|
|
|
| P R I N T E R - F R I E N D L Y F O R M A T | Return to Article |
D-Lib Magazine
September/October 2010
Volume 16, Number 9/10
Designing and Implementing Second Generation Digital Preservation Services: A Scalable Model for the Stanford Digital Repository
Tom Cramer
Stanford University Libraries
tcramer@stanford.edu
Katherine Kott
Stanford University Libraries
kkott@stanford.edu
doi:10.1045/september2010-cramer
Abstract
This paper describes the Stanford Digital Repository (SDR), a large scale, digital preservation system for scholarly materials. It examines the lessons-learned through over five years of development and operational experience. Building on the knowledge gained, the paper goes on to outline a new repository design and service framework, SDR 2.0, that will address some of the challenges that have emerged. Changes in the environment such as staffing levels and collaborative opportunities are also described. Finally, the paper includes observations on the general state of the preservation and repository communities, and the emergence of a new generation of systems and strategies in this space.
Keywords: digital preservation, digital repositories, digital libraries, Fedora
Introduction
The Stanford Digital Repository (SDR) is a preservation repository designed to make digital assets available over the long-term by helping ensure their integrity, authenticity and reusability. In production since December of 2006, the SDR could be fairly termed a "first generation" repository, in that it represents the first, full-fledged, sustained effort by Stanford to build a preservation system as a core part of its enterprise information services. By design, the Stanford Digital Repository serves as a back-office, content-agnostic, preservation store for library, university and domain-specific digital, scholarly resources. (Figure 1) Library content includes "Everyday Electronic Materials" (EEMs)-born digital content selected for inclusion in library collections-as well as digitized content from internal digitization workflows and the Google books project. Institutional repository content comprises electronic theses and dissertations, open access articles, research data, and university archival materials. Discipline- or domain-specific contents include materials such as maps and geospatial data sets in the National Geospatial Digital Archive, digitized medieval manuscripts from the Parker on the Web research site, or archival copies of video games, virtual worlds and contextual materials associated with the Preserving Virtual Worlds project.
In each of these cases, SDR's design enables it to provide digital preservation services for these varied content streams (i.e., fixity through content replication and auditing, secure deposit and retrieval of files to authorized parties, ongoing content administration by dedicated digital preservation staff), while "front-office", user-facing systems provide tailored interfaces to support the deposit, description, discovery and retrieval of content through specialized, content- and context-appropriate applications. By providing back-office preservation infrastructure, SDR is a critical component in Stanford's digital library and institutional repository services, although it is not the institutional repository in and of itself.
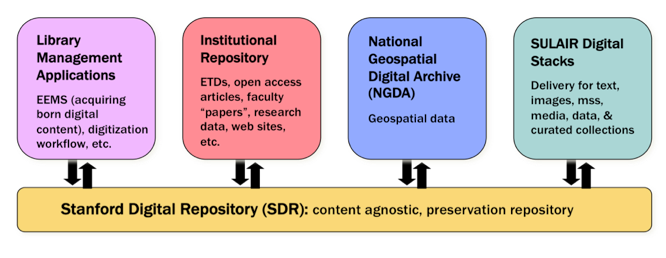
Figure 1: The SDR as back-office preservation infrastructure
To date, the SDR has been relatively successful in achieving its original mission. It is the preservation home for more than 80 terabytes (TB) of unique content comprising tens of thousands of objects and millions of individual files. With copies of all data stored in distributed locations, the SDR holds more than 300 TB of managed content. It stores five disparate content types (geospatial data, books, images, audio and manuscripts); has proven ingest, administration and retrieval capabilities; and its contents have undergone multiple, successful media migrations and integrity audits. If it were to continue on its original trajectory, the SDR would be poised to incrementally add additional content types and collections; to enhance its administrative suite of tools; to introduce a more robust program of auditing; and to build (or integrate with) a basic set of access / retrieval applications to facilitate content access. But with five years of increased maturity in the preservation community since SDR 1.0 was originally conceived, three years of live operational experience, and substantial shifts in the underlying Stanford environment (both technical and organizational), Stanford University Libraries and Academic Information Resources (SULAIR) now has both the information and the need to revisit and revise SDR's original architecture and service model, and produce a second generation system. While these changes are in many ways a natural extension of the SDR's current nature, collectively the sum of these changes is substantial enough that we consider the new system to be "SDR 2.0".
