
The THETIS system is viewed as a digital library of data repositories and visualization tools. In addition to its index/search capacity, the digital library also provides data querying, data combining, and data visualization capabilities. This paper presents an overview of the design of THETIS, a system that addresses the frequent requirement of scientists, engineers and decision-makers to access, process and subsequently visualize data collected and stored in different formats and held at different locations. The need exists for tools that enable the integration of these data, together with their associated data models, data interpretation techniques, and visualization requirements. The objective is to build an advanced integrated interoperable system for transparent access and visualization of such data repositories, via the Internet and the WWW. Vast amounts of information exist, collected and processed over many years at different research institutions. The data collections are stored in various databases, files, spreadsheets, or are generated by sophisticated data simulation models of physical and biological processes, and by data processing techniques. Data collections comprise numeric, audio, and video data, data models, images, and text. Data models are implemented in program code, which usually needs visualization tools to represent results.
The integration and visualization of data repositories into an easily accessed interoperable networked environment is needed in many disciplines for both scientific and management purposes. One application area where data integration and visualization is particularly needed is Coastal Zone Management (CZM). The proposed system focuses on supporting CZM for the Mediterranean Region of Europe.
The THETIS system is viewed as a digital library of collections of multimedia information, scientific models, and visualization tools needed to locate and use for coastal zone management (CZM). THETIS focuses on supporting CZM for the Mediterranean Region of Europe. CZM is a methodology for the holistic management of all coastal resources with the ultimate aim of promoting sustainable development of the coastal zones. European coastal regions, the Mediterranean region in particular, have, and continue to be, under threat from over-exploitation, resulting in environmental degradation, most notably visible as marine pollution. CZM recognizes that pollution problems transcend political boundaries, and so to be effective, CZM requires the integration of multinational data collections as well as data management and data visualization across many scientific disciplines, such as marine biology, oceanography, chemistry and engineering.
The level of information technology (IT) knowledge within CZM is as diverse as the disciplines. In general, however, most individuals are competent in the use of commercial computer software packages, including Internet navigators. Many scientists also have specialist knowledge of hardware and/or software specific to their precise requirements. Accordingly, data visualization is an important area of information provision, particularly where the results of data analysis are required on a routine basis for management purposes. Tabulated numbers may be suitable for scientific research, however, graphical data and animations are of more use for decision making.
There is a wealth of accumulated information about coastal zones, such as data/images in various databases, files, spreadsheets, video and audio data. Furthermore, there are mathematical models for simulating physical processes of coastal circulation, wave generation, sediment transport, etc. In addition, there are techniques such as image processing and statistical techniques to reformulate, fuse or extract information from measured data. However the data from these sources are often dissimilar, of different resolution or accuracy and/or have been collected using alternative procedures. In addition, access sometimes requires specialized vendor database tools, and integrated access does not exist. In the simplest case, data exchange is accomplished through surface mailed diskettes.
CZM has received tremendous political support from the European Union, and a growing multidisciplinary scientific base exists with strong interest in networked, integrated, and interoperable systems for aiding the solution of various problems. The adoption of standards for data collection across regions for certain parameters has improved data integration to some extent. However, creation ubiquitous standards for all parameters/parameter combinations in all instances is unlikely and also does not satisfy the problem of integrating legacy data. What scientists and decision makers require are tools that enable them to access these disparate data sets, and to use the data in a form that is applicable to them to give them the information they require.
In the prototype system, organizations involved in the THETIS project4 make their data, simulation models and data processing and data interpretation techniques available. In addition, GIS (Geographical Information Systems) and specialized visualization tools are included.
The user requirements for THETIS are introduced by examining a typical scenario of system use. Three main user groups are determined, and the data organization requirements are summarized according to the user requirements.
