|
|
|
| P R I N T E R - F R I E N D L Y F O R M A T | Return to Article |
D-Lib Magazine
November/December 2014
Volume 20, Number 11/12
D-Lib Magazine
November/December 2014
Volume 20, Number 11/12
Table of Contents
Efficient Blocking Method for a Large Scale Citation Matching
Mateusz Fedoryszak and Łukasz Bolikowski
University of Warsaw, Poland
{m.fedoryszak, l.bolikowski}@icm.edu.pl
doi:10.1045/november14-fedoryszak
Abstract
Most commonly the first part of record deduplication is blocking. During this phase, roughly similar entities are grouped into blocks where more exact clustering is performed. We present a blocking method for citation matching based on hash functions. A blocking workflow implemented in Apache Hadoop is outlined. A few hash functions are proposed and compared with a particular concern about feasibility of their usage with big data. The possibility of combining various hash functions is investigated. Finally, some technical details related to full citation matching workflow implementation are revealed.
Keywords: Blocking, Citation Matching, Record Deduplication, Map-reduce, Apache Hadoop
1. Introduction
Record deduplication, entity resolution, data linking, object matching are all names of similar processes. As the amounts of data we are dealing with grow larger, the ability to tell which objects are unique and which are merely duplicates is becoming increasingly important. It is also interesting that the challenges we face change as the scale of our work changes. Different problems will arise depending on whether we are to deduplicate one thousand or one million records.
Nevertheless, the basic data linking workflow is usually unaltered. First of all, the data is grouped in so called blocks. We assume no entries in two distinct blocks will be deduplicated, i.e. merged. Then, similarity among all pairs in a given blocks is computed and objects are clustered using an arbitrary algorithm. Although other indexing techniques can be used instead of blocking, as demonstrated by Christen [1], the former seems to remain most commonly used. There are many tools implementing this workflow [8], also in distributed environment [9, 11]).
In this paper, we will focus on citation matching task, i.e. creating links between a bibliography entry and the referenced publication record in a database. Assuming that a citation is, in a sense, a duplicate of referenced document metadata record the problem is reduced to the deduplication task. Citation matching has been studied for a long time [3, 7], also using big data tools [4] yet some issues remain unsolved. One of them is blocking crafted for this particular task. That will be the main concern of this article.
A blocking method using hash functions shall be outlined. We will propose a basic blocking workflow to be implemented using map-reduce paradigm. Numerous blocking key generation techniques shall be described, compared and evaluated. The feasibility of their usage with big data will be emphasised. Combinations of various blocking techniques will be demonstrated. Finally, some technicalities will be revealed and a full citation matching workflow will be presented.
2. Blocking
As it has been mentioned, the aim of blocking part is to create groups of entries which will be processed separately. It is used to improve the overall performance of clustering: the smaller blocks, the less pairwise similarities to compute and the greater performance gain. On the other hand, entities that are to be matched should fall into the same block. If they do not, they will never be compared and eventually matched.
Usually one blocks records that have the same value of some attributes. That is difficult to achieve in citation matching, as citation strings are not well-structured. One might try to extract metadata information from a citation string in a process called citation parsing, but those pieces of information often prove not reliable enough: blocking is the first step of a bigger process and even small mistakes will propagate through the workflow.
This leads us to the main point of the method proposed in this paper: perhaps we should try to transform citation into its hash or fingerprint and treat them as blocking keys. In the most simple approach, for each record only one blocking key is generated, but in our solution multiple keys may be created as well and the entity will be considered a potential match in all of blocks associated with any of its keys. This bears some resemblance to canopy clustering introduced by McCallum [10].
2.1 Blocking workflow
Before proceeding to the description of specific hash functions, we will present the general blocking workflow. It was implemented using Apache Hadoop and map-reduce paradigm. It is assumed that data is stored in HDFS (Hadoop Distributed File System) using sequence files.
The whole process is depicted in Figure 1. First of all, citations are extracted from a database. For each of them hashes are generated and pairs with a hash and citation ID are returned. In a similar manner the metadata records for documents are processed. In the next step, entities with the same hash are grouped together. Hadoop internal mechanisms are used to ensure that all document IDs will occur first.
