|
|
|
| P R I N T E R - F R I E N D L Y F O R M A T | Return to Article |
D-Lib Magazine
September/October 2014
Volume 20, Number 9/10
Cultural Computing at Literature Scale
Encoding the Cultural Knowledge of Tens of Billions of Words of Academic Literature
Kalev H. Leetaru
Georgetown University
kalev.leetaru5@gmail.com (Corresponding Author)
Timothy K. Perkins and Chris Rewerts
U.S. Army Corps of Engineers
{timothy.k.perkins, chris.rewerts}@us.army.mil
doi:10.1045/september2014-leetaru
Abstract
The vast array of academic literature published by the humanities and social sciences disciplines codifies our collective scholarly understanding of how societies function and the beliefs, ideals, and ethnic, religious, and tribal contexts that undergird global societal behavior, yet this material has been largely absent from the recent computational revolution in the study of culture. Applying temporal, geographic, thematic, and citation algorithms to an archive of more than 21 billion words spanning 1.5 million publications from 7 collections, including the entire contents of JSTOR, DTIC, CORE, CiteSeerX, and the Internet Archive's 1.6 billion PDFs, academic literature is seen to offer a powerful new lens onto global culture. Four case studies demonstrate using this archive to map the Nuer ethnic group and identify its top experts, map the literature on food and water security, explore the thematic underpinnings of the Rwandan genocide, and construct a network over the ethnic groups of the world as seen through the combined academic literature of the past half century.
Introduction
As the mass-scale computational study of culture has expanded from digitized books (Michel et al., 2011) to news media (Leetaru, 2011), to social media (Leetaru et al., 2013), to television (Macdonald & Leetaru, 2014), a data source which has remained largely absent is the vast archive of academic literature that forms one of the primary outputs of the humanities and social science disciplines. From Political Science to Anthropology, Sociology to History, Literature to Linguistics, these academic journals chronicle our best scholarly understanding of how societies function and the beliefs, ideals, and ethnic, religious, and tribal contexts that unify or divide civilizations. Yet the size, breadth, and depth of academic scholarship in the humanities and social sciences, the fact that it spans tens of thousands of journals across so many disciplines and specialties, often delving into uniquely characterized and detailed cases, and the increasing use of the web as a publication venue, makes this material far more difficult to consider at scale than other forms of media.
A recent study by the World Bank (Doemeland & Trevino, 2014) reports that more than a third of the reports it produces have never been accessed even a single time. More than three-quarters of its reports have been downloaded less than 100 times and just 13% have ever been cited. There is so much information available today that the majority of it is never seen. No scholar could possibly read every journal article and book published in the past half-century on the Hutus and the Tutsis, let alone map the exhaustive known geography of their mutual interactions or the thematic and societal contexts in which each of those interactions have occurred. Even a large team of scholars would find it difficult to read half a million journal articles on Africa and construct a network diagram visualizing the portrayal of the region's ethnic groups over time. Moreover, the number of distinct disciplines and specialties across which that knowledge is distributed makes it difficult to holistically access a unified understanding of a particular group, topic, or geography. Policymakers, in turn, are unable to comprehensively incorporate this scholarly knowledge into national policy or rapidly identify experts across disciplines to inform key policy discussions.
This study therefore explores the concept of "literature-scale" computational study of culture, extending previous work on the news media (Leetaru, 2011; Leetaru & Schrodt, 2013) to the mass-scale study of the academic literature of the humanities and social sciences, with the goal of improved understanding of populations and the ability to translate the findings of academia into the needs of policymakers (Hargrave et al., 2014). A suite of fully automated algorithms are used to codify the temporal, geographic, and thematic dimensions of each article, along with the works each cites. Africa and the Middle East is used as a geographic case study in that the region has been long been a focus of the humanities and social sciences, is rich in socio-cultural research, yet has a tractable volume of literature covering it.
Data Sources
The academic literature documenting the collective scholarly socio-cultural knowledge of Africa and the Middle East is spread across millions of social sciences and humanities journal articles, government reports, dissertations, theses, and even the open web itself. Analyzing the largest possible fraction of this material required more than a year's worth of discussions, negotiations, and partnerships with a broad array of organizations. The final dataset of 1.5 million documents totaling 178GB and 21.7 billion words was drawn from a total universe of more than 30 million academic articles and more than 1.6 billion web-posted PDFs. The subset of these publications that discuss Africa and the Middle East numbered 959,000 articles totaling 94GB and 13.4 billion words. In all, the seven collections used in this study represent a substantial fraction of the available mainstream academic literature, unclassified and declassified U.S. Government research output, and web-posted content on Africa and the Middle East.
DTIC
The Defense Technical Information Center (DTIC) acts as the central depository service for all unclassified and declassified whitepapers, presentations, technical reports, war college theses, and other defense studies output of all branches of the United States Department of Defense. Operating as the central archive of the U.S. defense community, DTIC offers a unique "single source" repository of a large fraction of the output of the U.S. Government bearing on non-domestic social-cultural issues. While DTIC does not archive all U.S. Government publications, discussions with the Library of Congress, Government Printing Office, National Archives and Records Administration, and many of the agencies producing socio-cultural research indicated that DTIC is the only centralized service that maintains full text electronic copies in PDF format as opposed to only bibliographic citations. It contains a considerable variety of material, from war college theses to policymaking materials to scholarly publications. Among its holdings are 960 translated foreign news summaries and 16,187 translated technical reports from the Foreign Broadcast Information Service (Leetaru, 2010).
After extensive discussion with DTIC, permission was received to use their public OAI interface to compile a master inventory of all publically-accessible DTIC publications, yielding 733,342 citations. Not all documents are available in full text (especially historical materials that have yet to be digitized) and a large fraction of DTIC's material relates to aeronautics, weapons design, engineering, medical, or other technical documentation and reports which are not relevant to socio-cultural research. An iterative process of subject filtering using the DTIC subject headings (Lesser et al., 1993) and manual review of document titles was used to eliminate this technical material, leaving a total of 207,705 documents (28GB of text totaling 4.7 billion words) which were both non-technical and available in full text format. To identify only those documents relating to Africa and the Middle East, the following case-insensitive search was used to locate the names of countries and common nationalities, which returned 93,306 articles totaling 19GB and 3 billion words:
"Africa OR African OR Africans OR Afrikaner OR Afrikaners OR Algeria OR Angola OR Benin OR Botswana OR Burkino Faso OR Burundi OR Cameroon OR Cape Verde OR Central African Republic OR Chad OR Comoros OR Cote d'ivoire OR Ivory Coast OR Congo OR DRCongo OR Djibouti OR Egypt OR Guinea OR Eritrea OR Ethiopia OR Gabon OR Gambia OR Ghana OR Guinea-Bissau OR Kenya OR Lesotho OR Liberia OR Libya OR Madagascar OR Malawi OR Mali OR Mauritania OR Mauritius OR Morocco OR Mozambique OR Namibia OR Niger OR Nigeria OR Rwanda OR Sao Tome OR Senegal OR Seychelles OR Sierra Leone OR Somalia OR Somali OR South Africa OR Sudan OR Swaziland OR Tanzania OR Togo OR Tunisia OR Uganda OR Zambia OR Zimbabwe OR Yemen OR Saudi Arabia OR Oman OR United Arab Emirates OR Qatar OR Bahrain OR Kuwait OR Iraq OR Syria OR Lebanon OR Jordan OR Israel OR West Bank OR Gaza OR Iran OR Afghanistan OR Zimbabwean OR Zimbabweans OR Zambian OR Zambians OR Yemeni OR Yemenite OR Yemenites OR Ugandan OR Ugandans OR Tunisian OR Tunisians OR Tanzanian OR Tanzanians OR Syrian OR Syrians OR Swazi OR Swazis OR Sudanese OR Somali OR Somalis OR Sierra Leonean OR Sierra Leoneans OR Seychellois OR Senegalese OR Saudis OR Saudi OR Saudi Arabian OR Saudi Arabians OR Sao Tomean OR Sao Tomeans OR Rwandan OR Rwandans OR Qatari OR Qataris OR Palestinian OR Palestinians OR Palestine OR Omani OR Omanis OR Nigerian OR Nigerians OR Nigerien OR Nigeriens OR Namibian OR Namibians OR Mozambican OR Mozambicans OR Motswana OR Motswanas OR Mosotho OR Mosothos OR Moroccan OR Moroccans OR Mauritian OR Mauritians OR Mauritanian OR Mauritanians OR Malians OR Malian OR Malawian OR Malawians OR Libyan OR Libyans OR Lebanese OR Liberian OR Liberians OR Kuwaiti OR Kuwaitis OR Kenyan OR Kenyans OR Jordanian OR Jordanians OR Ivorian OR Ivorians OR Israeli OR Israelis OR Iraqi OR Iraqis OR Iranian OR Iranians OR Guinean OR Guineans OR Guinea-Bissauan OR Guinea-Bissauans OR Ghanaian OR Ghanaians OR Gambian OR Gambians OR Gabonese OR Ethiopian OR Ethiopians OR Emirian OR Emirians OR Egyptian OR Egyptians OR Djibouti OR Djiboutis OR Comora OR Comoran OR Comorans OR Chadian OR Chadians OR Cameroons OR Cameroonian OR Cameroonians OR Burundian OR Burundians OR Burkinabe OR Burkinabes OR Beninese OR Batswana OR Basotho OR Bahraini OR Bahrainis OR Afghani OR Afghan OR Afghans OR Angolan OR Angolans"
Figure 1 shows the total volume of DTIC holdings (including all technical and non-full text materials) by publication date, from its earliest publication of 1906 through the end of 2012. Its primary digitization efforts appear to have begun with publications from 1958 and peaked with 1963 reports, but the total volume of DTIC's holdings by year has decreased nearly linearly in the half-century since. This is in marked contrast from most other digital libraries, which exhibit an exponential growth curve, and the lack of significant growth in the born-digital era is of particular note. It is unclear what may account for this steady decrease of material over time and especially the lack of an increase in holdings in the digital era. One possibility is that since only DTIC's unclassified public-access material is examined here it is conceivable that more recent material has a higher volume of restricted content.
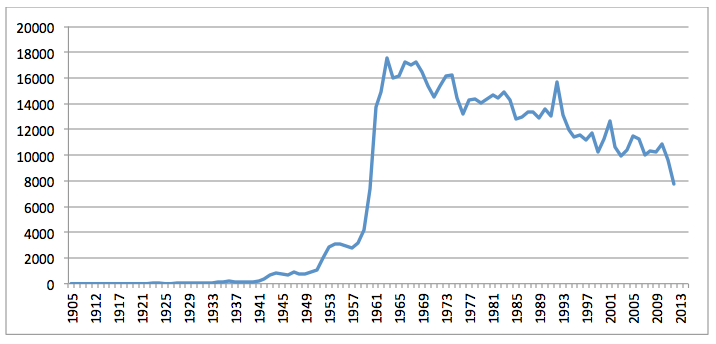
Figure 1: Volume of all DTIC material (including technical and non-full text materials) by publication year
The graph below shows the volume of DTIC full text material mentioning the name of a country in Africa or the Middle East. This shows an even more pronounced peak in 1963, followed by a sharp decline to 1967, increasing linearly from 1982 to 2009, and decreasing steadily since, even as terrorism and other U.S. interests in the area have increased dramatically. Once again, it is unclear what may be driving these trends, though the 1958-1968 spike suggests DTIC may be emphasizing operational U.S. Government needs for material from specific time periods or relating to specific episodes in American interactions abroad.