2.1 A Usage Scenario
A typical scenario of use is as follows:
Suppose we have an extensive database of the physical, chemical, and biological properties of a coastal region under consideration. This database includes the bathymetry of the region and various physical, chemical and biological properties of the water column. Properties include phenomena such as currents, wave and wind spectra, salinity, temperature, and chemical and biological concentrations. A typical query of the database might be phrased as follows: "Find the region of 3D space within the given coastal region and the time interval, within which the concentration of a certain chemical or microorganism may exceed a certain value." Scientists may be interested in questions of this form in order to be better able to understand the physical and chemical processes in a coastal region. Local civil authorities may be interested in issuing permits for fishing or in declaring certain coastal zones health risks, inappropriate for tourism, swimming etc.
More generally, the interrogation of the database is in the form of a query of the type "find a subset of a given set containing points with a specified property". Relevant data may involve remote measurements such as satellite images and in situ measurements taken via buoys or underwater probes. However, due to the hostile ocean environment, it is very difficult to collect dense enough data to respond to the type of questions identified above with confidence. Therefore, an integral part of the data collection process involves synthetic data, which are produced by simulation models of certain ocean processes and physical, chemical, and biological phenomena.
Many of these phenomena are coupled and require, at a minimum, initialization of the functions involved within a certain spatial domain, so that evolution equations can be integrated in time to produce predictions about the system state variables at later times. Processes involved here include, for example, diffusion of chemicals, convection of microorganisms, etc. Consequently, the database under consideration can also be thought as a repository of simulation results in a canonical form that can be queried via the access methods developed in this project.
Scientists interested in using existing programs (or algorithms, numerical techniques, etc.) to study the properties of the fresh data points collected by the sensors in the databases, and also in looking at previous research papers, and possibly some annotations, could submit very complex queries. From the user's point of view, the information system must provide a transparent view to the existing programs or numerical techniques, databases, and documents in an integrated fashion. This could mean searching for existing programs (which are indexed by keywords) and applying them to new data, which could be located elsewhere. Similarly, scientists who come up with new ideas or new techniques would like to announce their research, and invite fellow scientists to use them. Clearly, there is an issue of access control to distinguish among objects accessible for public use and objects for private use, as well as levels of access.
2.2 Classification of Users
In the scenario just described, we implicitly describe several possible users, although we emphasize the scientific user. Next, we classify the users into three possible groups and provide short scenarios of their possible requirements:
An End User (e.g., general public, policy maker) needs to locate and extract data that matches his interest, or appropriate data servers to retrieve data of the desired level of quality. For example, a user may need to access the rating of beaches in his town. Then, he asks why his town is not considered a safe beach. As a result, he gets a definition of a safe beach that is understandable to him, i.e., at the appropriate level of detail, and the data that the definition depends on. For instance, safety may be defined as a collection of criteria such as expected height of waves, and presence of sharks. Then, this user may want to find out who, collected the data about the presence of sharks near his beaches and when this collection occurred. He puts a high value on the accessibility, interpretability, and usefulness of data.
A Broker (e.g., environmental scientist, public authority administrator) maintains the servers for end users. For instance, a broker may have to write programs to access measurement databases, administrative inquiries, remote sensing data, and geographical databases to construct a map of France that indicates the quality of beaches. Also, she writes programs to improve the reliability of data using consolidation techniques. Generally, a broker must find the data necessary for each new program that she writes, and each new program may use multiple data sources. Each data source requires a unique program to extract the data for the new program from the data source.
A Data Provider (e.g., biologist, geologist, physicist, oceanographer, etc.) collects data, and wants to distribute them as widely as possible. For instance, a data provider may manually add his data to an existing database through a standard form-based entry program. Data can also be collected using automatic sensors that directly transmit their data to an associated system. In this case, the provider has to verify the quality of data and eliminate erroneous measurements. To do this, he needs to use specific programs for data analysis and interpretation and access other systems for comparing data with other related data.
3.1 Functionality
THETIS connects various users via the Internet to a distributed collection of information systems [1]. The main building blocks of the system architecture are as follows:
3.2 The flow of information
The components of the system architecture are shown in Figure 1. Clients submit simple or complex queries via the WWW interface (WWW browser) to the system. The queries are submitted to the Web servers, which interface to system services via the Common Gateway Interface (CGI) protocol and Java applets. In the figure, we show that system users, which can be classified as End Users, Brokers and Data Providers, all use the Web as a common and transparent interface to the available data collections.