Environmental Changes
Recent years have seen substantial shifts in the environment in which SDR operates. The three most significant shifts in the external environment since 2006 have been substantial staffing changes; development of a robust set of digital library access and management systems outside of SDR; and increasing maturity of the preservation community, and supporting programs and systems. In 2005, when SULAIR originally assembled a team to build and run SDR, the group comprised ten staff, and consisted of a software architect, several engineers, metadata specialists, preservation analysts, and a pair of operations staff. Most personnel were reassigned from other units, and brought their existing job responsibilities with them, and in reality the team was far from being solely dedicated to SDR development. That said, the swarming of the task with a sizeable team had the calculated effect, and SDR's first components were designed, built and operational within six quarters. Now, nearly four years later, the dedicated SDR team is half its original size. Further, only two of these FTE were on the original development team for SDR 1.0. Two factors contributed to this reduction; the first was the dramatic university-wide budget reductions resulting from the economic shock of 2008. The second factor was the constitution of two teams whose development work complemented the work of the SDR Team, and the transfer of SDR staff to these new functional areas.
The formation of these new teams actually served to bolster SDR's operations by moving responsibility for overall digital library architecture and data modeling out of the SDR Team, and offloading ancillary or supporting functions such as web site development and metadata work to other units. This allowed the SDR Team to focus nearly exclusively on development and operation of the preservation repository, while other teams addressed SULAIR's long-standing needs for access and user-facing management systems. The cross-pollination from staff transfer also helped ensure understanding of and alignment with the SDR's services and operational needs, promoting better interoperation across the various units supporting the Stanford University Libraries' digital efforts.
The net effect of SDR staff turnover, the overall reduced level of staffing, and the growth of complementary functions has been the realization that sustaining SDR over the medium and long-term will necessitate streamlining its design, code-base and operation to enable administration by new (and smaller numbers of) staff. This has led to an overwhelming prerogative to reconceive SDR 2.0 as a simpler, more narrowly scoped, capably fulfilling a small but essential set of preservation functions.
Development of SULAIR's Digital Library Ecosystem
SDR by design is a back office system, designed to complement user-facing access and management systems for digital assets. During SDR's original build-out, these other systems were largely conceptual or existed but integration was a distant concern. This forced SDR to compensate for their absence by taking on several general purpose management services (specifically content analysis and preparation) and access functions (optimizing packaged content for delivery). In the intervening years, these front-office systems have taken shape and begun to deploy. On the management side, SULAIR has developed a Digital Object Registry (DOR) that serves to register, track and relate digital content regardless of its location in the digital library. Based on Fedora, DOR orchestrates the services and workflows necessary to accession and manage digital content, and also prepares assets both for preservation (in SDR) and access (via Stanford's growing suite of digital library applications). The advent of DOR has provided a scalable, flexible system for content receipt, conversion, and packaging upstream of SDR. DOR has also provided a successful technology pattern combining Fedora (as a metadata management system), application front-ends for user interfaces, RESTful web services, and workflow to process objects. (Figure 2.)
