D-Lib Magazine, May 1997

1. Introduction
2. Why on-the-fly?
2.1 Converting for actual use, not potential use
2.1.1 Case 1: Grolier's Encyclopedia Americana
2.1.2 Case 2: Making of America
2.2 "Re-purposing" and managing data
2.2.1 Flexible delivery
2.2.2 Collection management
3. Conclusion
The University of Michigan's Digital Library Production Service (DLPS) has developed substantial experience with dynamic generation of Web-specific derivatives from non-HTML sources based on several key projects and consideration of how users work with key resources. This article is based on DLPS's experience and resultant policies and practices that guide present and future projects. In a rapidly changing world where the implications of information technologies for broad yet differentiated clienteles are mysterious, we hope that our experience will contribute to a better understanding of practical strategies.
The WWW has long included the ability to offer access to documents stored in formats other than HTML. Beginning with NCSA's "htbin" mechanisms, and soon after using the now widely embraced Common Gateway Interface (CGI), managers of large document collections have been able to store materials in a variety of formats, while offering these documents to a wide consumer base. This was the model used by the author in 1993 (when NCSA introduced Mosaic) to build access to large collections of documents stored in a variety of forms of SGML.1 Once CGI was introduced, in fact, the Internet quickly saw the introduction of gateways to popular enterprise database systems such as Oracle, and a variety of other data types such as numeric data files (e.g., American National Election Studies).
A fundamental part of this strategy is the real-time creation of Web-friendly versions of material in formats not natively supported by Web browsers. Frequently, this strategy is taken as a matter of course: after all, relational databases and numeric data files are not "documents", and choices have always been made about real-time derivatives for display. In the world of documents, however, especially those encoded as SGML or as high-resolution page images, document managers have needed to choose between a strategy that pre-computes and stores derivatives for the WWW, or generating the Web-specific version on-the-fly for the end-user.
The choice between creating derivatives dynamically and storing static Web-accessible collections is, fundamentally, a management strategy. Neither strategy is intrinsically "good" or intrinsically "bad", though either can be adopted for ill-conceived reasons and implemented in shortsighted or wasteful ways. The choice between pre-computed derivatives and dynamically-derived documents is sometimes seen as a simple dichotomy. For example, in comp.text.sgml, one writer described the choice as a basic opposition of computing cycles and disk space: if computing cycles are more expensive than disk space, then we should conclude that creating and storing HTML derivatives of non-HTML sources is more cost effective because we can use cheap disk to reduce the CPU load caused by repetitive conversions. This reductionist view is frequently wrong, and more importantly it obscures the importance of administrative decisions involved in each choice.2
The DLPS currently offers dozens of collections, including more than 2,000,000 pages of SGML-encoded text and more than 2,000,000 pages of material using TIFF page images.3 All of the material in these collections is offered through the WWW, and nearly all of it is presented in Web-accessible formats through real-time transformations of the source material. Two primary considerations go into our decision to make the material available through dynamic rather than pre-computed and stored transformations. First, we assume that the patterns of use in our collections mirror those of traditional libraries, where many of the materials go unused for significant periods of time, and where many resources are used only once in an extended period of time. Consequently, creating derivatives for potential use will result in most derivatives being unused and both computational and human resources being wasted. Second, by maintaining the data in the richest possible format, we are able to use the same source in a variety of different ways as circumstances and tools allow. This allows for forward migration as the technologies for access and manipulation of information on the desktop mature.
2.1 Converting for actual use, not potential use
As digital libraries increase in size, they begin to exhibit many of the same patterns of use that the traditional library has seen: many resources are infrequently used. As materials are added to our currently relatively small digital libraries, increasingly smaller segments receive the sort of focused attention that we associate with actual use such as reading or printing. The extraordinary boon of the electronic format includes the ability to search across large bodies of material, "touching" many documents along the way. Still, relatively few of the documents will be read or printed.4
At the same time that we continue to build these massive collections of digital documents, HTML and online delivery mechanisms are changing frequently. When the Humanities Text Initiative (HTI), a DLPS unit that supports SGML collections, first mounted the Information Please Almanac, Web browsers did not yet support tabular presentation of data through the use of the TABLE element in HTML. The strategy employed for the Almanac was one that used HTML's <PRE> to force a fixed-pitch representation of the extensive tabular data. When Netscape began to support tables, the HTI staff made a small change to the transformation routines, thus enabling the display of the tabular data through Netscape's new functionality.
