
Abstract: In the digital world, a scenario in which publishers offer digital contents directly to customers is technically feasible. However, the role of the library as a middle tier between publisher and customer offers so many advantages that it should be retained.But both two- and three-tier digital library services must protect the transactions between content owners and users. These not only include the protection of the content, but also include payment, assertion of copy- and usage rights, and protection of privacy. This article contrasts two different security technologies that enable these transactions: secure connections and secure packages. We conclude that secure packages are more appropriate to the digital library requirements.
However, we see substantial value in the intermediate role. We call that the three-tier architecture. The middle tier (the library) is often connected to its users over an intranet as opposed to the Internet. This tier can provide several advantages:
1. The middle tier can, on behalf of the entire community, obtain content which may be too expensive to be purchased individually. We programmers would recognize this as "site licensing".
2. The middle tier can provide to its patrons a guaranteed level of anonymity that cannot easily be matched on the open Internet.
3. The middle tier cache information and provide its patrons with much higher performance than the broad-area Internet.
4. The middle tier can be a trusted system, which greatly reduces the problems of delivering valuable content from the source to the consumer.
It has not escaped our attention that the values of this electronic entity are precisely the values that conventional libraries have been providing since their beginning: access to information, privacy and anonymity, and trusted authenticity.
However, we have observed that not all security technologies are equally friendly to this middle role. In this paper, we will contrast a common security technology on the Web -- connection protection -- with the more complete protection provided by document enveloping. But first, we will begin with a brief discussion of what digital library security needs to accomplish.
At the beginning of each digital library transaction, both the publishers (or the custodians who take care of the transaction) and the readers will want to make sure that their respective partners really are the ones they claim to be, i.e. they have to authenticate each other.
Likewise, both publisher and reader will require that the content is authentic, i.e. that is has been really published by the given publisher, and that it is intact, i.e. that nobody has added to or deleted from the package. To be secure from eavesdroppers, the content never should be transmitted and stored in a readable format.
It is often forgotten, but these authenticity and integrity requirements are not only applicable to the content, but also to a contract offer which may accompany the content and which states the terms and conditions under which a reader may use the content. The publisher may want to prove that the reader has accepted the terms, and the reader may want to have a signed copy of what he or is entitled to do.
Once a reader accepts the contract offer, both parties have to adhere to the terms and conditions. This may include the payment and the compliance to the copyright from the publisher's perspective, and the right to use the information from the reader's perspective.
Privacy of the readers may also be very important. No third party, and in some cases not even the publishers or custodians, should be able to track which piece of content is being read by which reader.
Digital library content items can be very large. In this case, it is often useful to decouple the distribution of information and its licensing by distributing encrypted bulk data and controlling the release of content through the key management. Then the distribution can take place over a cheap broadcast channel, and access to the content can be controlled via a separate non-broadcast channel. This separate channel is basically a "key-exchange" between a user's personal computer and a dedicated royalty/license clearing house. All conceivable ways of distributing the actual content data are now enabled; not just Internet, but also digital cable TV, satellite broadcast, CD-ROM publishing, etc. This concept, called "superdistribution" [MoKa90], gives the publisher a very flexible way to use the most appropriate distribution method.
The good news is that current technology provides enough building blocks to satisfy the requirements of both the readers and the publishers:
1. Entity authentication provides for the authentication of publisher and reader.
2. The integrity of content (and of any other information such as the contract offer and acceptance) can be checked using message authentication or by digital signatures.
3. Encryption provides for privacy and confidentiality of the content.
4. Non-repudiation of an offer or contract can be provided by digital signatures (and a non-technical means to enforce the acknowledged contracts).
5. Copy protection of the content can be made at least less fragile by using digital marking on the content to identify the content owner, and/or to identify the user to whom the initial copy was given. Also, the user's computer program (his "viewer") may enforce copy protection. (Of course, this program should be trusted by the publisher and not (easily) tampered with.)
Naturally, there are many ways to deploy these techniques in security systems, and not all of them turn out to be suited for digital libraries.
In a system, there can be many different possible layers for applying encryption: you might apply it at the communication layer, at the application layer, or at the document layer.