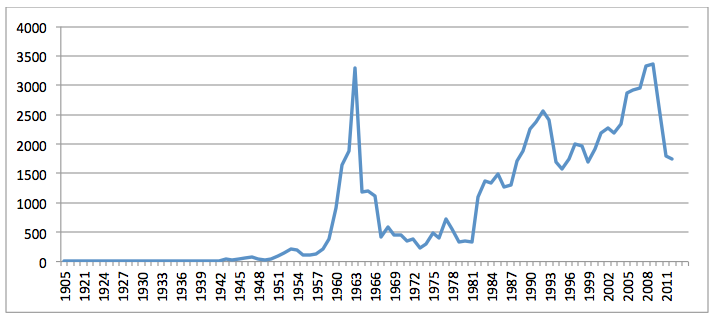
Figure 2: Volume of Africa/Middle East DTIC full text material by publication year
CORE
The CORE project "aims to facilitate free access to content stored across Open Access repositories" and currently aggregates just under 20 million full text articles and citations from several hundred global repositories. In essence, CORE is an effort to create a centralized archive of academic literature from open access journals and repositories throughout the world in order to make it easy to search, locate, browse, and access the world's open academic literature. Of particular interest to multilingual scholars, CORE contains a large volume of non-English material in a variety of languages including Spanish, German, and Russian, though these were dropped from consideration for this project. CORE provided access to a research collection of full text articles of 353,753 documents (49GB totaling 5.9 billion words). Filtering to just the articles matching the list of Africa and Middle East country keywords above and eliminating all non-English material returned 93,926 articles (21GB totalling 3.2 billion words).
The research collection provided by CORE included bibliographic records for 6,639,068 works dating back at least to the year 1000AD and averaging nearly 50 citations per year beginning in the 1500's. The collection enters a period of substantial growth in 1946, accelerating in 1970 and increasing exponentially since, as seen in Figure 3. CORE appears to have the longest period of coverage, but the majority of these entries are only bibliographic records, with no full text available. Figure 4 shows the volume of full text English-language publications in the CORE research collection covering Africa and the Middle East, showing similar exponential growth, though it does not begin increasing until 1960, and has actually shown a decline over the past two years compared with the overall collection's growth.
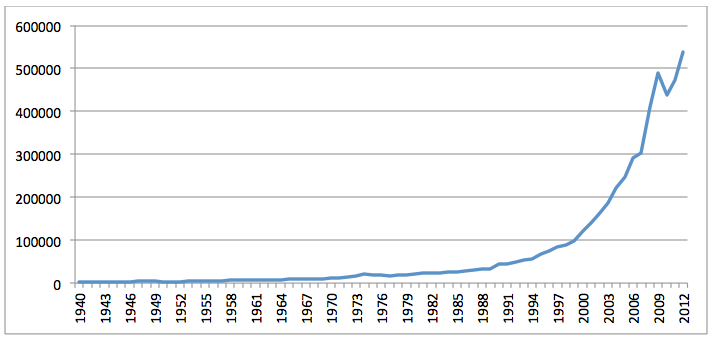
Figure 3: Volume of all CORE bibliographic records by year 1940-2012
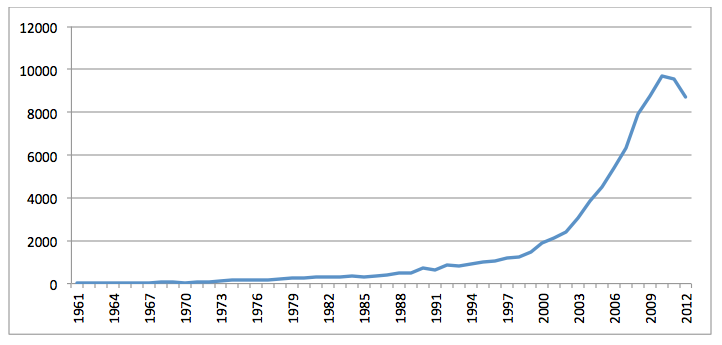
Figure 4: Volume of CORE Africa/Middle East full text articles by publication year
JSTOR
JSTOR is perhaps the best-known centralized archive of humanities and social sciences literature, comprising a digital library of more than 50 million pages, growing by 3 million a year, from over 8 million scholarly publications. Nearly from its creation, JSTOR has served as a rich resource for studying patterns at scale across the academic literature (Bronner, 1999). Unlike the other collections used in this study, which required downloading their entire full text corpus and filtering it post-facto, JSTOR scanned the full text of their entire archive for all documents containing any of the specified keywords and delivered only the set of matching documents. Scholarly studies of Africa and the Middle East published prior to World War II reflect too strong of an ethno-centric view towards the region for the purposes of this study and thus the JSTOR material was additionally filtered to include only articles published on or after 1950. JSTOR also has a rolling window agreement with many of its publishers that makes it more difficult to provide data mining access to articles published in the last several years, so the most recent year for which the full volume of articles are available is 2007.
Figure 5 plots the total volume of articles returned by JSTOR by publication year, exhibiting precisely the kind of linear growth curve one would expect from a large digital library of academic literature. In this case there is no marked increase in the born-digital era because the underlying journals JSTOR aggregates have for the most part not increased their output from the print era. In all, JSTOR provided 667,567 articles (37GB) totaling 4,436,114,056 words from a total of 2,213 journals.
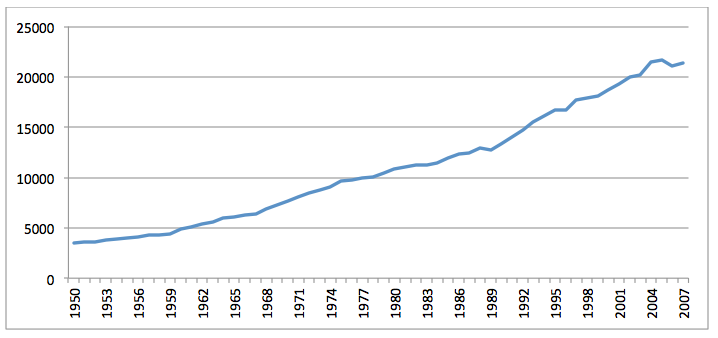
Figure 5: Volume of JSTOR Africa/Middle East articles by publication year
CiteSeerX
CiteSeerX is a digital library of academic literature similar to CORE, but instead of harvesting academic literature from dedicated structured repositories, it crawls the open web searching for public-access PDFs. It focuses primarily on the computer and information sciences, and currently indexes 4.7 million unique URLs. When it encounters multiple copies of a paper at different URLs it records each of those copies and links them together, yielding 3.6 million unique publications. CiteSeerX provided their master URL index, which lists each URL discovered by CiteSeerX and its title.
Scanning both the URL and extracted title of each of the 3.6 million unique publications indexed by CiteSeerX to identify those containing the Africa and Middle East keywords yielded a total of 21,389 documents which were then downloaded (2.1GB of text totaling 255 million words) that both contained a matching keyword and did not return Page Not Found error. The low density of Africa and Middle East-focused material in the CiteSeerX collection reflects its focus on more technology-centric disciplines. The full text of each of these PDFs was then scanned for matching keywords, which yielded a total of 12,583 documents (1.2GB totaling 182 million words). The lower number of final matching documents reflects the high false positive rate when keyword searching URLs, since many words match portions of other words in the absence of word boundaries in most URLs, and demonstrates the critical need to keyword search on the full text of documents, rather than just their URLs.
Unlike JSTOR, CORE, or DTIC, a PDF located on the open web comes with no structured metadata to indicate its title, publication date, publication venue, authors, keywords, or other information. As discussed in the next section, the open source ParsCit software (Councill, Lee & Kan, 2008), the system used by CiteSeerX, was used to automatically identify and extract the title, author, publication date, journal, and other bibliographic information from each document. Unlike robust curated metadata, the metadata computed by ParsCite is based on machine learning algorithms that have a high error rate. In total, ParsCite was able to extract some header information for 10,583 (84%) total documents, for which 1,946 (18%) it could locate a publication year and 8,491 (80%) an author.
Figure 6 shows the volume of Africa and Middle-East related publications by year, illustrating that the archive's holdings on the region largely begin in 1994, with the introduction of Mosaic, the first popular web browser, and exhibit a linear growth curve over the Internet era. The earliest document is a 1947 United Nations publication hosted by the Library of Congress detailing war criminal trials, which contains substantial coverage of German activity in Africa (United Nations, 1947).
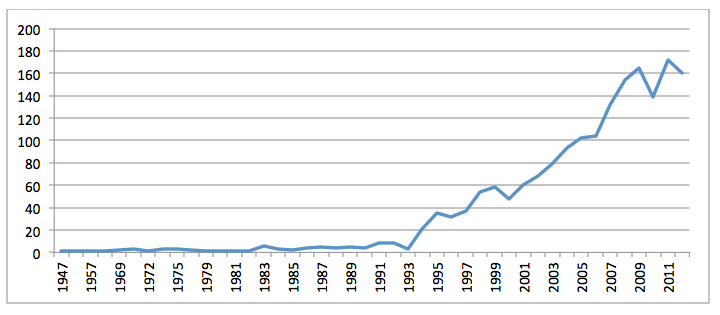
Figure 6: Volume of CiteSeerX Africa/Middle East publications by year (ParsCite extracted publication year)
Internet Archive
The Internet was originally created as a platform for sharing academic knowledge and two decades later it has become an informational nexus of the academic world. Scholars post reprints of their publications on their websites, while governments and Non-Governmental Organizations increasingly share their findings and reports online. The open web therefore would appear to be an ideal archive of academic literature, and services like Google Scholar and CiteSeerX have demonstrated the feasibility of this approach. However, the computational resources required to scour the web at scale for academic literature PDFs are simply not available to most scholars.
The Internet Archive was created in 1996 to, as its name suggests, archive the web to preserve its evolution for future generations. Today its 19 petabytes preserve over 407 billion web pages collected over 18 years, including 1.6 billion PDF files. The Archive's enormous breadth and its nearly two-decade timespan offers the tantalizing concept of the ultimate "internet scale" platform for scholarly research. Could the web itself, as recorded through the eyes of the Internet Archive, be used as a data source?
Making this a reality, the Internet Archive recently unveiled its new Virtual Reading Room concept (Macdonald & Leetaru, 2014), designed specifically to permit secure large-scale scholarly and journalistic data mining of the Archive's collections while maintaining the Archive's responsible stewardship of content created by others. To explore the ability of the Virtual Reading Room to support large-scale data mining over the web itself, the 1.6 billion PDF files preserved by the Archive over the last 18 years were examined to find ways of identifying academic literature. Unfortunately, at this time the Internet Archive does not yet have the computing resources to extract and index the full text of all 1.6 billion PDFs to make it possible to keyword search their contents in a tractable manner. Thus, for this project, only the URLs of each PDF could be scanned. Two different methods of searching for academic literature were conducted: one focusing specifically on URLs containing keywords related to Africa and the Middle East and the second focusing on URL keywords relating to graduate student dissertations and theses.