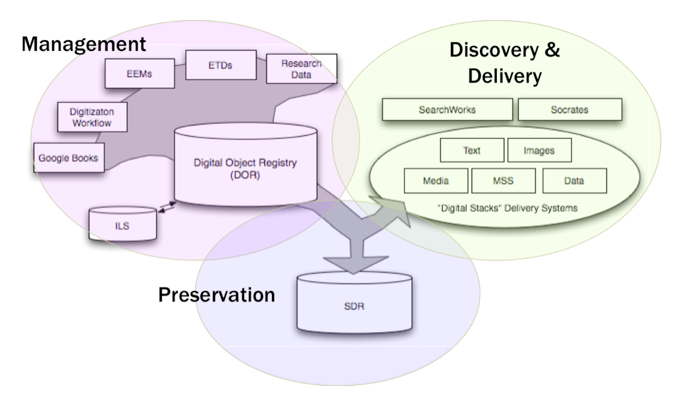
Figure 2: Stanford's digital library ecosystem has three main spheres: Management, Preservation and Access
Stanford's digital library environment has also matured to include systems for access (here defined as both asset discovery and delivery) in a suite of tools that collectively we term "the digital stacks." The digital stacks comprise a suite of Ruby on Rails-based applications, with Solr index metadata stores and NFS-based digital asset data stores, URL and location resolvers, all integrated with Stanford's enterprise authentication and authorization services. Adopting Ruby on Rails-based applications allows for rapid development of flexible front-end interfaces, tailored to specific content types (books, images, media, geospatial data, etc.) or disciplines (e.g., Medieval Studies). A fundamental development strategy has been to develop and aggressively reuse shared components across applications and institutions; collaborating with other institutions to leverage common efforts (Fedora, Hydra, Blacklight, Solr, djatoka, BagIt, PairTrees, etc.) is critical to this plan. The definition of this digital stacks platform and first set of applications in this suite has allowed SDR to narrow its scope to core preservation services, and function as a single, well-defined entity within Stanford's digital library ecosystem. Within this ecosystem, the SDR retains the "master copies" of digital objects from which indices (for discovery) and service copies (for delivery) may be derived as needed. SDR will also provide preservation services for collections that are not being made accessible through the digital stacks.
Maturity and Understanding of the Preservation Function, Community, and Systems
The initial development of SDR included a technology strategy to adopt or buy components where possible, and to build where needed. Based on an initial marketplace survey (including assessments of both Fedora and DSpace in 2005), Stanford opted to build modules for ingest, storage management, administration and access, and to purchase storage management subsystems (Tivoli Storage Manager from IBM for library and tape management; Sun's Honeycomb system for online storage). This decision was also influenced by the strengths of the team, a sense that the marketplace had not yet focused on this space, and a desire to keep the system as streamlined and modular as possible, unencumbered by ancillary functions (and limitations) that might be imposed by shoehorning a product into a function other than its original purpose.
Further, the exact nature of and drivers for digital preservation activities was at the time quite open ended. What materials were likely to be ingested? For which designated communities? What type of preservation planning would be required? How much emphasis would be needed on format migration? How often would we conduct fixity checks and perform media migrations? What other types of preservation actions would be needed? What type of management and administrative functions would be most critical to maintaining the repository? The general understanding that informed much of SDR's original design was that necessity and best practice would both emerge over time, and that the system requirements and functionality would correspondingly evolve. Further, it was well understood that the SDR mission and capabilities would need to develop in an environment of constrained resources. Opting to build most of the higher level logic locally offered the best promise of the flexibility required to adapt as needs became better understood.
Since this time, the increased maturity of the digital preservation community, and a deeper local understanding of its strengths and weaknesses have also influenced SDR's path. In 2005, when there was no clear (at least to Stanford) front-runner technology in the digital preservation arena, the predictable complexity and challenges of building local modules seemed acceptable. In 2008, the capabilities of the Fedora repository as an object management framework, in combination with an increasingly obvious rate of community adoption, made it a compelling choice as a module in SDR's architecture for metadata management. In conversation with other organizations that have been developing and operating digital repository services, we believe the issues that have surfaced in the development and operation of SDR are common and that many organizations are seeking ways to migrate to a more scalable and sustainable repository solution. We offer the SDR experience as a way of engaging the community in a discussion of options and emerging best practices for the next generation of digital repository services and the systems that support them.
