|
|
|
| P R I N T E R - F R I E N D L Y F O R M A T | Return to Article |
D-Lib Magazine
November/December 2013
Volume 19, Number 11/12
Schema for the Integration of Web Applications
Theo van Veen
Koninklijke Bibliotheek
theo.vanveen@kb.nl
doi:10.1045/november2013-vanveen
Abstract
Web search results form the basis for a variety of further actions by users, including requesting related information in Wikipedia, language translation, transforming an abstract into a word cloud, etc., actions which the provider of the original data is typically unaware of. SIWA (Schema for the Integration of Web Applications) was developed to describe how a user wants data fields from a web application to be used as input for other web applications. We propose a mechanism to add the appropriate links to presented data. The intent is to develop a standard for these service integration descriptions that can be shared by users and content providers. Originally developed as part of the EuropeanaConnect project but not highly publicized, SIWA has been simplified and improved in an effort to lower the implementation barrier. This article discusses the recent changes in approach with respect to SIWA, and current trends in the use of the Internet, that should increase the chance of a broad adoption of this concept of service integration, and hopefully trigger new initiatives supporting user defined service integration by means of SIWA.
Introduction to SIWA
When data is presented in a web page, the user might want to use this data by copying and pasting it as input into another website or web service like Google Search, which is commonly available for many platforms when text is copied into the copy and paste buffer. The user might also want the response to be integrated automatically with the original presented data, for example an abstract replaced by its translation. When users need such functionality frequently, it would be convenient to have that functionality available automatically as a link added to the field that serves as input for the service providing that functionality. Preferably that should work for all the web sites that the user often visits. There may be services that an advanced user wants to use for doing something with the data, while the content provider isn't aware of those services or how they have to be invoked. Suppose a researcher wants to analyze abstracts from a specific website with a named entity recognition service (NER), and he wants to use the output of that service as input into an annotation service. Our aim is that this researcher can integrate those services immediately with the website without having to install software, just by telling the originating web site in an appropriate description language: "for the abstract field I want to have a link to invoke the NER service with URL X and I want to use the result of that service as input for the annotation service with URL Y".
If this approach works for one website, users may want to use it for other websites and if it works for one user, more users might be interested. That is where SIWA as a proposed standard for a description language comes in. The SIWA model allows specifying the service to be invoked, the fields that serve as input, how to construct the input from the presented data, how the output is used, etc. By supporting SIWA content providers can have their website extended with specific functionalities by advanced users, without having the burden of new software releases, without extra system load and without security risks on the provider's site, just by providing extra links to external services. Additionally, providers can use SIWA as a configuration language for their own use. The SIWA concept is illustrated in Figure 1. More advanced examples are shown here.

Figure 1: Simplified illustration of the SIWA concept: a) the original presentation. b) A SIWA record specifying that the "author" field should trigger links to Google images and Wikipedia, the URLs of both services and for Google images that the value of the author field should go into URL-parameter "q". c) The presentation after interpreting the SIWA record. The service links are supposed to be shown only after clicking "»".
It is nowadays quite common to provide links for sharing information with Twitter and Facebook without the user having been asked for these links. Why not give the user the option to add his own links? Why try to find out what users want instead of giving them the freedom to decide for themselves what to do? Why offer links to things that perhaps are not used instead of allowing users to add personal context-sensitive links that they want to use more often?
Like any standard, a critical mass of implementations and a very low entry barrier is required before skilled users start creating service integration descriptions. When SIWA is adopted by enough content providers it is expected that service integration descriptions will become available in registries or via Google. This article explains the potential and benefits of SIWA in relation to the effort required to implement it.
History and background
The idea behind creating a schema for service integration descriptions is not new1. Even earlier, when developing a metadata model for The European Library, the idea was that metadata had to serve functions which could be illustrated by means of a functionality matrix with metadata elements on one axis and functions on the other axis. Metadata fields serve functionality that is realized by services and can be considered as a potential trigger for the portal to initiate them. How the portal has to deal with these services, like how and when to invoke and how to use the output, has to be described in a machine readable way. Because different users may require different functionality or services, the idea came up to let users compose the set of services they want and also give them the possibility to introduce their own preferred services.
The original schema for service integration was developed in the TELplus project and later refined in the EuropeanaConnect project, resulting in SIWA and intended to be used in the Europeana portal. SIWA was supposed to enable the description of all aspects of service integration for quite a number of different services with different behavior. It is different from models like Web Application Description Language (WADL) and Web Services Description Language (WSDL) which actually focus on the description of web services rather than the semantic integration and the actual usage. SIWA also differs from Web Service Business Process Execution Language (WS-BPEL) and Yahoo pipes because of its focus on integration in the client rather than at the server level.