The first approach involved scanning the complete list of 1.6 billion PDFs against the list of Africa and Middle East keywords to locate matching URLs, similar to the search done for CiteSeerX, but without CiteSeerX's ability to also search the extracted title of each document. This returned 12,960,006 total PDFs from 309,498 different domains. However, a manual review of 2,000 randomly-selected documents indicated that the majority were not related to academic literature. For example, the website hosting the most matching URLs was "usaid.gov" with 700,062 PDF files. The majority of these now yield "Page Not Found" errors, having been housed under discontinued branches of the website. (In the future it will be possible to retrieve these PDFs from the Archive's historical snapshots, but at this time the computational resources required to do so at this volume of material were intractable.) The remaining PDFs are largely budget reports and technical summaries of programs written from a U.S. policy execution perspective, rather than factual descriptions of events or knowledge on the ground. Another top domain, "who.int" contains 309,630 PDFs, yet once again they are almost exclusively budgetary summaries, data collection survey instruments, and highly technical medical reports. Even U.S. Government websites, such as the US Senate, with 56,640 reports and U.S. State Department, with 53,429 PDFs, similarly emphasize domestic U.S. interactions with foreign states, such as financial statements, summaries of U.S. interactions, proposed regulations, and contract instruments. Numerous commercial websites listing their offices, advertisements, and price sheets for customers on the continent of Africa, and news reports from across the world with an African country in the article URL also feature prominently in this list.
To identify just academic studies from this list, an iterative process based on extensive manual review and repeated random sampling of the collection was used to develop a set of URL keywords most indicative of academic publications. The final list consists of 31 keywords, one of which must appear somewhere in the URL in addition to one of the African or Middle Eastern keywords for the URL to be considered potentially relevant academic literature:
"course" OR "class" OR ".full.pdf" OR "library" OR "reading" OR "~" OR "/files/" OR "/handle/" OR "download" OR "bitstream" OR "webdav" OR "journal" OR "chapter" OR "fulltext" OR "article" OR "faculty" OR "research" OR "docs" OR "openaccess" OR "readings" OR "pubs/" OR "seminar" OR "conference" OR "/files/" OR "uploads" OR "workingpaper" OR "working" OR "publication" OR "paper" OR "document" OR "collections"
In addition, any URLs containing "k12", "brochure", "flyer", or "product" were excluded to remove primary school materials and commercial publications. This yielded 96,206 remaining URLs, of which 48,605 (51%) still functioned, totaling 2.3GB (277 million words). The full text of each of these documents was then extracted and scanned against the keyword list as was done with the CiteSeerX material, yielding a final list of 36,131 articles (1.5GB totaling 232 million words).
As before, the ParsCite software was applied to each document to identify and extract its publication date and list of authors. In this case there was no measurable difference between the original set of 48,605 PDFs and the final set of 36,131 articles. ParsCite generated output for 35,331 documents (98%), of which 4,638 (13%) had a recoverable publication year and 14,833 (42%) had author information. The earliest robust publication year was 1970, which included the "Madison Area Committee on Southern Africa" newsletter detailing a visit from two representatives of the Front For the Liberation of Mozambique ("MACSA News", 1970).
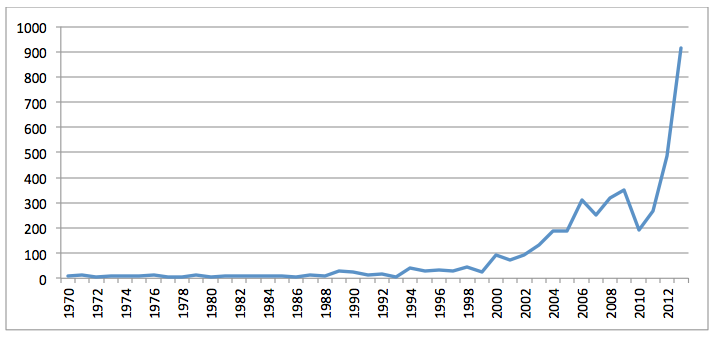
Figure 7: Volume of publications recorded by the Internet Archive containing Africa/Middle East keyword in URL by year (ParsCite extracted publication year)
Unlike CiteSeerX, which shows linear growth beginning in 1994, the Internet Archive's holdings matching these keywords do not begin to increase substantially until the year 2000 and enter a hyper-growth period beginning in 2011. One possible explanation is that the CiteSeerX dataset contains both the URL and extracted title for each work, while the Internet Archive provides only the URL of each PDF. Upon further analysis, it was determined that 80% of the CiteSeerX keyword matches came from a match on the extracted title, while just 24% came from matches on the URL (some matched on both fields). This is a critical finding in that during the early days of the web URLs were often shorter and less descriptive, with the practice of long filenames containing the complete title of a work being a fairly modern development to boost search engine rankings.
The different timelines presented by the CiteSeerX and Internet Archive graphs suggests that searching for regional keywords in the URL of a PDF will not only miss 80% of potential documents, but will also skew those that do match towards more recent material. Given historical URL naming conventions, it is likely that a large fraction of the academic literature published on the web about Africa and the Middle East over the last 18 years does not contain relevant keywords in the URL itself. To explore this in more detail, the second search of the Internet Archive's PDF repository involved locating and downloading a large body of academic literature and then performing full text search on these articles to identify ones relating to the region.
Graduate student doctoral dissertations and masters theses are a particularly rich source of academic discourse and often present the results of unique research or fieldwork. Of particular importance, extensive review of the Archive's 1.6 billion PDF URLs indicated that URLs containing the keywords "dissertation" or "thesis" were primarily actual dissertations or theses and would return a large volume of material with a fairly low false positive rate. After removing URLs containing the keywords "handbook", "forms", "checklist", "check%20list", or "formatting" (to exclude the copious guidelines and other documentation issued by every university's graduate college), this resulted in a list of 604,482 URLs, of which 222,870 (60GB totaling 6 billion words) still functioned. It is important to note that just 37% of the dissertation and thesis URLs preserved by the Internet Archive since 1996 still work in 2014, while 51% of URLs containing one of the regional keywords still work. This demonstrates the tremendous link rot that plagues the web and the critical role that the Internet Archive plays in preserving the web. In this case URLs that did not return a response were dropped from consideration, but in the future the Internet Archive, through its Virtual Reading Room, will support large-scale access to its archived copies of pages that are no longer available.
Even with the reduced size of a quarter-million documents, this represents one of the largest collections of such material outside the handful of commercial publishers that control access to much of the world's dissertations and theses. Keyword scanning the full text of these documents yielded a total of 53,088 documents (14GB totaling 2.2 billion words) discussing Africa or the Middle East. Of these, just 1,101 (2.1%) contain a matching keyword in the URL, illustrating the critical importance of moving beyond URL searching to identify the literature of a field. It also suggests that to use the web as a research platform will require the ability to conduct full text searches over the Internet Archive's collections.
For the full set of dissertation materials, ParsCite generated output for 209,455 documents, of which 54,054 (26%) had recoverable publication dates and 133,123 (64%) had author information. Extracted dates appear to be relatively error-free at least back to 1959, including a master's thesis on the "Thermodynamics of the Steady State" by Ted Allen Erikson at the Illinois Institute of Technology (Erikson, 1959). Figure 8 shows the volume of dissertations and theses by year, showing exponential growth beginning in 1990 and continuing through 2004. Surprisingly, publication volume then decreases linearly through present (just short of its late 1980's levels). It is unclear what could be causing this, whether this reflects a change in the formatting of dissertations and theses that ParsCite encounters difficulty with, changing standards in URL naming conventions on the web, changing norms on releasing dissertations and theses to the open web rather than publishing them in journals or as books, or whether this may reflect some kind of change in how the Internet Archive archives the web. The fact that this trend is not seen when scanning for geographic keyword matches on the URL or in CiteSeerX suggests this is something unique to dissertations and theses. Further research will be required to understand this decrease, but similar to CiteSeerX, dissertations and theses on the open web largely begin around 1990, meaning that using the web as an open archive of literature will skew heavily towards modern publications.
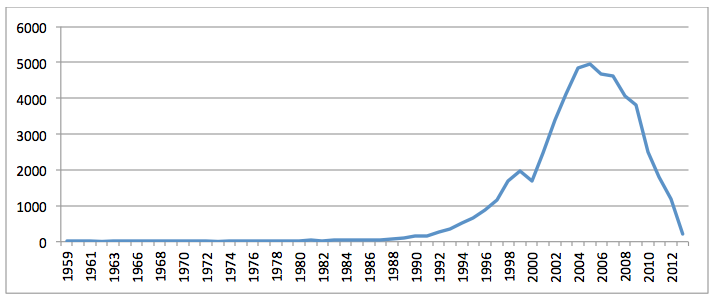
Figure 8: Volume of dissertations and theses recorded by the Internet Archive containing "dissertation" or "thesis" in URL by year (ParsCite extracted publication year)
Narrowing to just dissertations and theses containing the Africa or Middle East keywords in the body of the text, ParsCite was able to recover publication dates from 18,368 articles (35%) and authors from 40,627 (78%). The resulting curve is identical to that of dissertations as a whole, indicating there are no unique temporal patterns in Africa-related material and the decrease in publication volume since the mid-2000's occurs across multiple topics.
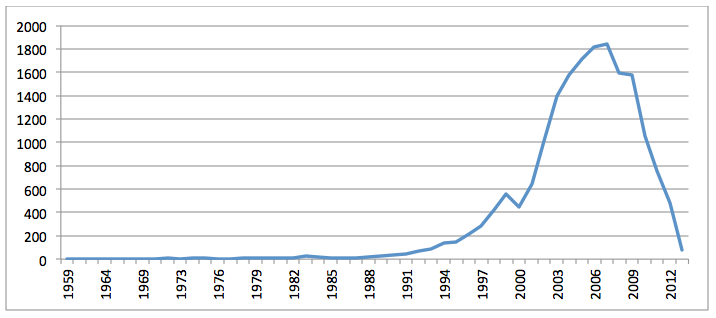
Figure 9: Volume of dissertations and theses recorded by the Internet Archive containing Africa/Middle East keyword in URL by year (ParsCite extracted publication year)
Combined with the results from CiteSeerX it is clear that web-based academic literature archives are biased heavily towards the web era, with comparatively little coverage of previous decades. While CORE aggregates directly from open access journal repositories, the open access community is still a product of the Internet and thus even CORE's holdings skew towards the modern era. Only JSTOR, which has digitized the complete runs of the journals it holds, has strong historical coverage and demonstrates that aggregate growth over the scholarly output on Africa and the Middle East has been linear over the past half-century.
Throughout this paper the two Internet Archive collections of Africa/Middle East content, those compiled from dissertations, and those compiled from a keyword search of URLs for country names, will be examined independently to explore whether there are fundamental differences in their content.
CIA.gov
Agencies of the United States government (".gov" websites) account for more than a quarter (434 million) of the 1.6 billion PDFs preserved by the Internet Archive, while U.S. Military (".mil") websites account for a further 6.9 million PDFs. In total, the Archive holds more than half a petabyte of the U.S. Government's web presence dating to 1996. Over the course of identifying websites and keywords indicative of academic literature from the Archive's holdings, it emerged that the United States Central Intelligence Agency (CIA) has one of the largest collections of academic literature PDFs on its website of all U.S. Government agencies. A further analysis of this collection demonstrated that unlike the U.S. State Department and other U.S. Government agencies, the CIA's holdings primarily report on events and findings from the ground. Its archive stretches back more than 70 years and contains the largest repository of declassified U.S. Government intelligence and military documents on U.S. operations and intelligence gathering throughout the globe in the twentieth century.
