discover hidden relationships between the publications using a combination of facets and clustering of the documents.
Our other approach relies on user-added tags and supports personalized navigation using a cloud of important terms [7]. We considered not only the frequency of terms in the collection of the scientific publications when computing the contents of the cloud, but also histories of navigation of the users. We thus highlighted what topics were important for the users and what terms were usually used by the users when searching for the topics. This can be especially useful for the novice users (researchers), who have only limited knowledge of the domain.
Supporting the novice researchers in their exploration of the domain is also the goal of the proposed method of navigation leads. The navigation leads are represented as links within the summaries of the scientific publications, which help to filter the information space of a digital library and thus provide different navigation paths. They are extracted automatically from the text and we use various available metadata (such as papers title, conference name, keywords) in order to compute their relevancy for the users. We have evaluated different types of presentation of the leads.
We have also experimented with entity search (authors, papers, etc.) using natural language queries based on unique preprocessing of the RDF dataset and real-time proposals while typing the query. The user queries are thus automatically transformed to SPARQL which is then used to query the actual ontological database.
In addition, we used the RDF representation to provide the users with the exploratory search feature in the form of recommendations on the related previously unexplored entities utilizing the links between the entities. The relevancy of the entities was computed using a set of weighed heuristics; the weights were trained for each user based on his or her navigation behavior.
4. Conclusion
In the paper, we presented bookmarking service Annota. The main contributions of our approach can be summed up as follows:
- The lightweight domain model consisting at the highest level of keywords (terms), that nevertheless allows us to model relationships of various types, e.g. based on analysis of citations and their context [5]
- The flexible and easily extensible user model of researchers' interests, which is utilized for personalization of the system, recommendation of the relevant papers and provides us with means of exploratory search support [1]
- Support of collaboration between the researchers within the groups including the collaborative annotation
- The use of semantics for (exploratory) search and querying in natural language
- Support of various methods of navigation and organization of the documents
Annota primarily focuses the domain of digital libraries and researchers who work with them. However, the users are free to use it on the whole Web, bookmark and annotate any web page and share them in groups. It might be useful e.g. for a team of web developers working together, who could share and discuss interesting on-line resources, such as tutorials.
Overall, the created infrastructure, the collected dataset and the user base allow us to develop novel approaches aiming at even greater utilization of semantics and relationships provided by our graph-based models. These are also our plans for further research. We also see a potential in using other novel forms of implicit feedback for advanced personalization and modeling of the users' interests, such as gaze tracking, i.e. tracking where the users look.
We would be happy to share our anonymized dataset and collaborate with other fellow researchers interested in the same research domain.
Acknowledgements
This work was partially supported by the Scientific Grant Agency of the Slovak Republic, projects No. VG1/0675/11, VG1/0971/11, and by the Slovak Research and Development Agency under the contract No. APVV-0208-10.
References
[1] Athukorala, K., Oulasvirta, A., Glowacka, D., Vreeken, J., Jacucci, G. 2014. Supporting exploratory search through user modeling. In UMAP '14: Extended Proceedings: Posters, Demos, Late-breaking Results and Workshop Proceedings of the 22nd Conf. on User Modeling, Adaptation, and Personalization, vol. 1181. CEUR-WS.
[2] Beel, J., Gipp, B., Langer, S., Genzmehr, M.: Docear: An academic literature suite for searching, organizing and creating academic literature. In JCDL '11: Proc. of the 11th Annual Int. ACM/IEEE Joint Conf. on Digital libraries. ACM Press, NY, 465—466. http://doi.org/10.1145/1998076.1998188
[3] Emamy, K., Cameron, R. 2007. Citeulike: A researcher's social bookmarking service. Ariadne, 51.