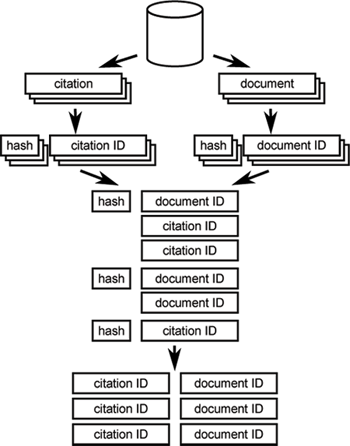
Figure 1: Blocking Workflow
Cross product of citation and document IDs of the same hash is computed resulting in a list of pairs. This requires quadratic space with respect to group size, thus some groups may yield enormous number of pairs. That is why sometimes a limit on the group size is introduced and all of them which exceed such limit are omitted. Such approach is justified by the fact that for each entity we generate multiple blocking keys, so it might be linked regardless of this omission. What is more, overly-popular hashes do not bear much information in any case.
Eventually, returned records form an input for pairwise similarity comparison. Nevertheless, such data may contain duplicates if a citation is linked with a document in several distinct blocks. In such case, algorithm output might be even further limited by grouping pairs by citation ID and taking into account only several documents most commonly assigned to a given citation.
Note that a group is created even if it contains only documents or only citations and it will yield no pairs. That means that we should care not only about minimising the number of pairs returned but also about the number of hashes generated as they may overfill our resources.
2.2 Designed hash functions
Designing a good hash function is not a trivial task. It should convey enough data to identify an article and at the same time limit the number of candidate articles to be matched as much as possible.
Goutorbe [6] states that the set of numbers from a citation constitutes a good fingerprint. He suggests that a few first text tokens should also be included, as they almost always contain author names. Our method is based on this approach, nevertheless, the methods based on publication titles will not be omitted.
A difficulty that is almost immediately encountered is approximate matching. For instance, authors confuse publication dates by one year quite often. It should be possible to match a citation with publication year equal 200 against a metadata record of document published in 2001. It can be achieved by generating a few hashes for a metadata record, with various years close to the one that is stored in a database. This way one citation may fall into many distinct blocks and it might be linked with records from all of them.
In a similar manner another issue can be addressed. Sometimes in a citation string we find two distinct numbers that might be a publication year. In this situation, also several hashes are generated. One might be concerned if the overall number of hashes would not be too large to handle. This matter will be taken into consideration in the evaluation section.
In the rest of this section a normalisation process will be presented and a detailed description of our hash functions will be given.
2.2.1 Normalisation
When generating hashes, citation strings are normalised, i.e. they are lowercased and diacritics are removed. Punctuation marks are also removed. Tokens shorter than 3 characters are not taken into account.
2.2.2 Baseline
To begin with we need a simple hash function to serve as a baseline. The best idea seems to be using all tokens in a citation as hashes. Note that in such case our blocking method gets reduced to finding metadata records that have the most tokens in common with a given citation. Similar method was proposed as a baseline long ago by Giles, et al. [5]. Interestingly, that is how many users perform manual citation resolution: they just paste a reference string into a search engine and select the desired paper among search results.
2.2.3 Bigrams
If we are already taking into account single tokens, why not try pairs? For each citation we will generate all its bigrams (i.e. sequences of two consecutive words) as hashes. For document record we will generate bigrams within authors and title fields. It is most probable, however, that we will find matches only in the title: token positions within author field depend on used citation style. Other fields are not taken into account as journal names in citations are usually abbreviated and many other fields, such as publication year or issue, are unigrams. What is worse, many citation strings, especially in Physics or Chemistry, do not contain publication title at all.
2.2.4 name-year
This function generates hashes in a form name#year. For a citation, year is any number extracted from a string between 1900 and 2050. name is any of four first distinct text tokens — hashes are generated for each of them. For a metadata record, year and name are extracted from appropriate fields.
There are two variants of this function: strict and approximate. For approximate one, metadata hashes are generated for a given year, the previous and the next.
2.2.5 name-year-pages
Here, generated hashes take form name#year#bpage#epage. name and year are defined as in the previous function. In a citation string, bpage and epage are any numbers from a citation string such that bpage < epage and bpage, epage ≠ year, unless year value occurs multiple times in a citation string. For a record, bpage and epage lookup is limited to pages field. We have strict and approximate variant. In the latter, we approximate year, bpage and epage values.