Primarily digitized unclassified and declassified intelligence assessments and briefings, the CIA's PDF archives contain one of the richest selections of scholarly literature of the U.S. Government, second only to DTIC. Most critically, unlike DTIC, the majority of the CIA's archives consist of previously classified intelligence assessments, providing the U.S. Government's most detailed understanding of cultural interactions and conflict throughout the world. Excluding the CIA's map archive (which contains no text) and its two contemporary public-focused publications (the CIA World Factbook and the CIA Chiefs of State series), there were 39,247 PDF files found on its website. Of these, 28,591 PDFs were recovered from a combination of crawling the open web and a pilot search of the Internet Archive's archives for any snapshots it may have made of the files over time.
When declassifying documents, the CIA appears to have primarily posted raw page scans instead of using Optical Character Recognition (OCR) to convert the scanned documents into searchable text. Just 7,943 (28%) of the PDFs had undergone OCR conversion, totaling 512MB of text (80 million words). Searching the full text of these documents for the Africa and Middle East keywords yielded a final list of 2,334 documents (353MB totaling 49 million words). Even when the CIA did OCR documents, the quality of the recognized text is extremely poor and sample tests running documents through modern commercial OCR software yielded dramatically better results. Based on this, the Internet Archive is in the process of creating a special research collection of the CIA material that includes processing the entire collection through the latest generation of OCR software to dramatically improve the collection's accessibility to both data mining and human search.
Despite the heavy OCR error, ParsCite was able to identify a publication date for 903 (11%) of the searchable PDF files, though the software proved unable to accurately recognize author information and thus this field was dropped from consideration. Figure 10 shows the volume of CIA.gov publications since 1946, the earliest robust publication year identified by ParsCite, though a manual review of CIA materials suggests material earlier than 1946 is present in the collection. Like the previous web-based collections, CIA documents show a dramatic increase in volume beginning in 1999 and continuing through present.
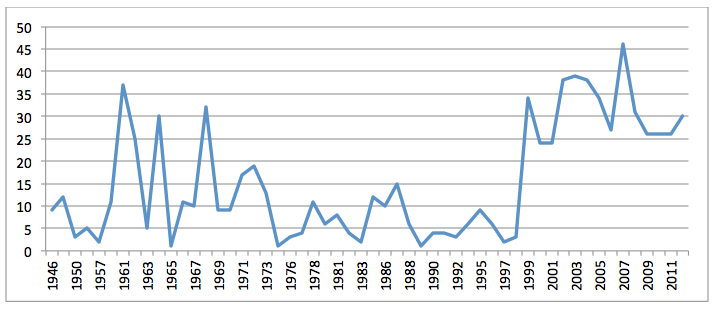
Figure 10: Volume of CIA.GOV publications by year (ParsCite extracted publication year)
Methodology
All seven archives were processed using two suites of software: the lead author's GDELT Project Global Knowledge Graph and the ParsCite (Councill, Lee & Kan, 2008) citation extraction system. The GDELT Global Knowledge Graph (GKG) is a software suite that codifies the world's mainstream news media each day to compile a list of people, organizations, locations, dates, themes, and counts, recording them into a semantic graph that enables the underlying latent structure of the news media to be explored. Leetaru (2012) provides more detail on the underlying algorithms used, while (Leetaru, online) provides a list of the 235 topical themes that the system currently recognizes. Of particular relevance to this project, among its list of recognized topics is an extensive list of the world's ethnic and religious groups. The system has increasingly been applied to a range of materials, from Wikipedia (Leetaru, 2012), to Twitter (Leetaru et al., 2013), to half a million hours of American television news programming (Macdonald & Leetaru, 2014). Applied to academic literature, the GDELT GKG system offers a rapid surface-level summary of the major geographic, temporal, thematic, and social-group focus of the scholarship on Africa and the Middle East.
Historically, one of the most common ways large academic literature collections have been explored is through the lens of their citations, using the networks of who-cites-whom as a proxy into the structure and organization of a field (Pritchard, 1969). The semantic knowledge extracted from the contents of the articles is therefore combined with a more traditional citation graph of all of the works cited across the collection, using the ParsCite system. As noted earlier, ParsCite extracts two types of information from each article: its metadata (title, author, publication date) and its references list (the set of works it cites). ParsCite was originally used in this study to provide publication metadata for web-based academic articles, but its ability to additionally compile a parsed list of all of the works cited by the articles was leveraged to compile a citation graph over the literature. ParsCite also has the ability to extract the text surrounding each in-text citation, allowing the context of how a work is cited to be explored. This was not utilized in this study, but offers future capability to potentially determine whether a work is cited in an affirmative manner (agreeing with its findings) or dissenting manner (rejecting its findings). In total, 34,871,289 citations were extracted from the collection, 23,905,060 of which came from articles covering Africa and the Middle East.
The Timeline of Culture
The lens of time provides at once a powerful and simple way to explore the literature on Africa and the Middle East. How rapidly does new knowledge enter the field and how recent are the events it focuses on? The entrance of new knowledge into a field can be measured through the average number of years that elapse between when a work is published and when it begins to be frequently cited in subsequent papers. Similarly, the "age" of events discussed by the literature can be measured by extracting all temporal references from a text and measuring the average distance in years between the publication date of the paper and the dates it discusses.
The Entrance of New Knowledge
Both the volume and accessibly of scholarship has dramatically increased in the internet era. Yet, will the greater availability of more recent publications lead them to be cited more often than older literature? Figure 11 tallies the publication date of all cited works in articles from JSTOR, plotting the total number of works published by year that were cited in a subsequent paper. Beginning with the close of World War II in 1945 (just before the 1950 start date used for the JSTOR material in this study), the number of works published each year that are cited in later papers increases linearly through a peak in 1993 and have declined linearly ever since.
This sharp decrease is puzzling until the citations are grouped by the publication date of the article citing them. The average publication year of all of the works cited by papers published in a given year is 13.1 years prior, a number which has barely changed over the entire 57 year period of the JSTOR data examined. Thus, the reason for the sharp drop-off in citations to works after 1993 is that the JSTOR dataset provided for this study largely ends in 2007 (~13 years later), with far fewer publications in the 2008-2013 time period. As the following section will examine in more detail, this is due to a long-tailed distribution in which papers emphasize discussion of more recent literature, but still reference many key older works, even in the information sciences, where seminal papers may date back decades. Yet, the fact that this average has remained largely unchanged over the entire 57 year period, despite the rise of the web over the last quarter of that period, indicates that even with the greater availability of born-digital works, citation patterns have not dramatically changed over time.
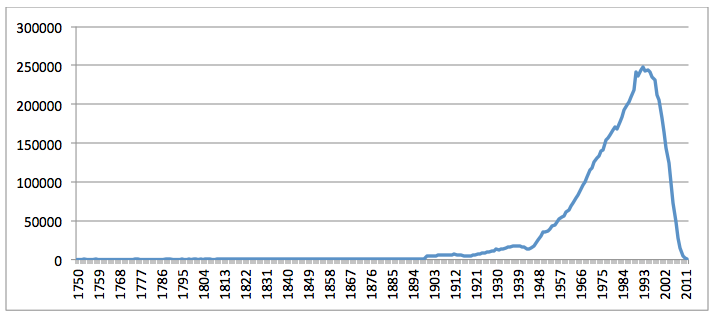
Figure 11: Citations by year of cited work in JSTOR
Repeating this analysis for the other collections yields similar results. When the entire CORE collection is considered, the average distance between the publication date of an article and those of the works it cites is 13.7 years, increasing to 15.7 years for just the Africa and Middle East materials. DTIC has a shorter distance of 8.5 years for all materials and 9.8 years for its Africa and Middle East content, while CiteSeerX exhibits a distance of 9.7 years. Dissertation materials have a distance of 10.8 years overall and 12.1 years for Africa and Middle East, while non-dissertation material has a distance of 8.3 years. Although the distance is slightly less for web-posted material, it averages around 13 years for the major humanities and social sciences journals.
The Synthesis of Knowledge
Citation-based date analysis captures the average age of the knowledge invoked by a paper to support its arguments, but does not offer insight into the age of the events actually discussed in the paper: a 13-year-old paper could be cited to discuss events from 13 years ago or 100 years ago. To explore the age of the knowledge actually captured in the scholarly literature on Africa and the Middle East, all date mentions were extracted from the full text of each article. For the purposes of this study, every date appearing in the text was preserved, including those occurring within a citation reference. Thus, "Smith (2001)" will result in a date reference of 2001 being recorded. This is due to the significant number of ways in which dates can occur in textual citation references, such as "as Smith discusses in his 2001 article", which would be difficult to robustly filter across the vast diversity of styles found in the collection.
More importantly, often a citation date is the only temporal information provided for a given claim such as "The genocide against the Tutsis resulted in the death of 20% of the Rwandan population (Dorsey, 1994)". Tests on a random sample of 200 articles in which all citation references and page numbers were removed by hand resulted in a correlation of r=0.88 for the period 1800-2014, indicating that including dates resulting from textual citations does not measurably alter the findings of this section. It also indicates that the presence of page numbers in the body text of articles due to OCR error does not substantially skew the results. This is likely due to the wide distribution of articles across the available page range of journals, meaning articles are not more likely to appear on a specific set of pages over a universe of material this large.
Table 1 displays the total number of date references extracted from each collection and specifically the percent of those that mention a day-level date (such as June 1, 1982) or month-level (June 1982) rather than only a year-level date. DTIC has the highest prevalence of day-level date mentions, at 2.13%, while the CIA archive has the highest presence of month-level dates, at 0.84%. Unfortunately, this finding holds especial importance for the ability to use socio-cultural indicators encoded in the academic literature to detect temporal features such as important cultural dates that might spawn "anniversary violence" in which groups clash on a specific date each year. It also demonstrates that the temporal resolution of academic literature is insufficient to compile lists of "events" such as riots or military attacks (Leetaru & Schrodt, 2013) as a possible supplement to news media coverage. In place of the day-by-day chronology of the news media, the academic literature appears to focus on annual-level macro synthesis of those behaviors and their underlying connection to their socio-cultural underpinnings.
Table 1: Number and resolution of extracted dates from article text by collection
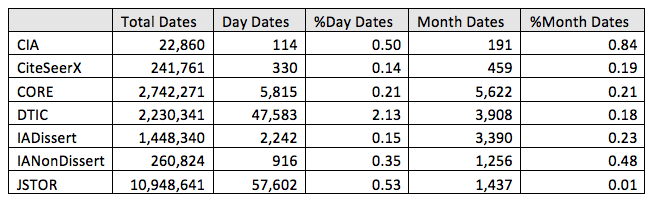
Figure 12 displays how many times dates in each year 1935-2012 were mentioned in articles from each collection, offering a timeline of the "age" of the knowledge captured in the scholarly literature. The year 1935 was selected as a starting point as there were insufficient mentions of dates from previous years across the collections. To display all seven collections on a single graph, the raw number of date mentions has been converted into a "Z score" (number of standard deviations from the mean).
Most striking about this graph is that only the CIA, JSTOR, and DTIC archives provide substantial discussion of historical events, with the web-era collections focusing on the post-1970 period, but not really increasing until around 1980 and peaking around 2000. This emphasizes the incredible value of digitization, in that making historical content available requires expensive digitization, scanning, OCR, and conversion, but is the only way to ensure substantial coverage of older events. It is noteworthy that the two Internet Archive collections do not show exponential rises in coverage of the web era and instead exhibit an exponential growth curve beginning around 1970.