User requests invoke various services such as metadata, index and search to locate the objects, which match the user's query. We assume that documents are stored in DIENST [4] based servers, and metadata services are provided to access them. For example, the documents could be research papers written by scientists studying the coastal properties of the Mediterranean Sea. Images could be indexed via relational or object oriented databases in various formats.
The user interface is based on a Web browser, and includes a GIS interface. When a user selects a region of a map through the WWW browser, the coordinates of the region are used to index the appropriate information about the region. This implies a metadata service that maps the region of the map to the information about the region. Therefore users can zoom into a region of a map (or image) and query for various properties about the region or perform some operations on-line.
It is possible that the information about a region could be dispersed across several database sites. For example the detailed image of the region can be stored separately from the data objects. This could mean that the information system has to index and search across the various databases to obtain the corresponding information. It is also possible that information could be replicated across the databases. For this service, distributed search queries (via the Web) are sent to the various databases to obtain the objects. Metadata services describing the GIS objects are used to index/search for the appropriate GIS objects (multi-dimensional data and images). Distributed search agents collect/transform the various information objects and present the user with a composite result object.
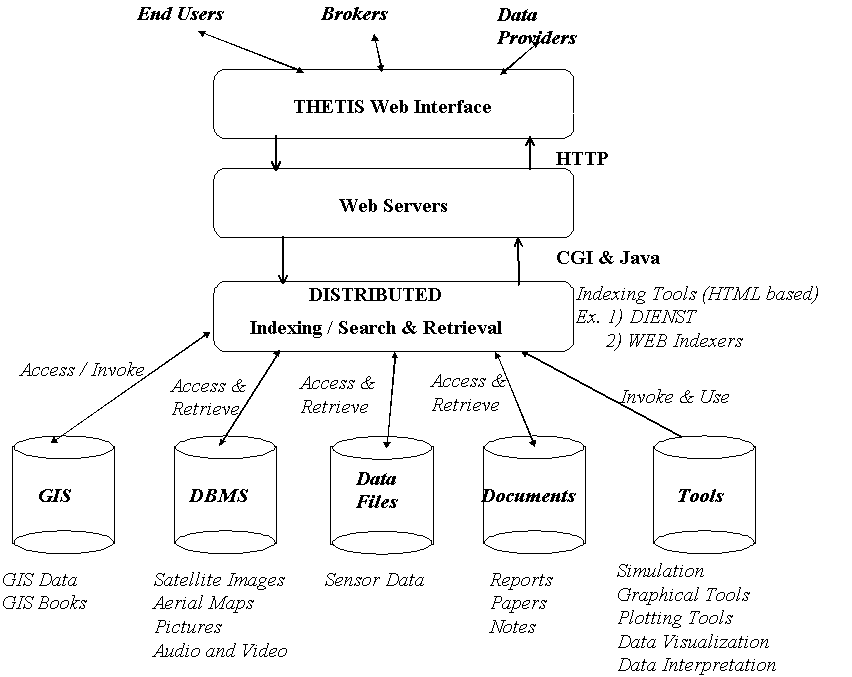
3.3 Data-Related Tasks
From the user description, several data tasks can be defined as follows:
3.4 Data Requirements
In the following table, we summarize the requirements for the various data collections and tools of the THETIS system for different functions. On the horizontal axis, we show the collections and on the vertical axis the system architecture relevant task requirements, such as, storage, index, query, etc. for each of the collections.