Another type of variance is also considered: optimistic and pessimistic. In the optimistic variant, we parse citation string using CERMINE [12] and limit lookup to adequate metadata fields generated by this tool. So in total there are four variants of this hash function.
2.2.6 name-year-numn
name#year#num1#...#numn is the form of generated citations, n ∈ {1, 2, 3}. num1...numn are sorted; for citation they are any numbers from a raw text, for a record, they are taken from pages, issue and volume fields. Similarly to the name-year hash, approximate variant is also considered.
3. Evaluation
3.1 Dataset
The dataset used to evaluate the proposed method is based on the Open Access Subset of PubMed Central. It contains publications along with their metadata and bibliography in XML-based format. We have extracted all citations that had PubMed ID of target document specified. Some citations are represented merely as metadata fields and others also preserve original citation formatting. For our purposes we have used only the latter. That resulted in a set of 528,333 documents and 3,688,770 citations out of which 321,396 were resolvable (i.e. were pointing to the documents available in the dataset).
3.2 Metrics
Recall — the percentage of true citation → document links that are maintained by the heuristic.
Precision — the percentage of citation → document links returned by algorithm that are correct.
Intermediate data — total number of hashes and pairs generated (before selecting the most popular ones).
Candidate pairs — number of pairs returned by heuristic for further assessment.
F-measure is not used as in our task precision is much smaller than recall and their harmonic mean will not give much insight.
Of course the most important measure is recall as it tells if all the necessary information is preserved by the heuristic. Nevertheless when working with big datasets we need to bear in mind that our computation resources and storage are limited. That is why amount of intermediate data and number pairs for exact assessment is also measured. The best heuristic would be the one maintaining high recall while fitting into desired resource boundaries.
3.3 Results
Hash function evaluation results on PubMed dataset are presented in Table 1. We have proposed several versions of each method which differ in terms of maximum size of hash group and number of candidate documents per citation as described in Section 2.1 above.
Table 1: Requests for Docear's web service
| Hash function | Bucket size limit | Candidates per citation limit |
Precision [%] | Recall [%] | Intermediate data [106] |
To asses [103] |
| baseline | 100 1000 10000 10000 1000000 |
30 30 10 30 30 |
3.17 0.90 0.89 0.29 0.29 |
44.03 73.18 88.68 97.88 97.88 |
91.2 115.8 221.2 221.2 2 562.5 |
4 458.6 26 083.7 49 747.8 114 223.8 114 223.8 |
| bigrams | 10 10 100 100 1000 10000 10000 |
10 30 10 30 30 10 30 |
11.82 11.75 3.01 2.85 0.82 0.97 0.40 |
65.61 65.61 92.68 92.70 97.31 97.81 98.17 |
84.0 84.0 94.7 94.7 133.0 285.9 285.9 |
1 784.2 1 794.0 9 889.8 10 446.9 38 296.5 32 353.5 79 329.5 |
| name-year (approx.) | 1000 10000 — |
30 30 — |
1.42 0.68 0.03 |
75.60 80.29 92.35 |
40.7 78.8 928.1 |
17 098.1 37 932.6 862 357.2 |
| name-year (strict) | 1000 10000 — |
30 30 — |
2.52 1.11 0.10 |
77.94 82.23 90.20 |
28.5 48.2 322.0 |
9 940.4 23 761.9 290 940.9 |
| name-year-pages (approx. pessimistic) | 1000 — |
30 — |
9.93 7.36 |
45.85 45.87 |
172.4 173.1 |
1 484.0 2 003.3 |
| name-year-pages (strict pessimistic) | 1000 — |
30 — |
56.33 53.68 |
42.46 42.46 |
132.8 132.8 |
242.3 254.2 |
| name-year-pages (approx. optimistic) | 1000 — |
30 — |
78.54 78.20 |
7.83 7.83 |
42.5 42.5 |
32.0 32.2 |
| name-year-pages (strict optimistic) | 1000 — |
30 — |
98.37 98.37 |
7.26 7.26 |
4.8 4.8 |
23.7 23.7 |
| name-year-num (approx.) | 1000 — |
30 — |
1.21 0.14 |
88.53 92.20 |
170.6 452.9 |
23 591.9 218 107.2 |
| name-year-num (strict) | 1000 — |
30 — |
3.61 0.88 |
88.33 90.04 |
85.8 116.6 |
7 864.1 32 715.0 |
| name-year-num2 (approx.) | 1000 — |
30 — |
3.20 1.19 |
69.85 70.43 |
359.1 376.1 |
7 023.3 19 035.8 |
| name-year-num2 (strict) | 1000 — |
30 — |
18.36 14.83 |
66.57 66.62 |
141.6 141.9 |
1 165.2 1 441.1 |
| name-year-num3 (approx.) | 1000 — |
30 — |
19.06 17.61 |
47.10 47.14 |
617.0 617.2 |
794.3 860.3 |
| name-year-num3 (strict) | 1000 — |
30 — |
83.97 83.97 |
43.37 43.41 |
257.6 257.6 |
166.0 166.1 |
To begin with, baseline algorithm performs well in terms of recall. However, It might be desirable to limit the amount of resources needed. Bigram-based hash function looks very promising, but one must bear in mind that it might be rendered completely useful when dealing with citations without publication title. Although very uncommon in our dataset, in some disciplines such references are dominant.