First Hand Operational Experience
Three years of production and operational experience have also been instructive in informing the requirements and design of a second generation SDR. While many questions on the exact nature and need of digital preservation functions remain unanswered, a clear set of first order objectives for supporting enterprise-scale digital preservation services have emerged (RLG-NARA, 2007). New scholarly resources that vary by data format, content structure, or intellectual context must be able to be acquired, processed, and ingested with little analysis, and no major development. The system must be able to accommodate large collections in terms of both size and number of objects. The administrative function must support both routine and ad hoc reporting and management tasks for standard and exceptional needs. Deposit and retrieval processes must be simple and flexible enough to support hand-offs that work for all parties, with little to no engineering work. These lessons in priority and necessity, garnered through first hand operational experience as well as the wisdom of the digital preservation community, shared at meetings such as the Preservation & Archiving Special Interest Group (PASIG), Open Repositories (OR) and in journals such as The International Journal of Digital Curation and D-Lib Magazine have seasoned the thinking and design behind SDR's second-generation incarnation.
Physical Bottlenecks: Compute Cycles, Bandwidth, and Storage
While the original SDR design prioritized a modular architecture with ingest distinct from conversion, storage and access, experience has shown that further atomizing functions within a macro-process would improve both throughput and manageability. Rather than running ingest as one continuous pipeline for example, SDR's redesign breaks this into discrete functions (i.e., registration, checksumming, validation, packaging, replication, verification, etc.), each capable both of being run in parallel instances, and of being invoked asynchronously. In its current configuration, SDR's second major physical bottleneck lies in its tape storage subsystem. While large objects are written and replicated with acceptable throughput to each of three Tivoli Storage Manager (TSM)-managed tape copies, speed of ingest for small objects in great numbers drops to an unacceptable level due to the transactional overhead of establishing a unique connection for each object. An obvious work-around has been to "containerize" numerous smaller objects into fewer large objects on ingest; a more flexible and systematic approach is required for SDR 2.0, however, and SDR 2.0's design places a premium on introducing a full storage abstraction and management service, engineered to optimize throughput to different subsystems (disk, tape or cloud-based) while isolating SDR's higher-level functions from changes and operations in the storage layer.
Logical Bottlenecks: Data Modeling and Conversion Analysis
SDR's original data model used a Metadata Encoding and Transmission Standard (METS)-based "transfer manifest" (<METS>, 2007) as a submission information package (SIP), and with slight modifications, also used METS as the basis of its archival and dissemination information packages (AIP and DIP). While the SDR data model emphasized the reuse of the administrative and technical metadata sections across like object types (e.g., a book from one set of content should and did greatly resemble a book from another content pipeline), the transfer manifest design necessitated a great deal of analysis. Sometimes complex packaging scripts needed to be written for new content types, which represented a substantial bottleneck in taking in new formats. The data model also preserved as much descriptive metadata as possible for incoming collections. In anticipation of optimizing the population of as-yet-to-be-built discovery and delivery systems the model attempted to capture and structure descriptive metadata in as standard a way as possible across diverse collections, while losing none of the nuances. Overall, this might be described as a "just in case" approach (Price-Wilkin, 1997), with each new content type and collection requiring a substantial analytical effort to create a detailed and appropriate transfer manifest. Ultimately, experience demonstrated that this tailored curatorial approach to data modeling for each content stream was not sustainable. It became clear that to apply preservation services to the diversity and scale of content demanding it, SDR would need to shift its content modeling strategy to more of a "just in time" approach to preparing collections for ingest. Locally, this change in strategy has been affectionately (but imprecisely) termed "Zip & SIP".
Beyond the lessons learned about the need to streamline the submission process, the SDR experience with METS was instructive in planning for an updated repository. While it is certainly possible to have a fairly straightforward METS schema, and it is arguably an excellent, widely adopted package for transmitting digital objects, Stanford's METS schema was also used as the package for storing objects throughout the repository. Using METS as a universal wrapper created issues that complicated the operation of SDR: multiple layers of wrapping, abstraction and references created bloated and contorted objects, and presented challenges in both interpreting and manipulating them. Perhaps most critically, experience indicated that neither depositors nor clients spoke METS natively, and that with both SIPs and DIPs wrapped in METS, every use case for ingestion and delivery required non-trivial conversions to translate from or to a useful package for the depositor or designated community for that content type. With these lessons in mind, SDR's revised data model deemphasizes the use of METS within the repository itself, but will support it as a dissemination package if and when required.