| Collection /
Task | GIS | Images | Documents | Video /
audio | Data | Tools |
| Storage | DMBS | FS or DBMS | Bib
(DIENST) | DIENST | Files | File
System |
| Retrieval | Structured | Unstructured | Unstructured | Unstructured | Direct
Access | Direct
Access |
| Index | Data Points
Range | Keyword or
Content | Keyword | Keyword or
Content | Data | Keyword |
| Matching | Exact
one-one | Best
Match | Best
Match | Best
Match | Exact
Match | Exact
Match |
| Query | SQL or
Similar | Query Lang
(DIENST) | Query Lang
(DIENST) | Query Lang
(DIENST) | SQL Like | Query by
name |
| Result
Proximity | 100% | Relevance | Relevance | Relevance | 100% | 100% |
| Results
Ordering |
---------- | Ranking | Ranking | Ranking |
------------ |
---------- |
Table 1. Data Requirements for the Various Collections and Tools (FS = File System, Images = Pictures, Maps, Tools = Simulation Programs, Data visualization tools, Graphical Tools, New Tools)
3.5 A Mediation-based Architecture for Data Management and Visualization
Figure 2 shows a diagram of the THETIS system architecture. The architecture consists of three types of components: data sources, translators (wrappers), and mediators.
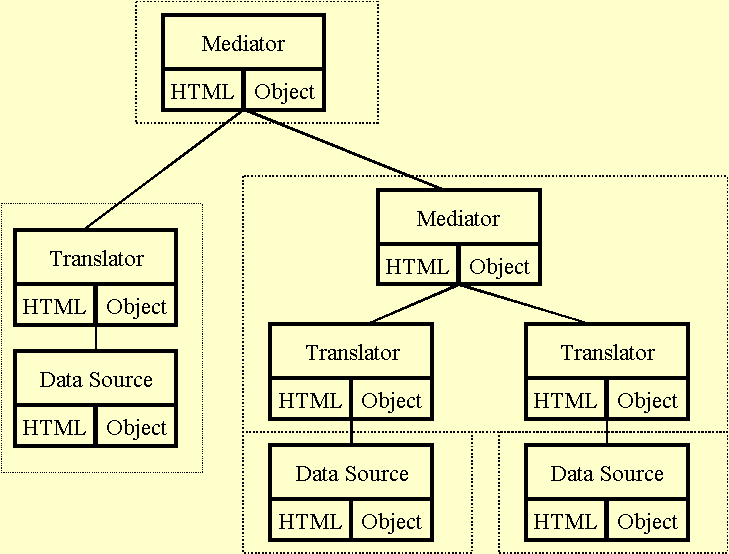 Figure 2. A Mediation-based Architecture
Figure 2. A Mediation-based Architecture Each component consists of a pair: an HTML document describing the component, and the collection of objects that implement the metadata, data and computation. The HTML document provides a means (through indexing engines) for locating the corresponding objects.
A data source, for instance a database system, exports metadata (a scheme), data, computation (query processing) encapsulated as objects. All of these objects are described in the associated HTML document. The document has sufficient information to permit direct browsing of the data by an (intelligent) browser that understands the query language supported by the data source.
A translator provides conversion of queries between two different query languages-the language supported by the data source, and the language in which a mediator expresses queries to the data source. This functionality is again encapsulated as objects and described in an HTML document. For instance, in this document the signatures of the functions supported by the translator are described. Thus, a browser that generates queries in language 1 can browse data in a data source accepting language 2 given the appropriate translator. The mediators encode the tasks of consolidation, aggregation, analysis, and interpretation. The associated HTML document describes the scientific models used for the task and the object describes the metadata and data of the results. Some mediators may support the invocation of the computation used to generate the data. All mediators conform to the same language for queries, metadata, and data. Our goal is to create an environment of "mix and match" mediators, each of which documents a step in the production of coastal zone related data.