The SIWA approach was not given much publicity. The schema had become quite complex because it was intended to deal with many specific situations. In the Europeana portal, service integration was implemented in its most simple form, without context dependent links and without the user being able to specify his own services, which was the most important motivation for SIWA. Recently it was taken out of the portal. A more complete and advanced implementation was available in the KB research environment but not in a production environment. It did not attract website developers because the implementation barrier seemed to be high. However, each time the concept was demonstrated with this research implementation the reactions were positive and enthusiastic.
Besides the implementation barrier there were several other aspects that were considered show-stoppers for a broader adoption of SIWA. The recent changes discussed in this article have addressed those aspects, in order to lower the implementation barrier for SIWA support. One of these changes is the simplification of the schema. The original schema is still available and was used as the basis for the new JSON schema as discussed in this article.
Getting started with SIWA
For many initiatives the important question is whether it is worth the effort to implement or use it. Implementing SIWA is relatively straightforward, requiring simply the following steps:
- The web page with the search results has to mark the data fields, for example by putting them in a span with the field name as item property, for example:
<span itemprop="creator">Albert Einstein</span> - A script has to be included in the page containing the code for SIWA support, for example:
<script src="http://path/siwa_support.js"></script> - An initialization function from this script has to be added to the HTML, for example:
<body onload="SIWAinit()">
Those three steps are all that is required. The implementation effort is considered so small that a lack of resources can hardly be a reason for not supporting SIWA. A SIWA script is available for demonstration purposes and must be copied to the provider's site and might be modified as desired, for example to adapt the look and feel. The concept is described and demonstrated here.
When a page is loaded, the SIWA script will read the service integration descriptions (SIDs) automatically from a location that is specified by the provider or by the user. For each recognized field (e.g. a span element with a specific class) in the presented web page the SIWA script will check whether that field is defined in a SID as a trigger for one or more services. If so, a link to invoke those services will be added to that specific field. The information in the SID is used to generate the request, invoke the service and process the response. Depending on the information in the SID the service may also be invoked automatically.
The basic fields in a SID are the names of the trigger fields, the name and the URL of the service to be invoked and the URL parameters to be used. It is also possible to specify the type of access (like GET, POST, etc.), how to use the response, the type of invocation (e.g. automatic) and the conditions to be met for a service to be presented or invoked. The intention is that a minimum of a priori knowledge is required for invoking a service and using its response. If fields in the SID are not specified one must be able to rely on an appropriate default behavior. The basic behavior is that the service is invoked by a simple deeplink to a web page opened in a new window.
The schema is specified here. SID examples are available here.
Implementation aspects
The implementation described in this paper is just an example. Content providers are free in all respects: free to implement SIWA on the server, free to mix provider defined services with the user defined services, free to store the SIDs on their own server and free in how the SIWA links are presented. The only requirements for claiming SIWA support are 1) the data model should comply with SIWA, and 2) users should be allowed to specify their own SIDs.
In the example, the SIWA script reads the service integration descriptions from a default or user specified location. The provider may offer the option to upload the SIDs and process them on the server. The SIWA script will search for elements in the HTML that correspond to metadata fields as defined in the SID. In the example these elements are HTML spans with "itemprop" attributes specifying field names like "title" or "subject". See schema.org for more information. However, this is not a requirement: the SIWA script is the responsibility of the content provider and only has to deal with the HTML used by that content provider.
In the example service, integration takes place in the browser and not on the server side. This has the advantage that it does not imply any extra system load and the web site provider is not really involved in requests to other services. The content provider is not responsible for redistribution of services because these services are specified and initiated by the user: the provider controls the SIWA code; the user controls the SIDs.
It is possible to use a browser extension to contain the SIWA code. From the perspective of the content provider, however, this is not desirable because the provider does not have any control and cannot optimize the integration with its own website. From the perspective of the user it is not desirable either because the user does not want to use this mechanism automatically with non-trusted providers. This would easily be the case with a generic browser extension and could introduce the danger of misuse by non-trusted parties. Besides that, browser extensions are browser dependent. A browser extension requires installation by the user and will need configuration to adapt it for different providers. When SIWA is offered by the provider there is no barrier for using SIWA until the user wants to modify the default list of services.
An alternative way to implement SIWA is on the server. This makes it easier to keep control over the services that users want to add. In that case the provider becomes responsible for the services that he offers to the user. This may be a disadvantage because for some services it may be illegal for the provider to integrate them in the website while integration by the user only for personal use would probably be allowed.
Figure 2 illustrates two typical setups for implementing SIWA.