It might not be obvious, but baseline heuristic does not take the publication year into account. As it has been mentioned, the biggest groups of hashes have been pruned. Publication years fall into such over-sized buckets. On the other hand, the simplest function explicitly relying on publication year, namely name-year hash function, performs very well. It reflects the common belief that author name and publication year is enough to identify a paper.
name-year-pages in pessimistic, strict variant shows a good trade-off between precision and recall, maintaining intermediate data within a reasonable limit. Functions from n family in strict variant clearly show their power: name-year-num3 function is able to achieve very high precision with fair recall. The only problem is not so modest volume of intermediate data.
When comparing results of strict and approximate versions of hash functions, one sees that approximation positively impacts recall, but the amount of data to be processed increases significantly. It is notably difficult when several numbers are approximated, e.g. in name-year-num3 heuristic. Interesting are results obtained when relying on citation parsing: very high precision is achieved and only a few pairs need further processing. Unfortunately, recall is very low.
The results also show it is sometimes beneficial to limit groups size or candidates per citation. It is especially true for name-year heuristic in strict variant with groups limited to 1000 and candidates to 30: we are able to trade in 8 percent points for over 6 times less intermediate data needed and 10 times less pairs for further assessment.
Unfortunately, the results clearly demonstrate one must decide what he or she wants to optimise: either recall, amount of intermediate data or number pairs that need assessment.
Figures 2 and 3 show relationships between recall and resource requirements. Due to the limited space, we have decided to omit some functions.
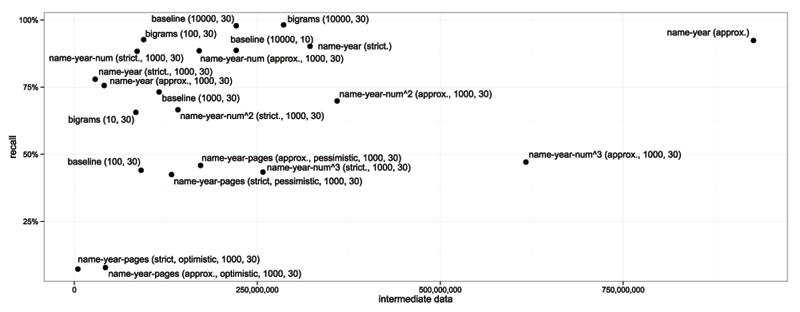
Figure 2: Recall vs intermediate data
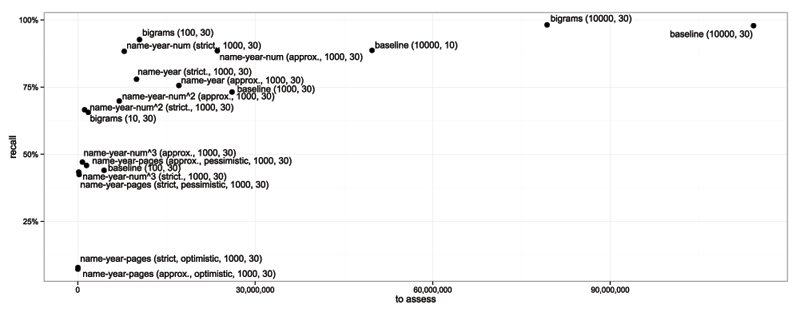
Figure 3: Recall vs number of pairs for exact assessment
4. Combination
The evaluation has shown that one usually must make tradeoffs between recall and the amount of resources needed to compute heuristic. This suggests further research opportunities: perhaps it is possible to combine various methods to achieve better results.