[4] Li, H., Councill, I., Lee, W.C., Giles, C.L. 2006. CiteSeerX: An architecture and web service design for an academic document search engine. In WWW '06: Proc. of 15th Int. Conf. on World Wide Web. ACM Press, NY, 883—884. http://doi.org/10.1145/1135777.1135926
[5] Liu, S., Chen, C. 2013. The differences between latent topics in abstracts and citation contexts of citing papers. J. of the American Society for Inf. Science and Technology, 64(3), 627—639. http://doi.org/10.1002/asi.22771
[6] Marchionini, G. 2006. Exploratory search: From finding to understanding. Communications of the ACM, 49(4), 41—46. http://doi.org/10.1145/1121949.1121979
[7] Molnar, S., Moro R., Bielikova, M. 2013. Trending words in digital library for term cloud-based navigation. In SMAP '13: Proc. of 8th Int. Workshop on Semantic and Social Media Adaptation and Personalization. IEEE CS, Washington, D.C., 53—58. http://doi.org/10.1109/SMAP.2013.23
[8] Moro, R., Bielikova, M., Burger, R. 2014. Facet tree for personalized web documents organization. In WISE '14: Proc. of 15th Int. Conf. on Web Inf. Systems Engineering. LNCS 8786. Springer, Berlin, Heidelberg, 372—387. http://doi.org/10.1007/978-3-319-11749-2_28
[9] Navrat, P. 2012. Cognitive traveling in digital space: From keyword search through exploratory information seeking. Central European J. of Computer Science, 2(3), 170—182. http://doi.org/10.2478/s13537-012-0024-6
[10] Paramythis, A., Weibelzahl, S., Masthoff, J. 2010. Layered evaluation of interactive adaptive systems: framework and formative methods. User Modeling and User-Adapted Interaction, 20(5), 383—453. http://doi.org/10.1007/s11257-010-9082-4
[11] Sajgalik, M., Barla, M., Bielikova, M. 2014. Exploring multidimensional continuous feature space to extract relevant words. In SLSP '14: Proc. of 2nd Int. Conf. on Statistical Lang. and Speech Processing. LNAI 8791. Springer, pp. 159—170. http://doi.org/10.1007/978-3-319-11397-5_12
[12] Sevcech, J., Moro, R., Holub, M., Bielikova, M. 2014. User annotations as a context for related document search on the web and digital libraries. Informatica, 38(1), 21—30.
[13] Zaugg, H., West, R.E., Randall, D.L. 2011. Mendeley: Creating communities of scholarly inquiry through research collaboration. TechTrends. 55, 32—36. http://doi.org/10.1007/s11528-011-0467-y
About the Authors
 |
Michal Holub is a researcher and PhD student at Slovak University of Technology in Bratislava where he received his Master's degree in Software Engineering. In his thesis he explored the possibilities for recommending interesting documents to users based on their actions on the Web. He has been working on Annota since its inception in 2012. His main interests in the project are domain modeling and data processing. In his current research he focuses on Semantic Web and Linked Data, and utilization of these technologies in intelligent web applications. |
 |
Robert Moro is a PhD student at Slovak University of Technology in Bratislava where he also received his Master's degree in Software Engineering. During his Master's studies he focused on automatic text summarization and personalization in the domain of education, now his area of research concerns exploratory search and navigation in the domain of digital libraries. Besides working in the team that developed Annota, he was part of a team behind educational system ALEF. His research interests also include eye-tracking and its use for UX studies, as well as adaptation. |
 |
Jakub Sevcech is a PhD student at Slovak University of Technology in Bratislava where he received his Master's degree in Software Engineering. He was part of the team that developed the Annota bookmarking and article sharing service. He published multiple research articles where he focused on employment of user created annotations and bookmarks in personalization, user interest detection and search. In his current work he focuses on online processing and analysis of stream data. |
 |
Martin Liptak completed his Master's degree at Faculty of Informatics and Information Technologies at Slovak University of Technology. His research interests during the period of his studies include data integration, microblog recommendation and user modeling applied to digital libraries. Currently he focuses on language learning systems. |
 |
Maria Bielikova is a full professor at the Institute of Informatics and Software Engineering, Slovak University of Technology in Bratislava. Her research interests are in the areas of web-based information systems, especially personalized context-aware web-based systems including user modeling, recommendation and collaboration support. She co-authored over 70 papers in international scientific journals and she served as an editor of more than 40 proceedings, seven of them published by Springer. Most of her publications can be accessed here. She is a senior member of IEEE Computer Society, senior member of ACM and member of International Society for Web Engineering. |
|
|
|
| P R I N T E R - F R I E N D L Y F O R M A T | Return to Article |