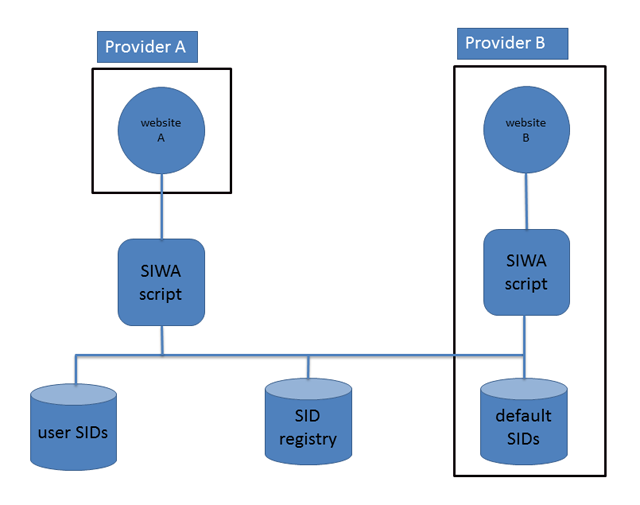
Figure 2: Different ways to implement and use SIWA. Provider A only links to an external SIWA script. Provider B uses its own SIWA script with its own default SIDs. The SIWA script let the user combine SIDs from different sources.
The SIWA concept is comparable with OpenURL. At least initially, OpenURL is being used primarily for linking the user to the so called "appropriate copy", which is the resource for which the user has access permission. This requires the OpenURL provider to be informed about these resources. With SIWA support, the user provides the information with respect to the resources he wants to access himself and the content provider does not have to be aware of the resources for which a user has a subscription. Another difference is that with OpenURL the user is linked to a web page from the OpenURL resolver while in the SIWA concept the services are integrated with the originating page which is considered more user-friendly.
Security
Because the integration of services is supposed to take place in the browser of the user, the provider of the website should not be at risk regarding security. The user may be at risk when using SIWA scripts or SIDs from obscure providers. But, as in many other situations on the Internet, users have to ensure that they are dealing with trusted parties. There may, however, be a legal issue because the providers' SIWA scripts might invoke user-specified services that are not free to use.
The potential of SIWA
In general, when promoting a new initiative, the question is always whether the expected results are really worth the effort. It was argued already that the implementation effort is minimal. What remains to be discussed is whether SIWA has enough potential to make it worth even that little effort. Our target users are the users that are focused on information and on fast navigation within that information, who may care little about a nice presentation.
A first benefit for users is the increased speed of navigation. One does not have to copy data, start a service, paste the copied data as input and retrieve the output of the service. Using SIWA these actions can be started with a single mouse click or automatically. Even if not used on a regular basis, when enough useful services are available via SIWA, the barrier for invoking those services via SIWA is lower than "copy, start service, paste the input". In this way the user will get to related information more easily, and might be better informed.
The automatic invocation of services, for example, for enriching the original data with an image, for translating or converting data or for alerting the user to the presence of related data in another data source, will speed up the information retrieval cycle even more. This will also be the case when chaining services for results of one service being used automatically as input for another service. It is also possible to alert the user automatically about the availability of information he would otherwise not be aware of.
When the barrier to share SIDs is low enough incidental visitors of websites can benefit from the service integration facilitated by advanced users: for instance one click to publish a SID and one click to add a published SID to one's personal SIDs.
But there is more. Researchers wanting to experiment with new services, for example feature extraction, sentiment mining, annotation services, etc., may want to use those services ad hoc on specific content using the website of the provider of that content without the need to install software. With SIWA support these services might be integrated with the interface of the content providers without extra effort other than creating a SID. For using new services being made publicly available, researchers do not have to wait for the content providers to have those services integrated with their web sites. They can more easily share services and compare the results of similar services. These services can be simple because they use the providers website as bases. The individualistic approach of the SIWA concept makes it possible to get context sensitive links in a website on a personal basis without bothering other users.
There are also benefits for the provider in supporting SIWA, among them the psychological effect of giving the user more freedom and control, the availability of extra services via the provider's website which adds value to the contents and may attract more users, and the possibility of using the provider's data as input for external services, e.g. annotation services, which may increase the ways in which the provider's content can be found.
SIWA can also be used by the provider as a simple configuration mechanism for additional functionality. Adding new functionality that is already available as a separate service, can be done without the burden of a new release of the basic software. Last but not least, it will also be easier to differentiate between different user groups by providing SIDs for specific user groups.
When a critical mass is reached we can envision new scenarios that are not restricted to specific domains. Functionality from different application areas can be glued together. Using SIWA offers new ways of exploiting linked data.