The idea would be just to use various hash functions in a sequence. First of all, one method is used to generate heuristic matches. Then, the next one is taken and applied on citations that were assigned no candidate citations. Further variants may be applied in a similar manner. Functions using less resources should be applied first.
Obtained results are presented in Table 2. Several combinations have been designed, description of each consists of statistics of hash functions used in a sequence and a summary.
Table 2: Combinations of hash functions
| Hash function | Bucket size limit | Candidates per citation limit |
Precision [%] | Recall [%] | Intermediate data [106] |
To asses [103] |
| name-year-pages (strict optimistic) name-year (strict) name-year (strict) bigrams |
— 1000 10000 10000 |
— 30 30 30 |
98.37 2.31 0.13 0.08 |
7.26 71.19 2.90 6.29 |
4.8 28.3 19.5 134.8 |
23.7 9 898.9 7 380.4 23 849.2 |
| Sum | — | 87.64 | 187.4 | 41 152.3 | ||
| name-year-pages (strict optimistic) name-year-pages (strict pessimistic) bigrams bigrams |
— — 100 10000 |
— — 30 30 |
98.37 49.15 1.65 0.03 |
7.26 35.19 52.33 2.07 |
4.8 130.4 89.8 108.7 |
23.7 230.1 10 189.8 19 374.9 |
| Sum | — | 96.86 | 333.7 | 29 818.6 | ||
| name-year-pages (strict optimistic) bigrams bigrams |
— 100 10000 |
— 30 30 |
98.37 2.65 0.07 |
7.26 86.07 4.42 |
4.8 94.1 103.7 |
23.7 10 428.6 20 130.1 |
| Sum | — | 97.76 | 202.6 | 30 582.5 | ||
| name-year-pages (strict optimistic) name-year-num3 (strict) bigrams bigrams bigrams |
— — 10 100 10000 |
— — 10 30 30 |
98.37 81.64 7.45 0.59 0.03 |
7.26 36.14 40.56 12.03 1.74 |
4.8 154.3 80.4 63.2 96.1 |
23.7 142.3 1 750.2 6 531.5 16 675.5 |
| Sum | — | 97.73 | 398.9 | 25 123.2 | ||
The first row demonstrates our naïve attempt to limit the amount of intermediate data generated. A decision was made to use a sequence of name-year-pages (strict, optimistic), name-year (with group size limit set to 1000 and then 10000) and eventually bigrams (with group size limit 10000 and candidates limit 30). The method seemed very promising, but the results turned out to be very disappointing: significant recall loss was encountered. That is because some of resolvable citations are assigned candidates by initial heuristic but none of them is correct. When in combination, subsequent heuristics do not take it into account because it already has the candidate.
It was crucial therefore to assess how many citations are eliminated by each heuristic. These results are presented in Table 3. We measure how many resolvable citations were assigned candidates none of which was correct and divide that by total citation number. It turns out that some heuristics are not suitable to be used in combination. Therefore some functions that seemed to be perfect candidates for a first function in a sequence, such as name-year or name-year-numn for n = 1, 2, cannot be effectively used as such. Bearing that in mind other combinations were designed, as presented in further rows of Table 2. Their results prove that significant improvements in resource requirements are be obtained if some recall can be sacrificed. Generally, it is easier to limit the number of pairs returned than the amount of intermediate data.