The notion of metadata is used in different areas with a similar general goal to enable better data integration, interchange, access, and interpretation. However, there is not a clear definition of what metadata information is, and its interpretation is application domain dependent. Thus, one can introduce the notion of context associated with a particular data source. A formal definition of context requires a formal logic approach, which is not suited for use by an interdisciplinary group of scientists. Thus, in addition to a context, each instance of data, schema, metadata or context can be paired with a piece of text that provides an informal interpretation. We call each such pair a dyad. In particular, the dyads that pair metadata instances with text are very useful for searching. In [28], a set of classes is offered to describe the structure of typical environmental data objects, such as maps, measuring series simulations, etc. Additional user-defined classes can be defined and can inherit the properties of the system-defined classes. Therefore, new classes can be added according to specific application needs, such as coastal zones, to offer a more detailed description of data sources. Metadata can be standard names for physical, chemical and biological properties. Examples include bathymetry, currents, magnetic field intensity, gravity field intensity, salinity, conductivity, temperature, concentration in certain chemicals (ex. pollutants), plankton, etc. These data are spatially and temporally indexed. An ontology for coastal zone management is a project objective.
The applications targeted by the THETIS system involve linking complete systems to perform user-defined tasks, which require the integration of individual capabilities of different systems. This requires that both the requirements of tasks and the capabilities of systems and collections are formally described in a common specification language, so as to enable dynamic binding of tasks to resources. Thus, the problem of identifying "relevant'' data sets and models can be reduced to a matchmaking process. Such a specification language is being developed at ICS-FORTH [36]. An important point is that the same approach can be used for large-scale distributed applications, such as digital library systems, electronic commerce environments, scientific experiment management systems, distributed systems management environments, office automation workflow, and collaboration environments.
3.6 Data Accessibility and Visualization
We present a closer view of part of the architecture that deals with the data accessibility and visualization. We outline a browsing environment that permits browsing large numbers of data sources through browsing of corresponding structured data as tables, graphs, or images. In addition we describe the data / models integration.
The browser displays the data in an appropriate format, such as, tables, graphs, images or maps. Wrappers (translators) in Java, read data from data sources and produce data in a standard language. The standard language adopts the OMG (Object Management Group) [5] data model and the OMG metadata model. Instances of the resulting language are parts of an HTML document.
Initially, data source providers collaborate on data integration by following common administrative procedures for incorporating their data, data models, and data analysis/ interpretation models. Web wrappers are used to export the various data.
Data integration will be accomplished through the construction of "dyads". In Figure 3, we show the elements of integration. In Figure 4, we show connectivity of these elements. A dyad is a pair formed by some text and some formal types. The text describes some data or programs and the formal types the signatures needed for access. Essentially every accessible piece of data or program has an associated dyad. Each dyad is an HTML document. Access to a dyad means access to the underlined data that the formal types provide signatures for. A DIENST server is used for indexing service for dyads. In addition, users can search for metadata, located in the DIENST server, to help identify potentially relevant data sources. Existing web searching tools incorporating information retrieval techniques are used for that purpose.
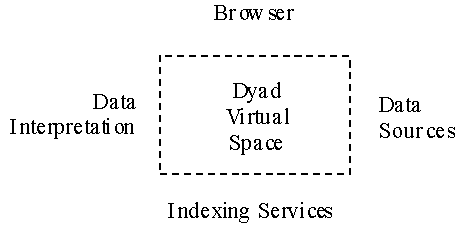
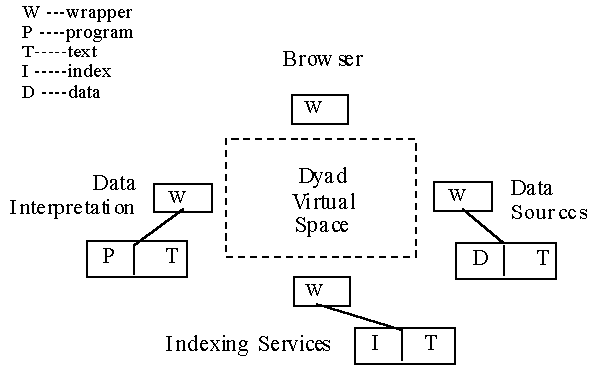
3.7 User Interface
The user interface is based on a standard WWW browser that is extended to support the interface functionality of a GIS. The user interface provides access to HTML documents, which index, invoke, and connect the user to the various collections interactively. A typical interaction, such as retrieving and comparing time-series data on beach levels, can proceed as follows:
In the initial step the user accesses a WWW browser, such as Netscape Navigator, Microsoft Explorer or Sun HotJava, that is extended to provide access to the functionality of THETIS. The browser's view window is divided into several sections (frames). A section is reserved for icons that activate browser commands, and another for displaying documents. A special section is reserved for manipulating metadata. Finally, there is a section for displaying a log of all the actions taken during this session.