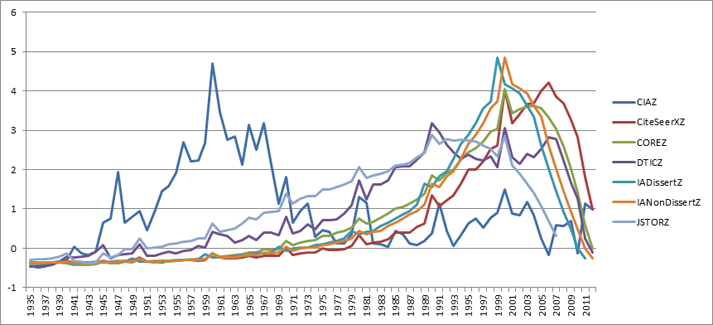
Figure 12: Number mentions of each year in article text by collection (Z-Score)
Figure 13 expands upon this for JSTOR by calculating the temporal distance of each article's publication date from the average year of all date mentions within the text, and averaging this by year. In other words, it displays the average "age" of the information discussed across all articles published each year. The remarkable uniformness of this graph, barely straying from an average of 35.4 years over the entire half-century of the dataset provides strong evidence that textual citations, page numbers, and other extraneous numeric references do not affect the results, as otherwise the graph would skew closer to the 13 year average distance of citations, or would skew over time if it was based on page numbers. Most critically, it suggests that the greater volume and accessibility of born-digital information about modern events in the post-web era has not caused a corresponding shift in the literature towards increased discussion of the present at the expense of the historical past.
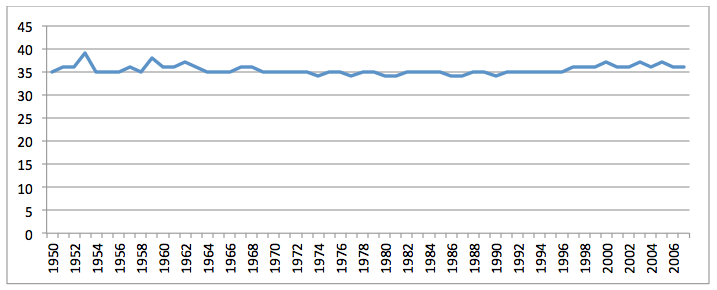
Figure 13: Distance in years between publication date and average date mention in article
Examining a single year in more detail, Figure 14 shows the total number of times dates in each year 1900-1975 were discussed in papers published in 1975 contained in the JSTOR collection. An exponential falloff can be observed in which papers published in 1975 discuss recent events more often than older events, with the number of mentions of a date declining by age. Mentions of dates during World War II are considerably fewer than the surrounding years, marking one of the few deviations from this pattern. The long tail of this curve, which continues through dates from most of the nineteenth century, accounts for the large average delay in that papers bias towards more recent knowledge, but contextualize that knowledge within a time period spanning centuries. Given the remarkable uniformity of Figure 13, it appears this long-tailed distribution has remained largely constant over the past six decades, changing little even with the greater availability of born-digital information on the modern era. Repeating this for the other collections, CORE averages 39.5 years, CiteSeerX 26.8 years, IA Dissertations 34.4 years, IA Non-Dissertations 21.0 years, JSTOR 35.4 years, and DTIC 29.2 years. The number of CIA documents with a recoverable publication date was too small to yield valid results for this analysis, so the collection was excluded.
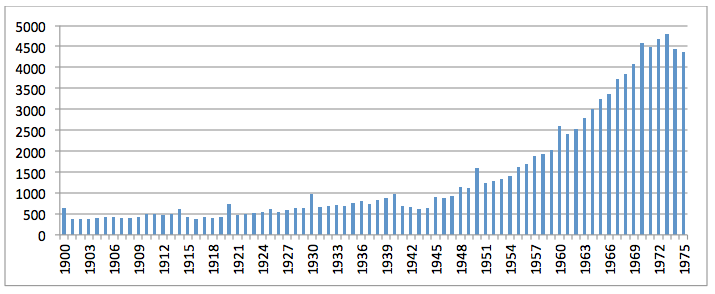
Figure 14: Number mentions of each year in article text of JSTOR articles published in 1975
The Geography of Culture
To explore the geography of the collection, full text geocoding was used to identify and disambiguate all textual mentions of over eight million locations in the world using the algorithm from Leetaru (2012). This algorithm is well-suited for academic literature, having been previously applied to the entire English Wikipedia corpus and most recently the Internet Archive's Television News Archive of 2.7 billion words of closed captioning (Macdonald & Leetaru, 2014). To provide a baseline comparison of major world events, all quarter-billion records from the GDELT Project (Leetaru & Schrodt, 2013), which catalogs more than 300 categories of "events" from the global news media, were filtered for those occurring in Africa and the Middle East. This allows an exploration of whether the academic literature and news media share a similar geographic focus.
Collection-Level Geography By Country
The following sequence of charts examine how the collections compare with each other at the country level, measuring the percent of their articles that mention one or more locations in each country. This normalizes for the possibility of different geographic resolutions (one collection having more city-level references while another has more province-level mentions) and focuses on the macro-level geographic distribution of coverage. With 65 countries it would not be possible to display all countries in a single chart, so all countries were ranked by the total percentage of focus across the seven collections and the top 25 countries overall are displayed.
A key pattern that emerges is the strong imbalance of the CIA and DTIC collections on countries of specific interest to United States policy. While not unexpected, this does suggest U.S. Government socio-cultural scholarship (at least that which is unclassified or declassified) is strongly operational in nature, focusing on U.S. policy interests, rather than more evenly spread across the world. It argues that such literature may be of especial interest to military planners in that it deeply covers many specific areas of interest. However, it also paints a picture of a relatively narrow lens of interest towards socio-cultural research by the government.
JSTOR, CORE, and Internet Archive dissertations, on the other hand, show increased attention to Israel, Egypt, and South Africa, but other than those three countries, do not appear to skew towards any particular set of countries or regions. The data here are not sufficient to tease out whether this is because scholars are balanced in their study of these countries or whether it is because journal editors or reviewers ensure even balance, but the end result is that the literature as a whole, spread over more than 2,200 journals and the open web, is relatively balanced across countries.
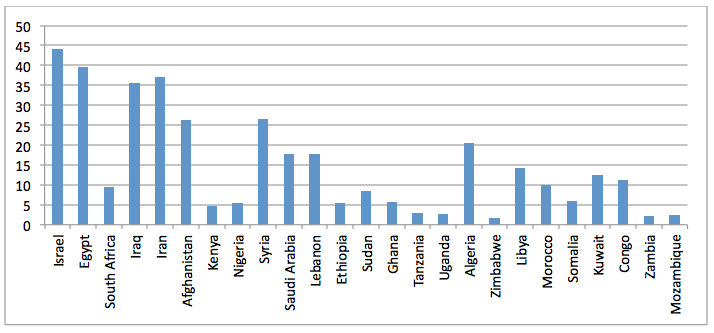
Figure 15: Percent CIA Africa/Middle East articles mentioning the top 25 countries
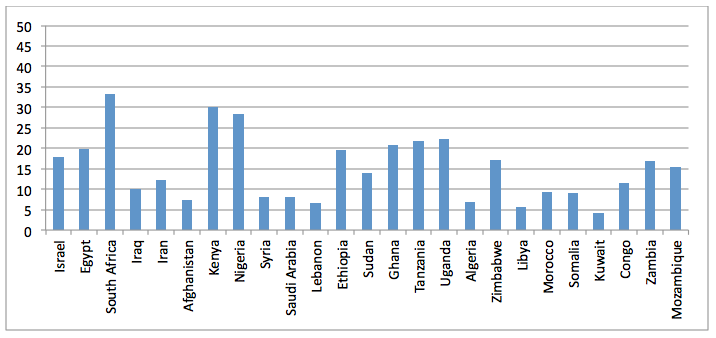
Figure 16: Percent CiteSeerX Africa/Middle East articles mentioning the top 25 countries
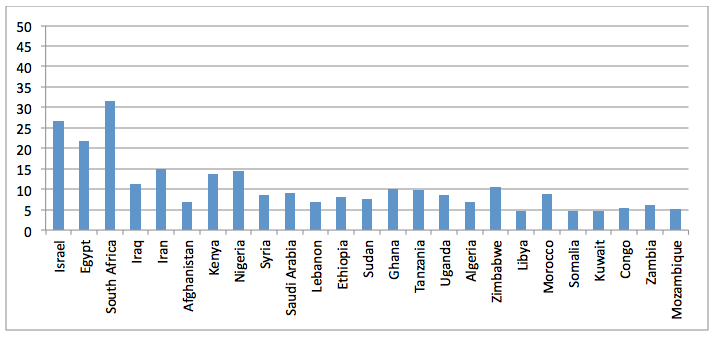
Figure 17: Percent CORE Africa/Middle East articles mentioning the top 25 countries
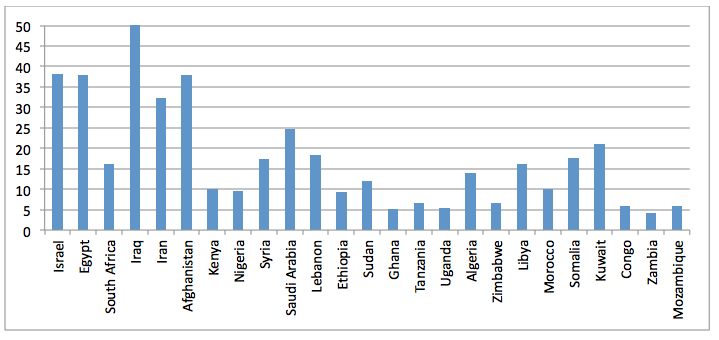
Figure 18: Percent DTIC Africa/Middle East articles mentioning the top 25 countries
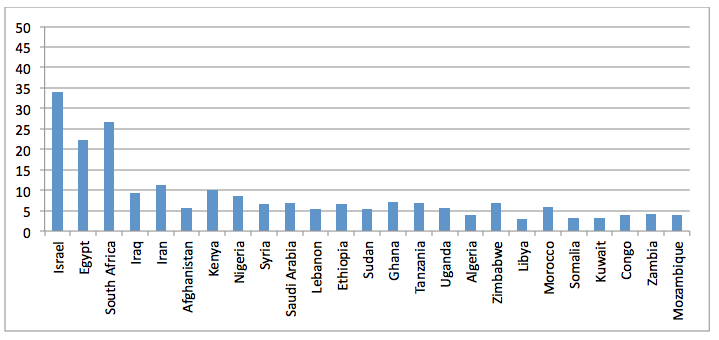
Figure 19: Percent Internet Archive Dissertation Africa/Middle East articles mentioning the top 25 countries
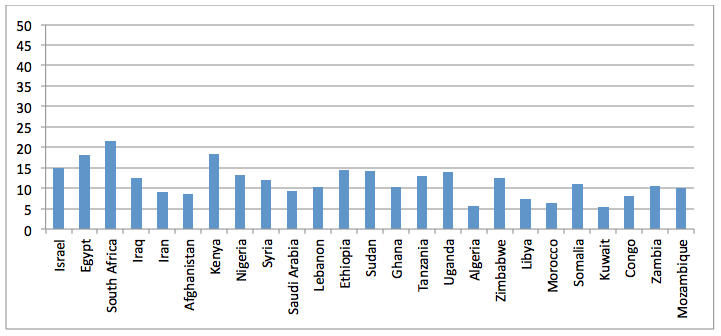
Figure 20: Percent Internet Archive Non-Dissertation Africa/Middle East articles mentioning the top 25 countries
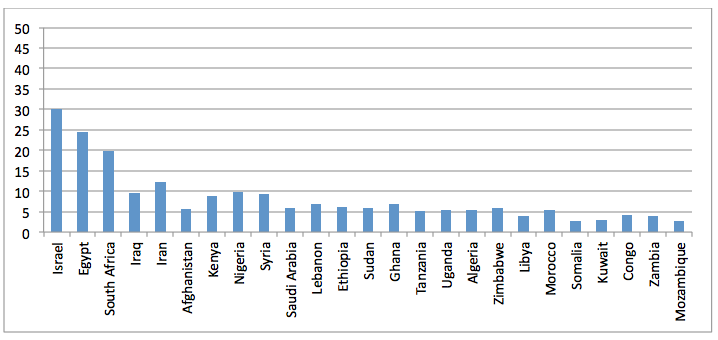
Figure 21: Percent JSTOR Africa/Middle East articles mentioning the top 25 countries
To determine whether this is driven by population, the July 2013 population of each country was compiled (United Nations, 2013) and the intensity of discussion of each country across the seven collections compared. The most correlated is CiteSeerX at r=0.63, followed by Internet Archive Non-Dissertations at r=0.55, CORE at r=0.51, JSTOR at r=0.44, GDELT at r=0.40, Internet Archive Dissertations at r=0.38, and DTIC and CIA, both at r=0.31. It is clear that population alone is not the strongest factor determining the distribution of geographic focus and that for U.S. Government publications it has even less influence.