Repository Redesign Process and Outcome
By winter of 2009, it was clear that SDR was poised for a substantial refactoring. Between April and June of that year, four working groups with members from both the SDR Team and Digital Library Infrastructure team discussed lessons learned from SDR 1.0, researched options for a new repository architecture, and submitted recommendations for redesign to Digital Library Systems and Services management. The working groups focused on preservation services as the defining set of requirements to inform the data model, technical architecture, and storage and throughput requirements. Staff reductions in June 2009 and the realization that the operational version of SDR would not scale to enable ingest of the stream of digitized content coming from Google Books made the need to create a new repository design and begin implementation quickly even more urgent. Digital Library Systems and Services management reviewed the working group reports and made a set of high-level decisions and assumptions to inform design for the new repository.
Two guiding principles informed these decisions; that preservation services are what define system requirements and that digital preservation is a program that includes consulting services and policies as well as the systems that implement them. Models such as the Curation Lifecycle Model from the Digital Curation Centre, the Planning Tool for Trusted Digital Repositories (PLATTER) from Digital Preservation Europe, and the TRAC Checklist (RLG-NARA, 2007) informed preservation program planning. Ultimately, we adopted the TRAC Checklist framework as a model. The framework provides guidelines for work in nine areas; acquisition plan, data specifications, access plan, staffing plan, technical systems plan, preservation and risk management plan, business plan, succession plan, and disaster plan but is not prescriptive about solutions. The focus of this paper is the technical systems plan and the data specifications for SDR2.0.
Technical Ssytems Plan
At a systems design level, guiding principles included leveraging the development being done for the digital object repository (DOR) by adopting Fedora, and applying the same design philosophy and workflow used by DOR. While the repository design would continue to be aligned with the Open Archival Information System (OAIS) reference model at a functional level, implementation decisions would be informed by the requirement for an architecture and data model that would support ingestion of large streams of similar content (e.g., Google Books) and bursts of dissimilar content ingested at irregular intervals in the present, and would scale up to enable consistent streams of diverse content, from individually selected PDFs to large scientific data sets to be ingested on an ongoing basis in the future. As a preservation repository, the design would emphasize collecting the most basic metadata needed for identification and support of preservation functions, not forcing requirements for specific types of descriptive metadata or otherwise constraining depositors on the basis of undefined plans for future access systems. With these principles in mind, the information architect for Digital Library Systems and services created the high level technical architecture represented in Figure 3.
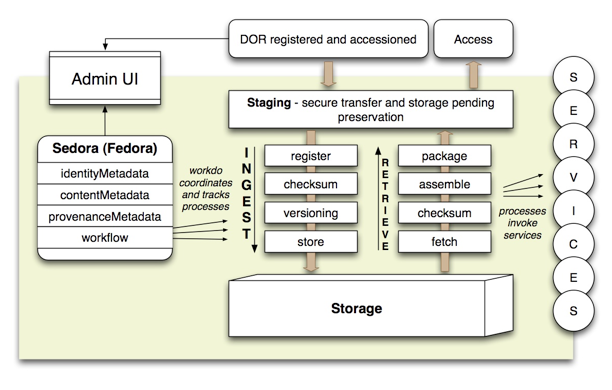
Figure 3: Technical Architecture
The technical architecture also requires design of a storage layer that supports rapid ingestion of both large and small files and multi-threaded processes. Figure 4 shows a high-level design concept of the storage layer. Currently, the SDR Team is testing several vendor storage management systems for possible implementation.