In the second step, the scientist navigates to a WWW page describing beach levels and describing additional THETIS metadata that describes the data set(s) indexed by the WWW page. An icon in the page display section of the browser represents this. The user then drags this icon into the metadata section to indicate to THETIS that he is interested in the data described by the WWW page. The browser displays the corresponding metadata for the beach levels.
In the third step, the user may visit a second page that indexes a related data set and again drag the corresponding icon so that the browser displays the corresponding metadata.
Finally, the browser can display a visualization of the beach levels associated with each of the metadata for comparison. This visualization permits the scientist to observe discrepancies between the two series.
The objective is to experiment with the THETIS demonstration prototype system, and to evaluate the functionality and services provided by the system. We outline some of the data repositories the system will make available. We also provide example services of THETIS.
Some of the data are concerned with the biophysical characteristics of the benthic coastal environment and the state of the coastal marine environment of Crete. They are stored in an Oracle database and EXCEL spreadsheets. In addition, satellite data involve satellite pictures of various coastal zones around the Mediterranean Sea, and they are stored in a number of different databases. Moreover, data concerning coastal mapping, winds and waves are also available. They are stored in files within a directory in ASCII text or formatted by a particular application, for instance, LOTUS/EXCEL. They are also stored in local databases. These data are used as input to the various models suggested for use in pollution prediction.
Existing numerical simulation models implemented as Fortran or C programs are integrated into the system for supporting coastal management decisions. Several candidate models are considered: the Princeton Ocean Model (POM), a three-dimensional hydrodynamics model to the coastal shores of Crete, and the European Regional Seas Ecosystem Model (ERSEM) for the Cretan coast ecology.
Data interpretation and image processing algorithms that are implemented as Fortran or C programs are integrated into the system. A number of data interpretation and analysis models are applied to measured data such as models for point spectra, directional spectra, and spectral parameters analysis of ocean wave data. They employ wave buoy data. A similar model to the data model for integration mechanism is used.
A Geographical Information System (GIS) is integrated into the system. Various GIS displaying capabilities (e.g., thematic maps) are used to display the geographical component of the data. The GIS system is invoked by the THETIS system when users request it for interacting and visualizing results. The databases accessed by a GIS system include geographic information (shoreline, location where sampling occurred, location of pollutants, location of monitoring stations, etc.) and attribute information (salinity, depth, temperature, levels of nutrients, pollution concentrations by type of pollutant, etc.). Publicly available data, such as, bathymetry, sea currents, are considered at a different authorization level than data that are not publicly available, such as, pollution levels, fishery stock, etc.
A number of example demonstrator actions the prototype will make available are as follows:
Specifically, a fully 3D hydrodynamic model will show the general circulation and thermocline fluxes in the Cretan Sea. Based on the above model, which produces the necessary hydrodynamic information, a general model for the transport (advective - diffusive) of conservative or non-conservative mass constituents will provide the concentrations of pollutants (domestic sewage, industrial wastes) in the coastal region. Finally, the functional components (phytoplankton, zooplankton, bacteria, detritus, and benthos) as well as the important processes (nutrient cycling, transfer of carbon among the functional components) in the Cretan Sea ecosystem will be visualized via VRML. The simulated processes for the Cretan Sea is displayed. In addition, thematic maps that demonstrate the spatial distribution of various abiotic (like texture of sediments, organic carbon, pheopigments, etc) factors as well as biotic (like diversity, abundance of the main communities) that are characteristic of the coastal environment will be shown. Moreover, thematic maps with the spatial distribution of certain pollutants, like concentration of heavy metals or pathogens will also be shown.
A system such as THETIS does not exist today anywhere in the world.