By analogy, suppose you want to send a package securely to a friend. You can give it directly to a bonded courier: that would be like the secure communication layer. You can give it to the clerk behind the desk in the Post Office, knowing that the Post Office is committed to end-to-end delivery: that would like be the secure application layer. Finally, you could make the entire package be tamper-proof and give it to the least expensive shipper you can find: that would be like the secure document layer. You can appreciate that there are trade-offs and advantages amongst the different approaches.
There is an alphabet soup of popular (and useful) examples of these ideas in real systems. Secure Socket Layer (SSL) protects the communication layer. Pretty Good Privacy (PGP), Privacy Enhanced Mail (PEM), Secure Multipurpose Internet Mail Extensions (S/MIME), and Secure HyperText Transfer Protocol (SHTTP) all protect the application layer. And finally, in the last section, we will be describing an IBM solution, called "cryptolopesTM", as an example of document protection.
Not every security system is well suited to provide the features required by a digital library. PGP, PEM, and S/MIME are tailored for the protection of electronic mail. Therefore, the following sections discuss and compare the security features of the general-purpose security systems SSL/ SHTTP and cryptographic envelopes.
At the beginning, your browser requested the server's public key certificate (from the server). This had been signed by a trusted agency. Your browser's manufacturer has seeded your browser with the public keys of agencies that you probably want to trust. Since the browser now knows and trusts the server's public key, it can now encrypt data sent to the server. However, rather than sending large amounts of data encrypted with these very slow public-key algorithms, your browser uses a very common technique: it picks a random key, encrypts it with the public key algorithm, sends it to the server, and proposes that the new secret key (called a session key) is used together with a fast symmetric encryption algorithm to protect the rest of the session.
It is also possible that the server could demand that your browser sent your personal public key certificate back to the server, so that it can be sure who it is talking to. Do you have one? If you are like most people, the answer is "no". (This feature has yet to be widely used by servers.)
The key icon does not tell you whether you are using SSL or SHTTP, and in the broad brush above, both are equivalent. Secure Socket Layer, as its name implies, works at a very low level in the Internet Protocol, and all the protocols the Internet uses, like FTP, telnet, HTTP, etc., can be equally protected by SSL. In contrast, SHTTP is restricted to the HTTP protocol, the one used by the Web.
SSL was initially developed by Netscape [FKK96], but is being submitted to the Internet Engineering Task Force (IETF) for validation. SSL is ignorant of the details of higher level protocols, and of what is being transported. This application-independence of SSL gives it much flexibility, but it has the disadvantage that it can only offer point-to-point protection of the data during the communication process itself. In both the source and destination systems, the data is in the clear. It is not within SSL's capabilities to protect the data when a host is compromised, or to detect and fix the problem when a key is compromised.
For some applications, the fact that data in the end systems is not protected by SSL may be OK, e.g. for the transmission of a credit card number -- you must have trusted the system because you would not have sent it your credit card; it is just eavesdroppers on the link you want to forestall. However, when data must be protected beyond the communication process, the application programs would have to do the task -- which would be an inefficient solution.
SHTTP [ReSch97] is more of an application protocol. SHTTP is a superset of HTTP and adds authentication, confidentiality, and integrity. The system is not tied to any particular cryptographic system, key infrastructure, or cryptographic format. Messages are encapsulated within SHTTP in various ways including encryption, signing, or authentication. Messages may encapsulated multiple times to achieve multiple security features. Header definitions for key transfer, certificate transfer, and similar administrative functions are provided.
SHTTP includes support for several key certification schemes. Key certifications can be provided in a message, or obtained elsewhere. As in SSL, client public keys are not required if client authentication is not needed.
A Secure HTTP message consists of a request or status line, followed by other Internet text message headers, and some content. The content can be raw data, a Secure HTTP message, or an HTTP message.
So what is wrong with SSL/SHTTP for protecting the content and the users in the digital library? From the user's point of view, probably not much. In those protocols, your protection against eavesdroppers is excellent. The authenticity of the information is guaranteed, if you trust the server, because you know you are connected to it and not to an impostor. Perhaps the one drawback is that you are at the mercy of the server to describe the relationship: the terms and conditions.