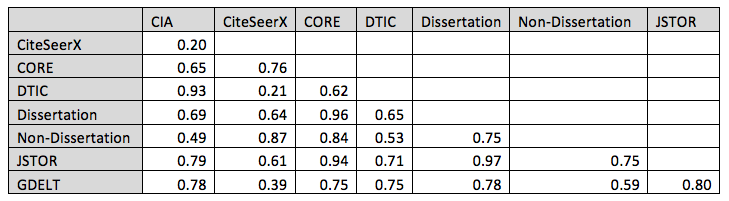
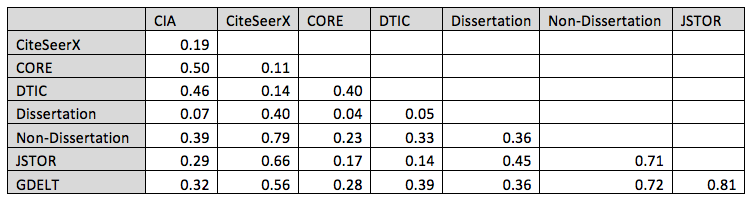
Table 2 expands upon the charts above by measuring the country-level correlation of the collections with respect to one another, examining their distribution over all 65 countries. Pearson correlations are an especially valuable way of comparing two datasets in that they ignore the total volume (one dataset being larger than another) and look instead purely at the relative distribution of their coverage across countries. Only two comparisons, CiteSeerX - CIA and CiteSeerX - DTIC, did not yield statistically significant correlations. The highest four correlations were Dissertations — JSTOR (r=0.97), Dissertations - CORE (r=0.96), JSTOR — CORE (r=0.94), and CIA — DTIC (r=0.93) all of which reflect nearly perfect correlations. The strong alignment of geographic focus of JSTOR, CORE, and Dissertations argues both that dissertations reflect academic literature trends and that more recent material (born-digital CORE holdings) do not exhibit a substantial geographic deviation from JSTOR's half-century historical archive. The alignment between CIA and DTIC content is unsurprising and reflects the strong overlap between the socio-cultural focus of the intelligence and military communities towards areas of U.S. policy interest.
Table 2: Correlation of each collection based on percentage of articles mentioning each country
City-Level Comparison
Country-level analysis is too coarse to truly understand the overarching cultural geography of the academic literature and thus Table 3 shows the total number of city and landmark-level location mentions by collection, along with the density of location references. Both the JSTOR and CIA collections fall within the average of a location every 200-300 words found in news media coverage (Leetaru, 2011). A manual review of around 100 articles suggests the higher density of locations in some collections seems to be a combined reflection of locations featuring heavily in their citation lists and increased use of tabular listings that discuss locations.
Table 3: City/Landmark-level location mentions by collection
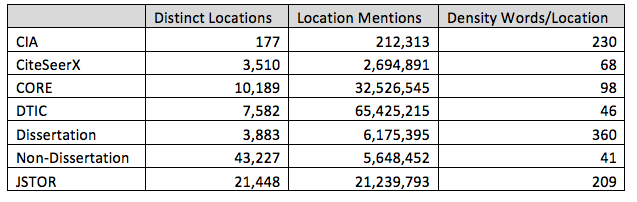
Table 4 compares the spatial correlation of the collections, but instead of examining them based on the percentage of articles mentioning each country, this table uses a gridded spatial correlation. Similar to the approach used in Leetaru et al. (2013) to perform a fast spatial correlation of Twitter datasets, the decimal portion of the latitude and longitude of each location are removed, reducing the entire world to a 360 x 180 degree grid. In this case, the grid is further reduced to just the portion of the latitude/longitude grid covering the Africa and Middle East countries used here (2,628 grid cells that actually contained one or more location mentions).
Only Internet Archive Dissertations have any comparisons that are not statistically significant, failing to measurably align with CIA, CORE, and DTIC. All other correlations are significant to the 0.0005 level, indicating extremely high correlation. The fact that JSTOR and GDELT have the highest correlation suggests that these results may be dependent more on the total spatial coverage of the collection (a larger collection discussing a wider range of locations), rather than its distribution. However, repeating the correlation process, but limiting it to only grid cells covered by both collections (to limit the effect of a larger collection covering more distinct locations), changes the results only slightly, with Dissertations and CORE increasing from r=0.04 to r=0.05 and the highest correlation, JSTOR - GDELT, remaining the same at r=0.81. If total size of the collection was the greatest driving factor, Non-Dissertations or CIA material would likely have the lowest correlation, not dissertations.
Table 4: Spatial correlation of each collection based on 1-degree grid
The following maps visualize the city-level geographic focus of the academic literature versus government literature versus the news media, extending the tables above by visually exploring the spatial similarity of the collections. Figure 22 shows the geographic distribution of the combined CIA and DTIC collections, illustrating that U.S. Government coverage of Africa and the Middle East has been largely focused on a handful of countries of greatest interest to U.S. policymaking, with relatively light coverage of the rest of the continent. Figure 23 visualizes the coverage of the combined academic literature, capturing vastly more coverage across the continent. Figure 24 visualizes the coverage of GDELT, representing the geographic focus of the world's news media over the past quarter-century, showing many similarities to that of academic literature. Finally, Figure 25 combines the three, making it easier to see the areas of overlap and non-overlap. To test whether the geographic focus has changed measurably over time, JSTOR articles were grouped by decade and the spatial similarly compared from each decade to the next. The resulting correlation is nearly constant, ranging from r=0.96 to r=0.99, suggesting little change in the spatial focus of the literature over the past six decades.
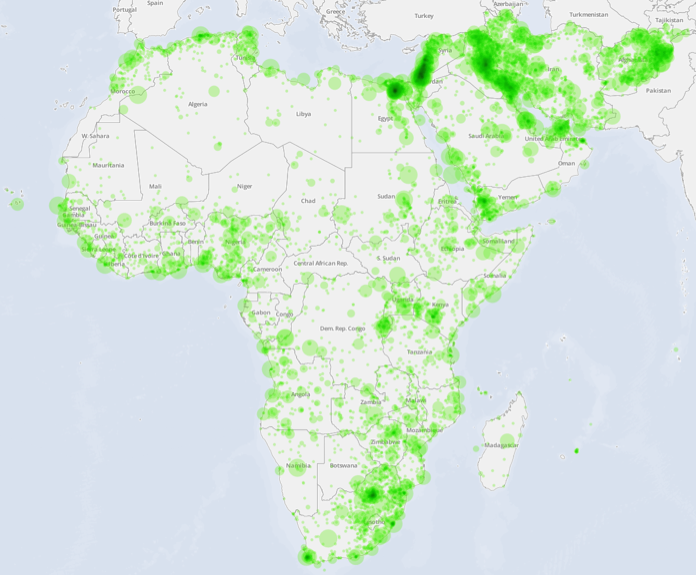
Figure 22: U.S. Government (CIA + DTIC) geographic coverage
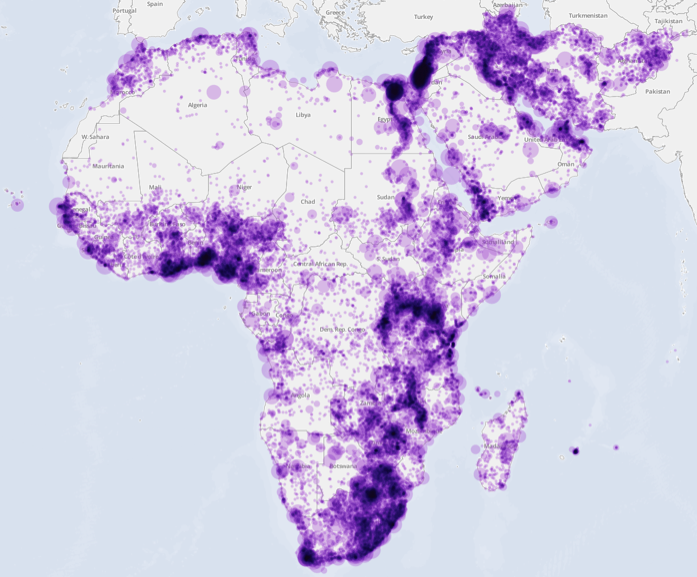
Figure 23: Academic Literature (CiteSeerX, CORE, Dissertation, Non-Dissertation, and JSTOR) geographic coverage
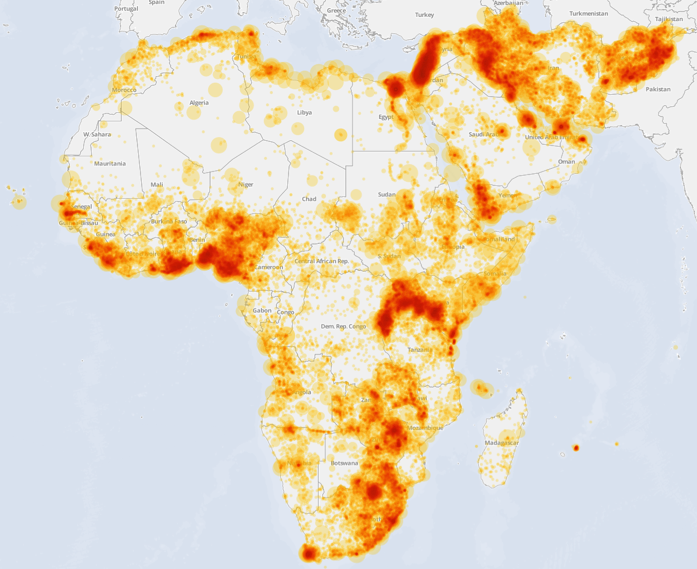
Figure 24: GDELT geographic coverage
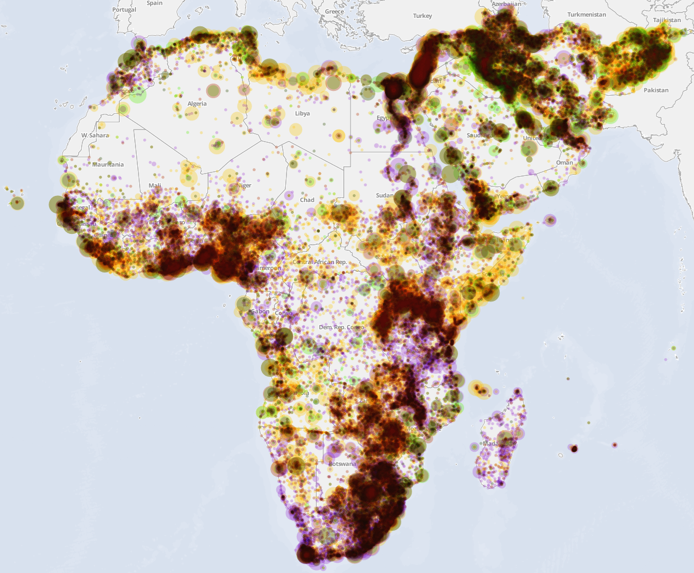
Figure 25: Combined U.S. Government (green), Academic Literature (purple), and GDELT (yellow) coverage
A Literature-Scale Knowledge Explorer
Thus far, this paper has examined the characteristics of the underlying collections, visualizing and teasing apart the differing views that academic literature, U.S. Government publications, dissertations, and the news media yield of Africa and the Middle East. These are critical endeavors to better understand potential nuances of the data and its suitability for various forms of analysis. Yet, the purpose of this study is to build a knowledge graph over the socio-cultural information encoded across this literature to enable literature-scale quantitative analysis of the region. How can the massive database of citations, dates, locations, themes, and cultural group references archived in this database be used to observe trends across the academic literature?