Table 3: Elimination factors
| Hash function | Bucket size limit | Candidates per citation limit |
Eliminated [%] |
| baseline | 100 1000 10000 10000 |
30 30 10 30 |
2.48 3.65 6.70 1.91 |
| bigrams | 10 10 100 100 1000 10000 10000 |
10 30 10 30 30 10 30 |
1.18 1.17 1.44 1.43 1.13 1.28 0.94 |
| name-year (approx.) | 1000 10000 — |
30 30 — |
12.39 12.61 5.07 |
| name-year (strict) | 1000 10000 — |
30 30 — |
9.80 9.98 5.81 |
| name-year-pages (approx. pessimistic) | 1000 — |
30 — |
8.98 9.23 |
| name-year-pages (strict pessimistic) | 1000 — |
30 — |
1.78 1.80 |
| name-year-pages (approx. optimistic) | 1000 — |
30 — |
0.02 0.02 |
| name-year-pages (strict optimistic) | 1000 — |
30 — |
0.01 0.01 |
| name-year-num (approx.) | 1000 — |
30 — |
5.97 2.85 |
| name-year-num (strict) | 1000 — |
30 — |
4.36 2.96 |
| name-year-num2 (approx.) | 1000 — |
30 — |
12.31 11.85 |
| name-year-num2 (strict) | 1000 — |
30 — |
5.56 5.55 |
| name-year-num3 (approx.) | 1000 — |
30 — |
4.17 4.15 |
| name-year-num3 (strict) | 1000 — |
30 — |
0.62 0.62 |
It is also worth mentioning that another technique of combining hash functions can be used. It has been assumed that a sequence of heuristic functions is run and then exact matching is performed on their results. However, the process may be organised in a different way: instead of subsequent execution of several heuristic variances, at first a full matching workflow, including the exact assessment, is run with one hash function. Then, unmatched citations are passed to second execution, with another function, and so forth. Even though some false candidates may be returned by heuristic, it is probable they will be rejected by exact matcher and potentially much less recall will be lost. Nevertheless, in this paper we wanted to focus only on the heuristic part.
5. Implementation
Described blocking work flow has been implemented as a part of CoAnSys project [2]. It acts as the first part of the citation matching process. In the second one, pairwise similarities between a citation and candidate document metadata are computed and the candidate with the highest score is selected. To obtain this similarity, various similarity metrics such as common tokens fraction, common q-grams fraction, edit distance and longest common character subsequence are defined on metadata extracted from bibliographic entries using CRF-based parser provided by CERMINE [12] as well as on raw citation string. The overall result is obtained by combining them by means of linear SVM. This part has already been presented elsewhere [3].
Individual map-reduce jobs were written in Scala and bound together using Apache Oozie. Most of the prototyping was done by means of Nicta Scoobi. The source code can be obtained from GitHub.
6. Summary and Future Work
In this paper we have presented a method for a large scale citation blocking using hash functions. A blocking workflow implementable in map-reduce paradigm has been demonstrated. Various hash functions were presented and evaluated.
Each of them has its strong and weak sides, which make them fit different scenarios. When citation strings contain document titles, it is probably the best idea to use bigram-based hashes. name-year-pages and name-year-numn will be preferable when dealing with references to journal publications which contain various numbers (e.g. pages, issue, volume) enabling straightforward document identification. name-year method is probably the most generic one, offering very good trade-off between recall and the amount of resources used.
Thanks to diversity of hash function types, they can be combined to form a new, better method, although one must carefully examine if it really helps. Nevertheless, with a bit of caution one can greatly improve a resource-efficiency without much loss in terms of recall.
As it has been mentioned, in the future it would be very interesting to experiment with alternative methods of combining hash functions. Probably the better results can be achieved when subsequent round of hash generation is executed after exact matching step, when it is more certain if a citation needs further matching. On the other hand, maybe some various hashing methods may be used simultaneously in one heuristic round. Small yet smart optimisations in hash generation process may also improve the effectiveness of the method. Deeper analysis and simple parsing of citation string may be incorporated. Finally, the scalability of our solution should be investigated even further: what today is considered a big scale is just an ordinary scale of tomorrow.
Acknowledgements
This work has been partially supported by the European Commission as part of the FP7 project OpenAIREplus (grant no. 283595).