How many times have you gone to a Web site with a URL pointing to its copyright (or even license) terms? Have you read it? If you read it, did you bother to copy it to your machine? Certainly not the latter, we suspect. The trouble is that not only the URL you read, but also its copyright terms, could have been changed by the next time you visit the site. The conditions you agreed to could end up not being the conditions currently displayed. If this bothers you, you would have preferred the conditions you accepted to have been signed and tied to the document you read, so it fixed for all time what you agreed to.
But the major disadvantages of SSL/SHTTP are not to the user, but to the publisher and to the information custodian -- the librarian. In an SSL or SHTTP world, the publisher must run a secure server to guarantee authenticity. Many publishers are discovering that running, maintaining, and supporting servers are not their forte: they want to concentrate on the quality of their information, not to become a computer service bureau. Far better to let someone else worry about how their information gets sent to the end-users.
Secondly, does encryption really provide copy protection? It protects against eavesdroppers, for sure, but the main attacks are likely to be from validly connected end-users who go on to redistribute the received data more than they are entitled to. End-users, of course, must be given the valid keys. Far better to protect content with digital marking (fingerprinting, watermarking). Because SSL and SHTTP both operate at too low a level, they cannot express the concept that a piece of content must be marked.
All the awkwardnesses that SSL and SHTTP present to publishers, they also present to librarians, with some additions. To provide the same integrity and authenticity guarantees to their patrons, the librarians must themselves run a secure server, managing not just the technical aspects the protocols, but also, to be responsible, physically secure environments -- locked rooms, electronic and physical limited access, etc. And how do the librarians possibly track the various terms and conditions of the different publishers and their various items of content?
IBM has coined the name CryptolopeTM (cryptographic envelope) [Cryp97] for its document protection technology. There are others, for example DigiBoxTM[Cass97]. Cryptolopes have been deployed since April 1995 in IBM's infoMarket service. In this D-lib series, they have already been briefly described in [GlLo97]. As shown in figure 1, a cryptolope consists of multiple parts.
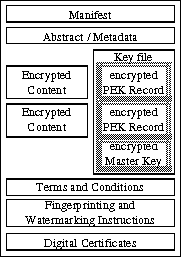
The manifest lists all the other components of the cryptolope together with their cryptographic checksums 2 . The abstract is a clear text description of the encrypted content, which serves to support a user's purchase decision. The metadata gives information about the contents as a whole, e.g. author, size or format. The "real" information is stored in the encrypted content parts. For each part, a different part encryption key (PEK) is chosen. The PEKs are themselves encrypted using a master key and stored in the key records of the key file. The terms and conditions describe the rights associated with the content. Fingerprinting and watermarking are technologies for adding identifying information to documents. Finally, the digital certificates serve the purpose to authenticate the contents and users. [Kapl96]
A cryptolope is created by the publisher of content and can be distributed on arbitrary channels. Its security is inherently guaranteed because everybody can check the checksums and signatures, so nobody can tamper with a cryptolope, and nobody can use the content without purchasing the PEKs.
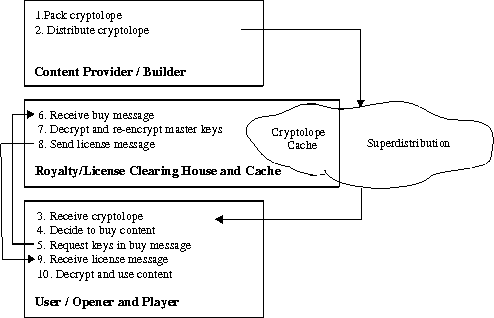
The purchasing transaction requires a clearing house which acts on behalf of the publisher. A client who decides to buy some content is directed by the cryptolope instructions to an appropriate clearing house. The buy request message contains the encrypted PEK and public key certificate. The clearing house knows the master key (which could be its own private key or a shared secret symmetric key), decrypts the PEK and re-encrypts it using the client's public key. After the client received the license message containing the encrypted PEK, it can decrypt it using its private key and use it to decrypt the content itself. Figure 2 depicts the cryptolope process. [LKK97]
A cryptolope-based solution is well suited to meet the DL requirements:
1. Document authenticity can be verified by the client: the librarian is out of the loop.
2. Entity authentication is needed just between client and clearing house: the publisher does not need to have a special relationship (read: userid and password) for each library patron.
