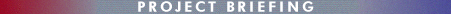
The Illinois testbed of full-text scientific and engineering journal articles was developed as part of a Digital Library Initiative (DLI) grant awarded to the University of Illinois at Urbana-Champaign (UIUC) in 1994. Work on the Illinois DLI grant was carried out by a multi-departmental research team comprised of individuals from the university's Graduate School of Library and Information Science, the University Library, the National Center for Supercomputing Applications (NCSA), and the Department of Computer Science.
The testbed is constructed from source text journal articles contributed by several professional society publishers. The Illinois DLI testbed is presently comprised of articles full-text in SGML format, the associated article metadata, and bit-mapped images of figures for 63 journal titles containing over 60,000 articles from six scholarly professional societies in physics and engineering. The full-text articles for the testbed have been contributed by: the American Institute of Physics (AIP), the American Physical Society (APS), the American Society of Civil Engineers (ASCE), the Institute of Electrical and Electronics Engineers Computer Society (IEEE CS), and the Institution of Electrical Engineers (IEE).
The testbed team has implemented a large-scale web-based testbed of full-text journal articles featuring enhanced access and display capabilities. The web-based retrieval system developed by the DLI Testbed and Evaluation teams is called DeLIver (Desktop Link to Virtual Engineering Resources). The DeLIver client, which replaced a Microsoft Windows-based custom client in use for the first two years of the project, has been in operation since September of 1997 and is being used by over 1,200 registered UIUC students and faculty, as well as designated outside researchers. Sample pages from a DeLIver search session are shown in Figure 1 below. Detailed transaction log data of user search sessions (gathered and merged from both database and web servers) are being kept and a preliminary analysis of user search patterns from some 4,200 search sessions has been performed.
The overarching focus of the DLI testbed team has been on the design, development, and evaluation of mechanisms that can provide effective access to full-text engineering and physics journal articles within an Internet environment. The primary goals of the Illinois testbed have been:
To support effective retrieval in the testbed, the Illinois DLI Testbed and Evaluation teams have also carried out studies of end-user searching behavior in an attempt to identify user-searching needs. One requirement specified by the testbed team from the onset of the project has been that the testbed as a resource for users must be integrated into the continuum of information resources offered by the Library system. This has been primarily accomplished in two ways: by making the testbed a search option within the Library public terminal top-level menu; and by linking testbed full-text records from the short entry displays within the Ovid Compendex and Inspec periodical index databases. Additional simultaneous search mechanisms are being explored.
The cornerstones of the testbed, in terms of retrieval capabilities, are the effective utilization of the article content and structure revealed by SGML and the production of the associated article-level metadata, which serves to normalize the heterogeneous SGML and provide short-entry display capability. The metadata also contains links to internal and external data in the form of forward and backward links to other testbed articles and links to A & I Service databases (particularly Ovid INSPEC and Compendex databases) and other full-text repositories, such as American Institute of Physics, the American Physical Society, and Elsevier. The metadata and index files, which contain pointers to the full-text data, can be stored independently of and separately from the full-text.
The testbed team is in the process of converting the SGML publisher data into well-formed XML (eXtensible Markup Language). The XML data can then be rendered natively in a web browser and/or converted to HTML to be rendered using emerging web technologies such as Cascading Style Sheets (CSS) and Dynamic HTML (DHTML). It is clear that a rich markup format such as XML, which is a nearly complete instance of SGML, will become the language of open document systems, to be used in web environments for document representation and delivery. XML and SGML permit documents to be treated as objects to be viewed, manipulated, and output. The major strength of these markup languages, in terms of their retrieval capabilities, is their ability to reveal the deep content and structure of a document. While SGML/XML are becoming ubiquitous in the publishing world, it is still, for the most part, being generated by publishers as a byproduct for archiving, rather than serving as an integral, integrated part of their production process.
The Document Type Definition (DTD) accompanying an individual publisher's SGML is the instrument that actually specifies the semantics and syntax of the tags to be used in the document markup. The DTD also specifies the rules that describe the manner in which the SGML tags may be applied to the documents. One of the major roadblocks in the successful deployment of the testbed has been the processing involved with the heterogeneous DTDs of the publishers. In the process of creating a viable testbed, the Illinois testbed team developed a number of techniques to address problems and normalize SGML processing, indexing, storage, retrieval, and rendering.
The testbed team has also studied the issues connected with the proper rendering of mathematics in web-based scientific and engineering articles. The Team has explored several techniques for properly rendering mathematics, and this will continue to be a major issue connected with scientific publishing.
An important concern of the testbed group has been in exploring effective retrieval models for a web-based electronic journal publishing system. The retrieval and display of full-text journal literature in an Internet environment poses a number of issues for both publishers and libraries. It has now become commonplace for both major and small-scale publishers to provide Internet (web-based) access to their publications, particularly journal issues and articles. For libraries and information providers, support for the online journal environment necessitates changes in collection policy, user access mechanisms, equipment provision, etc.
The testbed team has been examining the issues involved in the switch from a print-based journal environment to the Internet-based model, with a special eye toward providing retrieval mechanisms to optimize user access to full-text journals. To support this, the testbed team has proposed a distributed repository model that "federates" or connects the individual publisher repositories of full-text documents. In the DLI testbed model, these distributed repositories are federated by the extraction of normalized metadata, index, and link data from the heterogeneous full-text of the different publishers. This model addresses the challenge of providing standardized and consistent search capabilities across these distributed and disparate repositories.
The testbed team has succeeded in demonstrating the efficacy of the distributed repository model by producing cross-DTD metadata, providing parallel database querying and distributed retrieval techniques across a distinguished subset of the full-text repositories, and by setting up and employing an off-site repository at the site of a publisher.
Particularly relevant for any electronic journal publishing and retrieval model is the prominent role being played by the professional societies and commercial publishers. Electronic publishing of scientific articles is coalescing around the current professional society and commercial publisher model that dominates today's print-centric world. The testbed team distributed, repository retrieval model provides a mechanism for retrieval across subsets of the full-text publisher repositories without the requirement of going to each publisher site to perform individual searches.
The testbed team has recently converted the testbed metadata into an RDF (Resource Description Framework) XML format as a preliminary step to studying compatibility issues with the metadata structure of the Dublin Core.
In the next three years, with DARPA support, the testbed team expects to continue work on issues connected with full-text article indexing, retrieval, and rendering. In addition, a Collaborating Publishing Partners program has been instituted to provide additional support for the testbed. The testbed team is looking forward to collaborating with research partners on exploring extended testbed functionality. Testbed team members expect to focus additional work in the following areas:
For general information about this testbed, see the web site: http://dli.grainger.uiuc.edu/.
Researchers with serious interests in using the testbed, should contact: Timothy Cole, [email protected].