Summary of improvements and the changing environment
There were several reasons why the barrier for implementing SIWA support initially appeared rather high that still may wrongly be mentioned as obstacles. Things have changed however, both on the Internet and in our approach. It is now reasonable to expect that the barrier for implementing SIWA support has become much lower. I will discuss here the obstacles for using SIWA and what has been changed.
- The SIWA schema has been simplified.
SIWA was created with complicated use cases in mind and the complexity of the schema made SIWA also complex for simple situations. This made supporting SIWA look complicated. Fields that were used in the demonstration portal only for a specific cases were removed and the format was changed from XML to JSON making integration in web browsers a lot easier.
- A simple implementation example is now available.
SIWA was originally demonstrated with a complex development portal in which SIWA support was completely integrated, and not implemented and available as a simple add-on. Therefore, it did not attract developers, even though it was a quite powerful implementation. SIWA is now demonstrated with sample pages from existing websites. These pages are modified to support SIWA, with the SIWA code available as a separate script. To get started, this script can be used "as is" and copied to the provider's server and only requires the three steps described in the section "Implementing SIWA is simple" to realize SIWA support.
- Users can store and share SIDs more easily.
It is not expected that average users will create personal SIDs. However, nowadays there are many ways to share information even for users with less technical skill. When SIWA is supported, there will be users who are curious enough to play with SIWA using the provider's SIDs as a starting point and modify them and share them with others. When we first started with user defined service integration it was not easy to have personal SIDs available on a web location. Now, many users are familiar with mechanisms like Dropbox for sharing files, making it easier to store personal SIDs and also to share them with others. With HTML5 it is also possible to use local browser storage for storing SIDs. This facilitates building a local personal set of SIDs copied from others.
- Content providers may be more willing to give users control over functionality.
The mind set of web users is still evolving. In the beginning some data providers were afraid of giving access to their content; now they fear that their content will not be found via search engines. In the beginning of service integration development, there was reluctance to allowing users to modify the functionality of web sites, even though it was for personal use only. Crowdsourcing for improving or enriching content, like in Wikipedia, has become more and more accepted. Sharing content with different apps on a smartphone is completely normal. The necessary step to enriching functionality of websites by sharing fields with specific services seems to be small, and support of SIWA might be a starting point to generate crowdsourcing for sharing added functionality as well.
- The "same origin policy" of browsers was a show-stopper for real integration.
Web browsers do not allow web pages to actually read the data coming from other domains. Due to this restriction one can only link to other web pages but not actually use the contents or output of a service. This limitation it was considered a real barrier. There are two trends making this problem slowly disappear. First, more providers make their data available in JSON format which is in most cases accessible in a way that is not restricted by the "same origin policy". Second, there is now a mechanism called CORS, Cross Origin Resource Sharing which offers the possibility to provide access to data without the same origin restriction.
- The attitude with respect to keeping a user on a website might change.
It is important for data providers to get as many page views as possible and therefore they tend to try to keep users on the their websites. A mechanism the helps users to link to other websites was therefore not always appreciated. There are signs that this attitude might be changing in favor of helping users get to the right information rather than preventing users from leaving a site. At the same time, providers probably expect others will link to their content.
Conclusion
SIWA is an easy to use mechanism for enriching websites with user-selected functionality, without the burden of frequent software updates, or putting additional system load on content providers. Earlier implementation barriers have been reduced by recent changes to SIWA, including the introduction of a simpler schema, provision of an easy to follow implementation example, and changing attitudes of content providers who are slowly and gradually becoming more open to offering users some control over functionality of web sites, and encouraging the sharing of links to other providers' content. SIWA's value to both users as content providers will increase as the number of implementations increase, and users share their service integration descriptions with others.
Note
1 van Veen, Theo, Georg Petz, Christian Sadilek, Michel Koppelaar. "Sharing Functionality on the Web: A Proposed Services Infrastructure for The European Library", D-Lib Magazine, Vol. 15, No. 1/2, January/February 2009. http://doi.org/10.1045/january2009-vanveen
About the Author
 |
Theo van Veen has been a member of the research and development department of the Koninklijke Bibliotheek, National Library of the Netherlands since 1998. He got his degree in physics at the Technical University Delft in 1979 and started in 1988 in library automation at the University Library in Utrecht. He has been involved in several projects related to the European Library and Europeana, both hosted at the Koninklijke Bibliotheek. His research interest is currently focussed on the combination of text enrichment, named entities, linked data and service integration. |
|
|
|
| P R I N T E R - F R I E N D L Y F O R M A T | Return to Article |