3. Every cryptolope and every message is digitally signed and includes the public certificate of the signer, so it can be checked easily. The signature process is explicitly driven by the end user, so the signature can be considered as an act of free will.
4. Checksums and signatures of the content parts let the users check the authenticity and integrity of the content.
5. Each encrypted part is confidential and can only be decrypted by an owner of the key, i.e. the publisher who created this key and the client who buys the key from a clearing house. A clearing house is able to decrypt and sell the key, but generally does not decrypt the content. The information is in clear text only at the publisher's and the client's side, so copyright protection is guaranteed in every component of the communication infrastructure.
6. Since cryptolope processing requires dedicated opener and viewer software running on the client, code signing techniques can be applied to secure also the client side.
The cryptolope processing architecture easily allows a three-tier model. The middle tier consists of a cryptolope cache and a clearing house. Transmission and storage on the one hand and opening and use on the other hand are not coupled, so the middle tier is no threat to a document's security. The deployment of a large network of middle tiers realizes the concept of superdistribution. Clients do not need to get a cryptolope directly and online from a publisher, but can copy a cryptolope from the nearest cache and purchase the unlocking key from any authorized clearing house. In order to realize site-licensing, a clearing house can be authorized by the publisher to unlock cryptolopes for customers of its own domain for free after the institutional subscription fee has been paid. The superdistribution mechanism adds to the privacy of the users, as eavesdroppers can no longer detect which information is unlocked by a client; even deductions from file sizes being transmitted are not possible.
We presented several possibilities for communication security systems and discussed their usability for digital library environments.
We have shown that the common security systems, which are useful to protect less complex, point-to-point transactions, have several weaknesses for digital libraries. On the other hand, secure container technology seems well suited to digital libraries. Secure containers also seem well suited to the old, established roles of information businesses, which more and more tend to be executed by digital means.
[Cryp97] Cryptolope Technology Homepage.
http://www.cryptolope.ibm.com
[FKK96] Alan O. Freier, Philip Karlton, Paul C. Kocher: The SSL Protocol
Version 3.0.
http://search.netscape.com/eng/ssl3/ssl-toc.html
[GlLo97] H.M. Gladney, J.B. Lotspiech: Safeguarding Digital Library
Contents and Users: Assuring Convenient Security and Data Quality. D-lib
magazine, May 1997.
http://www.dlib.org/dlib/may97/ibm/05gladney.html
[Kapl96] Marc A. Kaplan: IBM Cryptolopes, SuperDistribution and Digital
Rights Management. Working Paper, V1.3.0, December 1996.
http://www.research.ibm.com/people/k/kaplan/cryptolope-docs/crypap.html
[LKK97] J.B. Lotspiech, U. Kohl, M.A. Kaplan: Cryptographic Containers and the Digital Library. To appear in: Proc. VIS '97, vieweg Verlag, October 1997.
[MoKa90] Ryoichi Mori, Masaji Kawahara: Superdistribution: The Concept
and the Architecture. Transactions of the IEICE, Vol. E 73, No. 7, July
1990.
http://www.virtualschool.edu/mon/ElectronicProperty/MoriSuperdist.html
[ReSch97] E. Rescorla, A. Schiffman: The Secure HyperText Transfer Protocol.
Internet-Draft, March 1997
http://ds.internic.net/internet-drafts/draft-ietf-wts-shttp-04.txt
[Schn96] B. Schneier: Applied Cryptography, Second Edition. John Wiley and Sons, 1996.
Copies may be printed and distributed, provided that no changes are made to the content, that the entire document including the attribution header and this copyright notice is printed or distributed, and that this is done free of charge.
We have written for the usual reasons of scholarly communication. This report does allude to technologies in early phases of definition and development, including IBM property partially implemented in products. However, the information it provides is strictly on an as-is basis, without express or implied warranty of any kind, and without express or implied commitment to implement anything described or alluded to or provide any product or service. IBM reserves the right to change its plans, designs, and defined interfaces at any time. Therefore, use of the information in this report is at the reader's own risk.
Intellectual property management is fraught with policy, legal, and economic issues. Nothing in this report should be construed as an adoption by IBM of any policy position or recommendation.



hdl:cnri.dlib/september97-lotspiech