Recently, there has been considerable interest for such systems, mainly in the USA but also in the European Union. There is a parallel effort in the USA to develop a system for commercial and naval applications, and the National Oceanic and Atmospheric Administration (NOAA) has issued Requests for Proposals on related topics. In addition, the Raytheon company in the USA, in cooperation with Brazilian companies, will create a similar system, for the Amazon in Brazil [33] <http://www.raytheon.com/press/1997/mar/sivam.html>. Similarly, the UK Government Environment Agency (EA) has found difficulty in integrating its considerable data sets. Accordingly, the EA has recently announced an invitation for a feasibility study to investigate how the problem of data integration can be solved. In the USA, U.S. GLOBEC (GLOBal ocean ECosystems dynamics) is a research program organized by oceanographers and fisheries scientists to address the question of how global climate change may affect the abundance and production of animals in the sea. [34] The site, <http://www.usglobec.berkeley.edu./usglobec/globec.homepage.html is an information server communicating the research output and related activities to the interested users. It also links to the Japan GLOBEC web site.
The THETIS is viewed as a digital library collection of multimedia information and scientific models and visualization tools which one needs to locate and use for the purpose of coastal management. We also note that the Alexandria project in the USA has some of the THETIS capabilities . Moreover, there are related environmental projects in the subject of coastal zone management both in Europe and in the US. We summarize one such global initiative, the GOOS project .
The goal of the Alexandria project, underway at the University of California at Santa Barbara (departments of Computer Science and Geography), is to build a distributed digital library for geographically referenced materials. The project was initiated in the fall of 1994 under the sponsorship of the Digital Libraries Initiatives (DLI), a joint effort by three agencies of the US federal government. A central function of the Alexandria Project is to provide users with access to a large range of digital materials, ranging from maps and images to text and multimedia, in terms of geographical reference [3].
The Global Ocean Observing System GOOS project is a scientifically-based, long-term, international program with the primary goal of providing practical benefits to society. The main elements of the system are the collection and timely distribution of oceanic data and products, including assessments, assimilation of data into numerical prediction models, the development and transfer of technology, and capacity building within participating Member states to develop analysis and application capability. GOOS was established in 1993 by the Intergovernmental Oceanographic Commission (IOC), the World Meteorological Organization (WMO), the United Nations Environment Program (UNEP) and the International Council for Scientific Unions (ICSU). GOOS is being implemented by national facilities and services. There are major planned activities for GOOS in the USA and Europe known as USGOOS and EuroGOOS. In the US, GOOS activities are coordinated by the National Oceanic and Atmospheric Administration (NOAA) and seven federal agencies participate in GOOS related-programs and deliberations. IFREMER in France and the Institution of Marine Biology of Crete (IMBC) are associated with EuroGOOS. Current EuroGOOS activities include surveys of operational marine data requirements for European users and of technology systems used successfully in operational oceanography; a data policy for operational oceanography in Europe; and, a major European conference (October 1996) in the Hague on operational oceanography. EuroGOOS serves also as a forum for the formation of partnerships for joint research and development projects. There is considerable potential synergy between EuroGOOS and the partnership developed in the present project.
The EDMED project (European Marine Data Catalogue) is the most relevant to THETIS; it is a catalogue of metadata which states who in Europe has collected what and where it is. It is then left to the individuals to contact the organization to obtain the data.
The COSME project is at AEROSPATIALE and is summarized in [26]. The MEDCOAST project is an initiative of Mediterranean countries for cooperating on projects related to coastal zone management of the Mediterranean coastal zones.
As described in this paper, the THETIS system is also viewed as a digital library of data repositories, which also addresses and provides for the visualization needs of such a heterogeneous collection. It integrates all repositories into a interoperable system accessed via the Web that is transparent to the user. Physical sciences appear with a variety of data, data models which produce data, and data processing techniques which also provide synthetic data. Thus, the data in such a library are either raw data or synthetic data. The library also supplies all tools required for searching or creating new data as well for their visualization.
Notes
References