References
[1] P. Christen. A survey of indexing techniques for scalable record linkage and deduplication. IEEE Transactions on Knowledge and Data Engineering, 24(9):1537—1555, 2012. http://doi.org/10.1109/TKDE.2011.127
[2] P. Dendek, A. Czeczko, M. Fedoryszak, A. Kawa, P. Wendykier, and L. Bolikowski. Content analysis of scientific articles in Apache Hadoop ecosystem. In R. Bembenik, L. Skonieczny, H. Rybinski, M. Kryszkiewicz, and M. Niezgodka, editors, Intelligent Tools for Building a Scientific Information Platform: From Research to Implementation, volume 541 of Studies in Computational Intelligence, pages 157—172. Springer International Publishing, 2014. http://doi.org/10.1007/978-3-319-04714-0_10
[3] M. Fedoryszak, L. Bolikowski, D. Tkaczyk, and K. Wojciechowski. Methodology for evaluating citation parsing and matching. In R. Bembenik, L. Skonieczny, H. Rybinski, M. Kryszkiewicz, and M. Niezgodka, editors, Intelligent Tools for Building a Scientific Information Platform, volume 467 of Studies in Computational Intelligence, pages 145—154. Springer Berlin Heidelberg, 2013. http://doi.org/10.1007/978-3-642-35647-6_11
[4] M. Fedoryszak, D. Tkaczyk, and L. Bolikowski. Large scale citation matching using Apache Hadoop. In T. Aalberg, C. Papatheodorou, M. Dobreva, G. Tsakonas, and C. Farrugia, editors, Research and Advanced Technology for Digital Libraries, volume 8092 of Lecture Notes in Computer Science, pages 362—365. Springer Berlin Heidelberg, 2013. http://doi.org/10.1007/978-3-642-40501-3_37
[5] C. L. Giles, K. D. Bollacker, and S. Lawrence. Citeseer: An automatic citation indexing system. In Proceedings of the third ACM conference on Digital libraries, pages 89—98. ACM, 1998. http://doi.org/10.1145/276675.276685
[6] C. Goutorbe. Document interlinking in a Digital Math Library. In Towards a Digital Mathematics Library, pages 85—94, 2009.
[7] S. M. Hitchcock, L. A. Carr, S. W. Harris, J. M. N. Hey, and W. Hall. Citation Linking: Improving Access to Online Journals. Proceedings of Digital Libraries 97, pages 115—122, 1997. http://doi.org/10.1145/263690.263804
[8] P. Jurczyk, J. J. Lu, L. Xiong, J. D. Cragan, and A. Correa. Fine-grained record integration and linkage tool. Birth Defects Research Part A: Clinical and Molecular Teratology, 82(11):822—829, 2008. http://doi.org/10.1002/bdra.20521
[9] L. Kolb, A. Thor, and E. Rahm. Dedoop: efficient deduplication with Hadoop. Proceedings of the VLDB Endowment, 5(12):1878—1881, 2012. http://doi.org/10.14778/2367502.2367527
[10] A. McCallum, K. Nigam, and L. H. Ungar. Efficient clustering of high-dimensional data sets with application to reference matching. In Proceedings of the Sixth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, KDD '00, pages 169—178, New York, NY, USA, 2000. ACM. http://doi.org/10.1145/347090.347123
[11] M. Paradies, S. Malaika, J. Siméon, S. Khatchadourian, and K.-U. Sattler. Entity matching for semistructured data in the Cloud. In SAC '12, page 453. ACM Press, March 2012. http://doi.org/10.1145/2245276.2245363
[12] D. Tkaczyk, P. Szostek, P. J. Dendek, M. Fedoryszak, and L. Bolikowski. Cermine - automatic extraction of metadata and references from scientific literature. In 11th IAPR International Workshop on Document Analysis Systems, pages 217—221, 2014. http://doi.org/10.1109/DAS.2014.63
About the Authors
 |
Mateusz Fedoryszak is a Reasercher and Software Developer at the Interdisciplinary Centre for Mathematical and Computational Modelling at University of Warsaw (ICM UW). He received a M.Sc. in Computer Science from the University of Warsaw for a thesis on automated analysis of ancient manuscripts. Currently his research interests are focused on scalable data deduplication, string similarity measures, data analysis and mining. |
 |
Łukasz Bolikowski is an Assistant Professor at the Interdisciplinary Centre for Mathematical and Computational Modelling at University of Warsaw (ICM UW). He defended his PhD thesis on semantic network analysis at Systems Research Institute of Polish Academy of Sciences. He is a leader of a research group focusing on scalable knowledge discovery in scholarly publications. He has contributed to a number of European projects, including DRIVER II, EuDML, OpenAIREplus. Earlier at ICM UW he specialized in construction of mathematical models and their optimization on High Performace Computing architectures. |
|
|
|
| P R I N T E R - F R I E N D L Y F O R M A T | Return to Article |