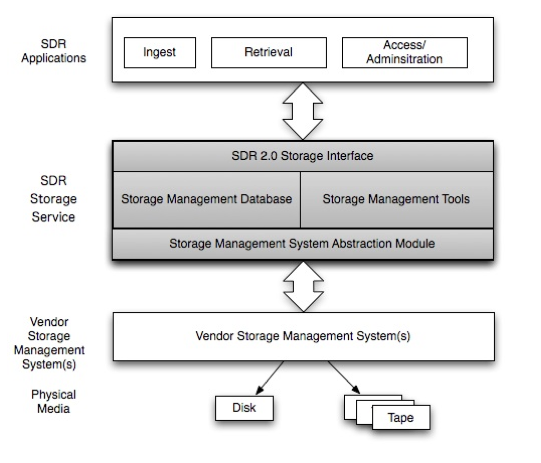
Figure 4: Storage Architecture
Towards a Simpler Data Model
As we compared notes with colleagues from other institutions at the Preservation & Archiving Special Interest Group meeting in San Francisco in October 2009, the directions others were taking in simplifying data models and architectures and making services more modular reinforced our thinking. In particular, the micro-services approach the California Digital Library was pursuing (Abrams, Kunze, & Loy, 2009) seemed similar to the SDR 2.0 principle of making services more modular. The concepts in use at the University of Oxford, to avoid "premature decisions" (Jeffries, 2009) or "just in case" preparation, as well as avoiding being prescriptive about data formats also aligned with our developing ideas about simpler data models. Principles for development of a new SDR data model included sharing the model with the Digital Object Registry (DOR), breaking the object metadata into separate descriptive, technical, content (structural), rights, source, and provenance metadata files for independent control, and preserving only essential technical metadata that would be hard to regenerate later from the object itself. The model also included identity metadata; basic information for identifying the object, including identification numbers, object type, control and access numbers, project tags, and other operational information. Having had success using the Library of Congress BagIt transfer tools to move geospatial data from the National Geospatial Digital Archive project from Stanford to the Library of Congress, we settled on BagIt as the primary transfer format for content being deposited into the SDR (Figure 5).

Figure 5: BagIt Model for DOR to SDR Transfer
The depositor would present content for preservation as files, and they would be bagged up at the DOR level, made ready for deposit into SDR. Once deposited, the bag would continue to accumulate needed metadata such as audit information. This model would allow content to be retrieved by or for the depositor in the same form in which it was deposited, without the need for complicated retrieval routines.
Project Status
Now that the high-level design for SDR 2.0 has been completed, informally reviewed by colleagues at other institutions, and formally reviewed by the Information Security Office at Stanford University, the SDR Team has begun to build prototype services. The development framework parallels the framework used for the Fedora-based Digital Object Repository (DOR). Using test driven development, SDR 2.0 will be developed using a "robot" framework introduced in DOR. These robots, written in Ruby perform the sub-processes that make up SDR 2.0 modules such as ingest and retrieval. To further leverage DOR development and Stanford's participation in the open source community, SDR 2.0 will deploy components from the Hydra Project, "a collaboration between the Universities of Hull, Stanford and Virginia working in partnership with Fedora Commons" set up with the goal to "develop an end-to-end, flexible, extensible, workflow-driven, Fedora application kit" (The Hydra Project, n.d.). As the SDR Team begins this development, we welcome comments on the overall architectural design and principles on which the design is based.
Conclusion
The Stanford Digital Repository has largely achieved its original mission. With three years of continuous operation, it has grown to support more than 80 TB of unique scholarly assets, comprising hundreds of thousands of digital objects in a diversity of formats. With numerous successful media migrations and significant changes in staffing, the Stanford's preservation system has navigated the first of its ongoing sustainability challenges. That said, the last few years of operational experience and shifts in the environment have shown the need for a revised service model, system architecture and overall preservation strategy.
First, SDR's future service profile can be firmly scoped around a few core functions ensuring content fixity, authenticity and security. Content deposit, accessioning, conversion and overall management occur "above" SDR, orchestrated through a digital object registry. Content access, including discovery and delivery to scholars and the general public, occur in purpose-built access systems, in Stanford's "digital stacks". This separation of concerns allows SDR to focus its efforts on large-scale content ingestion, administration, selective preservation actions and limited retrieval. Upstream conversion processes, and rich discovery and delivery systems will be supported through well-defined API's.