Mapping an Ethnic Group: The Nuer
On May 8, 2014, the United Nations issued a report summarizing human rights violations in the ongoing conflict in South Sudan (United Nations, 2014), which prompted numerous news outlets such as the New York Times (Kushkush & Sengupta, 2014) to cover the latest violence in the country. The Nuer ethnic group features prominently in the South Sudanese conflict and is relatively localized to South Sudan and the immediate surrounds, offering an ideal case study of how this academic knowledge graph could be used to understand an ethnic group. Could one use this knowledge graph to take an ethnic group mentioned in the news and instantly access a condensed summary of what is known of that group from across the academic literature? A simple example of this would be to map the geographic footprint of an ethnic group and its topical association.
Every mention of the Nuer across the seven collections was examined to find the closest geographic reference to each mention in the text, resulting in the map below. The reference list from each article was dropped prior to searching to ensure that publication locations of books would not be misinterpreted as locative associations. The resulting map below is a composite of direct and indirect associations. Clearly visible is the group's centering in South Sudan and Sudan, but also a measurable connection between the Nuer and Cairo. The reason for the connection with Cairo is that one of the foremost ethnographers of the Nuer, Sir Edward Evan Evans-Pritchard, was a Professor of Sociology at Fuad I University in Cairo from 1932-1934. This results in frequent discussion of Evans-Pritchard's research on the Nuer being mentioned in context with his time there such as in Beidelman (1974). Yet, overall, the map correctly associates the Nuer most strongly with South Sudan and Sudan.
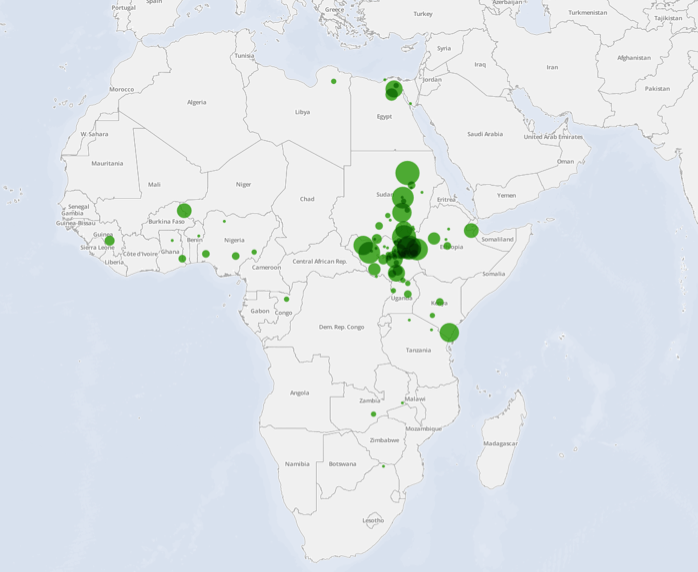
Figure 26: Geographic affiliation of the Nuer
Examining the thematic undertones of coverage of the Nuer, the list of all themes mentioned in each article discussing the Nuer was compiled into a histogram. Unlike the geographic mentions, no proximity filter was used to limit the search to themes appearing near mentions of the Nuer, as the goal was to identify the broader topical contextualization of the Nuer, which would be found only through an analysis of each entire article. The final list of top themes include Religion, Ideology, Manmade Disaster (a theme capturing disaster due to human action or inaction), Agriculture, Food Staples, and Armed Conflict, all of which are closely associated with the ongoing conflict in Sudan.
A final analysis involves the ability of the extracted citations from each paper to be used as a "find an expert" mechanism to locate the most heavily cited authors writing on a topic of interest. In this case, the list of citations extracted from each article mentioning the Nuer was used to compile a histogram of the top cited authors. The top five authors most heavily cited in articles discussing the Nuer are Evan Evans-Pritchard, Meyer Fortes, Alfred Reginald Radcliffe-Brown, Edmund Ronald Leach, and Max Gluckman. Each of these authors is closely associated with seminal scholarship on the Nuer, yet all five are now deceased, making this less useful in terms of locating a contemporary expert. Repeating this analysis, but limiting to cited works published in 1990 or later, two names surface, Sharon Elaine Hutchinson at the University of Wisconsin and husband-and-wife team Jean and John Comaroff at Harvard University, all three of whom have written extensively on the Nuer.
Mapping a Theme: Food and Water Security
Repeating the Nuer analysis, but this time focusing on a thematic topic rather than an ethnic group, the following map shows the result of mapping all locations associated with food and water security in Africa and the Middle East. The resulting map offers a composite synthesis of areas undergoing desertification, armed conflict, high population density, and increasing food prices. Even highly developed nations like South Africa are represented. In its 2013 report on food security (SANHANES, 2013), the South African Human Sciences Research Council identified the Eastern Cape as having the highest levels of food insecurity in South Africa, followed by north-eastern South Africa, while Cape Town is increasingly experiencing high levels of urban food insecurity, all of which are seen in the map below. Yet, almost as interesting as what the map shows is what it does not show. In particular, the conflict in South Sudan has had a devastating impact on food security, yet the academic literature has focused little on food security issues in the area.
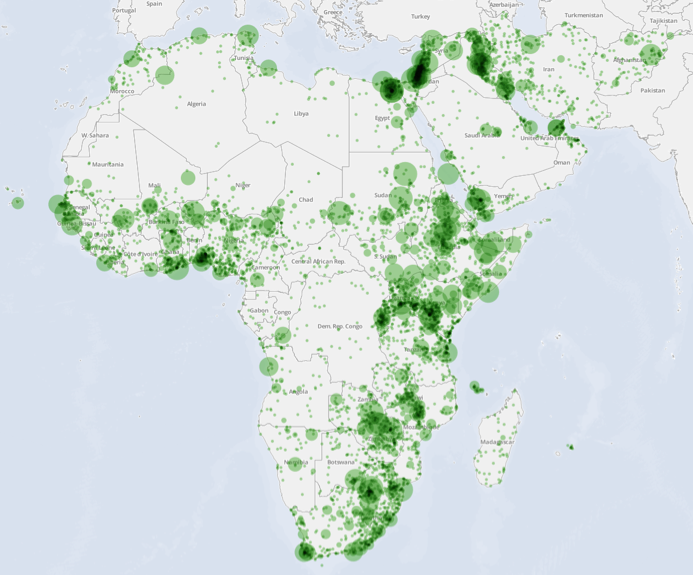
Figure 27: Geographic affiliation of food and water security discussion
The themes most closely associated with food and water security are Manmade Disaster, Government (reflecting the government's role in disaster relief), Medical and Disease, Natural Disaster, Agriculture, and Armed Conflict. The World Bank and United Nations are the most-cited authoring bodies on the topics of food and water security, followed by Harold Mooney of Stanford University and Robert Sokal of Stony Brook University (the latter for his work on biostatistics). In the post-1990 period, the World Bank and United Nations are still the most-cited authoring bodies on the topic, followed by David Tilman of the University of Minnesota and Peter Vitousek of Stanford University.
Exploring a Geography: Rwanda
In addition to ethnic groups and thematic topics, a likely use case scenario for such a database would be to summarize all known information about a given location for situational awareness. To explore this further, all articles mentioning Rwanda were selected: 23,205 in total. The top themes of this coverage are Ethnicity, Government, Armed Conflict, Disease/Health, Manmade Disaster, Military, Religion, Women, Food Staples, Human Rights, HIV, and Children. Examining only mentions of ethnic groups, the top two ethnicities associated with Rwanda are American and French, reflecting their substantial roles in Rwanda, especially the investigations of France's support for the government forces who were subsequently involved in genocidal activities. Asian is the next most popular ethnicity (stemming from contextualization of Rwanda and the Cambodian genocide), followed by Arab (reflecting the Darfur genocide), Indigenous/Indian (reflecting the countless removals of indigenous populations from their lands over time), German (the Holocaust), Christian (reflecting that Rwanda has one of the highest densities of Christians in Africa), and Chinese (the Nanking Massacre and discussion of suppression of Tibet). Even the Maori are invoked as an example of "nonstate genocide" (Campbell, 2009). The two ethnic groups actually involved in the conflict, the Hutus and Tutsis, rank surprisingly low on the list of associated ethnicities — 23rd for the Hutus and 39th for the Tutsis.
Exploring this further, it turns out that the term "Rwanda" has become synonymous with genocide and is used predominantly not as a reference to the country in Africa but as an invocation of mass genocide in the modern era. Just 17% of articles mentioning the country Rwanda actually mention a city or other location within the country, while only 7% mention the Hutus or Tutsis, and a mere 3% of all articles containing the word "Rwanda" mention both a location within the country and the Hutus or Tutsis. Thus 97% of the results from a keyword search for "Rwanda" invoke the country merely as a symbol of genocide as opposed to an actual in-depth discussion of the genocide itself. Given that 93% of those search results do not even mention either of the ethnic groups involved in the conflict, it is clear that Rwanda has become purely symbolic in the literature.
This is both a fascinating finding and deeply troubling from the standpoint of using an academic literature database as a tool to study the geography of culture. When the geography of conflict becomes redefined as symbolism rather than actual locative discussion, this makes it difficult to use such a database to compile a summary understanding about a specific location. Even a human-based keyword search will be unable to rapidly unpack the available knowledge about a given location without review of a large volume of material. In particular, it means that a simple histogram of the topics discussed most commonly with respect to a location will not yield a trivial summary of that location, even in an area with an event such as genocide dominating reporting and analysis.