Second, SDR's technical architecture will address and improve on the critical priorities that have emerged in operating the first generation repository. These include adopting Fedora as a metadata management system to leverage the community's investment in and ongoing support for an open source platform that aligns well with SDR's overall technical design. Experience has also shown the need to decompose functions into more granular and loosely-coupled services (i.e., from "ingest" to "checksum"), both for increased control of processes as well as for throughput. Finally, the preservation subsystems will require balancing support for accommodating large objects and a multitude of smaller objects. Third, SDR's data model must shift to reduce the incremental analysis and development required to support new content types and collections. Content files will be stored in directories following the BagIt design, with metadata files stored in discrete chunks, leveraging Fedora's object design and XML management capabilities. Taken individually, the changes along any one of these vectors represents an incremental enhancement; taken altogether though, these changes are substantial enough to move the Stanford Digital Repository to a second generation system and set of services.
Acknowledgement
The authors would like to recognize the contributions of the SDR Team, Hannah Frost, Donald Lee, Alpana Pande, and Xinlei Qiu and other members of Digital Library Systems and Services, especially Lynn McRae, without whose design work and thoughtful participation in the working groups, this project and the paper about it would not be possible.
References
Abrams, S., Kunze, J., & Loy, D. (2009). An emergent micro-services approach to digital curation infrastructure. In iPRES 2009: the Sixth International Conference on Preservation of Digital Objects. Retrieved from http://www.escholarship.org/uc/item/5313h6k9.
The Hydra Project. (n.d.) Retrieved from The Hydra Project wiki: http://fedoracommons.org/confluence/display/hydra/The+Hydra+Project.
Jeffries, N. (2009). Oxford update. [PDF document]. Retrieved from http://lib.stanford.edu/files/pasig2009sf/pasig2009sf_oxford_jeffries.pdf.
<METS> metadata encoding and transmission standard: primer and reference manual. (2007, September). (Version 1.6). Washington, DC: Digital Library Federation. Retrieved from http://www.loc.gov/standards/mets/METS%20Documentation%20final%20070930%20msw.pdf.
Price-Wilkin, J. (1997, May). Just-in-time conversion just-in-case collections. D-Lib Magazine. Retrieved from doi:10.1045/may97-pricewilkin.
The RLG-National Archives and Records Administration Digital Repository Certification Task Force. (2007, February). (Version 1.0). Trustworthy repositories audit and certification checklist. Chicago & Dublin, Ohio: CRL, The Center for Research Libraries & OCLC, Online Computer Library Center.
About the Authors
 |
Tom Cramer is the Chief Technology Strategist and Associate Director of Digital Library Systems and Services for the Stanford University Libraries. In this role, he oversees the full complement of Stanford's digital library activities, including the digitization, description, discovery, delivery, preservation and management of digital resources that support teaching, learning and research. Prior to joining the Stanford University Libraries, Tom served as the Director of Middleware and Integration Services and Director of Technology Infrastructure at Stanford University; in these roles, he directed the development, strategy and support for the University's enterprise systems for identity management, authorization, authentication, LDAP directories, email, file systems and e-commerce. Prior to joining Stanford, he worked as both a management consultant and in business development in various IT-related companies. |
 |
Katherine Kott (Manager of Strategic Digital Projects and Organizational Development) manages digital projects and the Stanford Digital Repository (SDR) Team for Stanford University Libraries and Academic Information Resources (SULAIR). Currently, she is leading the SDR Team in a redesign of the Stanford Digital Repository. She is also managing a project to develop a workflow to handle the selection and processing of single digital objects. Katherine works with other SULAIR departments as an internal consultant to improve organizational effectiveness through meeting facilitation, team building, organizational design and process improvement. Prior to re-joining the SULAIR staff in 2008, Katherine managed the Aquifer project for the Digital Library Federation. Aquifer developed and assessed the American Social History Online web site to make primary material in digital form easier for scholars to find and use. With a career spanning more than three decades, Kott has focused on developing user-focused information services in a variety of environments. |
|
|
|
| P R I N T E R - F R I E N D L Y F O R M A T | Return to Article |