However, it is likely that articles which mention specific locations in a country are more likely to discuss the actual events of that country rather than merely invoke it symbolically. Repeating the analysis of above, but this time filtering for only articles mentioning a city or other subnational location in Rwanda (rather than just containing the keyword "Rwanda"), the top themes are Education, Manmade Disaster, Government, Ethnicity, Disease/Health, Leadership, Armed Conflict, Democracy, Death, Agriculture, Ideology, Children, and Poverty. The list of ethnic groups associated with the location changes dramatically, with the top four ethnic groups in order now American, French, Hutu, Tutsi. This far more closely reflects the reality of the conflict and suggests that the contextualization of a geography can be overcome by limiting to subnational locative references. It also means that for thematic exploration of a geographic place, an effective process or tool must accurately distinguish articles invoking a place for symbolic or narrative purposes as opposed to those discussing events that took place there.
Examining citations, the top two cited authors are the World Bank and United Nations, followed by the World Health Organization, Paul Collier of Oxford University, and Ted Robert Gurr of the University of Maryland. Looking only at post-1990 cited works, the list changes to World Bank, United Nations, Paul Collier, World Health Organization, and Nils Petter Gleditsch of the Peace Research Institute Oslo. Gurr in this case still appears, but is lower on the list, reflecting the fact that many of his most highly-cited works, such as his book Why Men Rebel (1970), were published prior to 1990.
Looking Across the Literature: A Network Diagram of Ethnic Groups
One of the most powerful capabilities of a dataset of this magnitude is the ability to look across a cross-section of literature to extract disciplinary-scale patterns. The visualization below shows this approach used to visualize how the world's ethnic groups are contextualized through the eyes of the academic literature. Here the entire JSTOR corpus was examined for every mention of an ethnic group, excluding those ethnic groups that are also nationalities to avoid skewing towards mentions of the country rather than the group. All ethnic groups mentioned in a given article (regardless of proximity) were connected to construct a co-mention network over the world's ethnicities. Due to their catch-all use to refer to those from across the Middle East, "Arab" and "Muslim" were excluded. The analysis was limited to the JSTOR corpus because of its linear growth and relatively even coverage of the entire 1950-2007 period. African ethnic groups are often contextualized inside discussion of other ethnic groups from around the world, so all ethnic groups are included.
The final network captures how the world's ethnic groups are discussed across the past 60 years of the social sciences and humanities literature, offering a glimpse of how academia has viewed their interconnections and relatedness. Each ethnic group is drawn as a node, sized by the relative number of mentions it received, while the lines between the groups indicate groups which appear together in the literature. A technique known as "modularity finding" (Blondel, et al., 2008) was applied to colorize the network, drawing in the same color ethnic groups that appear more often with each other than with others, resulting in eight primary groupings. The ability to look across the entire contents of thousands of journals over more than half a century and extract macro-level patterns in how scholars have viewed the world's ethnic groups reflects perhaps the greatest potential of this new way of exploring the academic literature.

Figure 28: Co-mentions of world ethnic groups in JSTOR articles
Conclusions
Academic literature has remained largely absent from the new field of large-scale computational study of culture, yet forms the primary repository of scholarly knowledge on the macro functioning of human society. This study has demonstrated the feasibility both of assembling a cross-sectional archive of academic literature on a specific region and of the computational exploration and visualization of 21 billion words of that material through automated temporal, geographic, thematic, and citation extraction algorithms. The Internet Archive's record of the open web is found to be a rich new data source on culture, but is heavily skewed towards modern born-digital material and will require full text search capabilities for more thorough analysis, while JSTOR's ability to study the entire publication history of thousands of journals spanning more than a century demonstrates the critical importance of historical digitization.
The literature on Africa and the Middle East biases towards more recent knowledge, both in the papers it cites and the events it discusses, but contextualizes that knowledge within a time period spanning centuries. This long-tailed distribution in the "age" of knowledge remains unchanged in the internet era, suggesting that the increased availability and access of born-digital material has not led to a refocusing of the literature on the present at the expense of the past. Yet, the literature synthesizes this knowledge primarily at the annual level, making it difficult to codify discrete "events" from the literature and demonstrating that academia focuses on macro-level historical synthesis rather than realtime chronologies of behaviors and trends.
The geography of academic literature is found to closely match that of the news media, with extensive penetration into rural areas and conflict zones, and does not show strong correlation with UN population statistics or prevalence of English speakers, suggesting it is not significantly driven by Western accessibility. U.S. Government research, however, is found to skew heavily towards areas of U.S. policy interest. This is a potentially unfortunate finding, in that it suggests both that current U.S. attention, and the attention of its future leaders (given that DTIC includes war college theses) is skewed heavily towards present, rather than future concerns. Geography is also found to be stable over the past six decades in the academic literature, indicating that academic scholarship about the region does not pivot based on changing policy interest or current events.
The ability to rapidly construct geographic maps, thematic lists, find-an-expert-lists of prominently cited authors, and even network diagrams over the entire publication output of thousands of journals offers a tantalizing view of the value that the academic literature and the open web could provide to the computational study of culture. In particular, it offers an intriguing new lens to break down disciplinary barriers and look across our collective scholarly understanding of what makes us human and how global society functions.
Acknowledgements
This project builds on prototype work funded by the U.S. Army under contract W9132T-13-P-0053 to make the findings of social sciences literature more readily accessible to analysis, based on the DTIC archive with permission of DTIC. The authors would like to acknowledge JSTOR and especially Kristen Garlock and Ronald Snyder, the Internet Archive and especially Jake Johnson, DTIC and especially Thomas Glad for his assistance in understanding how to work with the DTIC material, CORE and especially Petr Knoth, and CiteSeerX and especially Jian Wu and Lee Giles. The authors would like to thank Google and Google Ideas for access to Google Compute Engine and Google Storage Cloud for the computational resources used for portions of this project and the Internet Archive for the computational resources used for portions of the project.
References
[1] Thomas Beidelman, 1974. "Sir Edward Evan Evans-Pritchard — An Appreciation," Anthropos, volume 69, number 3/4, pp. 553-567.
[2] Vincent Blondel, Jean-Loup Guillaume, Renaud Lambiotte, and Etienne Lefebvre, 2008. "Fast unfolding of communities in large networks," Journal of Statistical Mechanics: Theory and Experiment, volume 10, issue P10008.
[3] Ethan Bronner, 1999. "Ideas & Trends You Can Look It Up Hopefully," New York Times (10 January).
[4] Bradley Campbell, 2009. "Genocide as Social Control," Sociological Theory, volume 27, issue 2, pp. 150-172.
[5] Isaac Councill, Lee Giles and Min-Yen Kan, 2008. "ParsCit: an Open-source CRF Reference String Parsing Package." Proceedings of the International Conference on Language Resources and Evaluation 2008.
[6] Doerte Doemeland and James Trevino, 2014. "Which World Bank reports are widely read? Policy Research working paper no. WPS 6851."
[7] Ted Erikson, 1959. "Thermodynamics of the Steady State."
[8] Ted Robert Gurr, 1970. Why Men Rebel. Princeton: Princeton University Press.
[9] Michael L. Hargrave, David A. Krooks, Carey L. Baxter, George W. Calfas, Dawn A. Morrison, Natalie R. Myers, Eric M. Nielsen, SFC (ret), Timothy K. Perkins, Chris C. Rewerts, Angela M. Rhodes, Judith M. Vendrzyk and Lucy A. Whalley, 2014 (forthcoming). "Socio-Cultural Analysis with the Reconnaissance, Surveillance, and Intelligence Paradigm," Topical Strategic Multi-Layer Assessment (SMA) and U.S. Army Engineer Research Development Center (ERDC) Multi-Agency/Multi-Disciplinary White Papers in Support of National Security Challenges.
[10] Ismail Kuskush and Somini Sengupta, 2014. "UN Report Documents Atrocities By Both Sides in South Sudan War," New York Times (8 May).
[11] Kalev Leetaru, 2011. "Culturomics 2.0," First Monday, volume 16, issue 9.
[12] Kalev Leetaru, 2012. "Fulltext Geocoding Versus Spatial Metadata for Large Text Archives: Towards a Geographically Enriched Wikipedia," D-Lib Magazine, volume 18, issue 9-10. http://doi.org/10.1045/september2012-leetaru
[13] Kalev Leetaru. "The GDELT Global Knowledge Graph Category List."
[14] Kalev Leetaru, 2010. "The scope of FBIS and BBC open source media coverage, 1979—2008," Studies in Intelligence, volume 54, issue 1, pp. 51—71.
[15] Kalev Leetaru and Philip Schrodt, 2013. "GDELT: Global Data on Events, Language, and Tone, 1979-2012," International Studies Association Annual Conference, San Diego, CA.
[16] Kalev Leetaru, Shaowen Wang, Cao Guofeng, Anand Padmanabhan, and Eric Shook, 2013. "Mapping the Global Twitter Heartbeat: The Geography of Twitter," First Monday, volume 5, issue 6.
[17] Barbara Lesser, Christian Cupp, Richard Wayman, Keith Thompson, and Holly Wilson, 1993. "Defense RDT&E Online System Handbook."
[18] Roger Macdonald and Kalev Leetaru, 2014. "Internet Archive's virtual reading room empowers data mining on a societal scale."
[19] MACSA News, 1970. "FRELIMNO Representatives in Madison."
[20] Jean—Baptiste Michel, Yuan Shen, Aviva Aiden, Adrian Veres, Matthew Gray, Joseph Pickett, Dale Hoiberg, Dan Clancy, Peter Norvig, Jon Orwant, Steven Pinker, Martin Nowak, and Erez Aiden, 2011. "Quantitative analysis of culture using millions of digitized books," Science, volume 331.
[21] Alan Pritchard, 1969. "Statistical Bibliography or Bibliometrics," Journal of Documentation, volume 25, issue 4, pp. 348-349.
[22] South African Human Sciences Research Council (SANHANES), 2014. "The South African National Health and Nutrition Examination Survey."
[23] United Nations, 2014. "Conflict in South Sudan: A Human Rights Report."
[24] United Nations, 1947. "Law Reports of Trials of War Criminals."
[25] United Nations, 2013. "Total Population — Both Sexes."
About the Authors
 |
Kalev H. Leetaru is the Yahoo! Fellow in Residence of International Values, Communications Technology & the Global Internet at the Institute for the Study of Diplomacy in the Edmund A. Walsh School of Foreign Service at Georgetown University. His work focuses on "big data" analyses of space, time, and network structure to understand human society and culture through its communicative footprints and is the author of Data Mining Methods for the Content Analyst from Routledge. |
 |
Timothy Perkins is a research project manager with the U.S. Army Engineer Research & Development Center (ERDC). His work seeks to enable better planning and decision-making by exposing insights into complex sociocultural environments through interactive analysis, modeling and simulation, and visualization of dynamic, multifaceted data. |
|
Chris Rewerts is a Senior Research Scientist at the U.S. Army Engineer Research & Development Center (ERDC) in Champaign, Illinois. His work focuses on improving the use of data and knowledge to augment the expertise of military decision makers. |
|
|
|
| P R I N T E R - F R I E N D L Y F O R M A T | Return to Article |