Each passing month sees the introduction of significant new functionality--recently frames, multiple fonts in a single document (and thus multilingual documents), Unicode support, and soon math. This trend should continue indefinitely, and we should expect to see a continually richer capability for presentation of information through the Web. Historical deficiencies such as a lack of tabular support, the inability to support superscript and subscript, or multilingual document support were remedied by interim measures such as inline, transparent GIFs, but history has shown that mechanisms will eventually be introduced to support all commonly used document layout features. By continuing to store only the richest version of these documents (rather than the derivatives), and by computing new versions only when needed, we are able to continue to tap the best features of the Web without either compromising the document or needing to manage a parallel collection.
For the DLPS, an approach that involved caching the majority of our data for prospective use--use that will not take place before we need to re-convert the material--would result in "wasted" computing cycles and wasted management effort. If we were to continue to convert and store versions of our document stores with each added capability in HTML, we would inevitably devote attention to detail for a variety of documents that would not be used during an "era" of HTML. Moreover, except for the strongest willed among us, automatic conversion from one format to another will almost always lead to some degree of dissatisfaction with the result. A project that generates static derivatives will be tempted to manually introduce "improvements" to the cached material. The simple argument that precomputed derivatives save computing cycles may actually prove false as collections grow in size, as smaller percentages of materials are used, and as we increase functionality.
2.1.1 Case 1: Grolier's Encyclopedia Americana.
It may be helpful to examine a case where DLPS scrutinized these decisions. Grolier's Encyclopedia Americana is one of the more heavily used reference collections provided to the University of Michigan user community by DLPS. The Encyclopedia Americana is provided to the DLPS in a very rich SGML, directly from the publisher's editorial process. The same SGML used to create the printed encyclopedia is used to build the online system. The Encyclopedia Americana is brought online by indexing the SGML and writing programs that allow users to navigate content and structure, for example by presenting the user with a hierarchical representation of the organization of an entry. These "versions" of the encyclopedia--both HTML articles and browsable intermediates--are generated for the user in real-time, creating HTML from the single, large online SGML collection. Users are provided a more easily navigated resource (i.e., one whose navigational information can be made to reflect an arbitrarily arrived at context), as well as one that makes the most of current HTML display capabilities (e.g., by introducing font-based support for non-Roman alphabets).
Transaction-level use data were analyzed for the period beginning in August 1996, and ending in early April 1997, for a total of eight months. Users conducted a total of 43,959 searches in the Encyclopedia Americana during this period (see Table 1). CGI transactions that retrieved articles were extracted to help determine the unique set of articles viewed by users (and thus, the articles that would have benefited by being converted to HTML).5 Despite being heavily searched, only 9.3% of the total number of available articles were viewed during the eight month period, and of these, 65% were used only once.
What can we conclude from these patterns of use? The Encyclopedia Americana is certainly heavily used, but despite this, only a small percentage of the articles in the encyclopedia are read or printed. Fewer still (35%) were displayed more than once. Investing significant resources in converting all 42,882 articles in the Encyclopedia Americana to HTML would result in the majority of these resources expended for no real purpose. Further, the likelihood that new features of HTML browsers would make it possible to improve navigation and display of results would mean that these same articles would need to be re-converted when the new features were available. At the same time, continuing to hone the capabilities of the real-time conversion capabilities means that the display of results can be improved with relatively little trouble.
2.1.2 Case 2: Making of America
The Making of America project will be treated at greater length in a forthcoming issue of D-Lib, but some brief comments on its deployment may be helpful in understanding another approach to just-in-time conversion. The Making of America (MOA) project is a collaborative collection building enterprise between Cornell University and the University of Michigan. The MOA collection at the University of Michigan consists of some 2,500 volumes of nineteenth-century publications (primarily monographs, but eight journals as well) published in the United States between 1850 and 1877, and focusing on American social history from the antebellum period through reconstruction. The materials are stored in TEI-conformant SGML that points to 600dpi TIFF images of pages. Materials are prepared for conversion at the University of Michigan, and are scanned as TIFF images by a service bureau. Significant local processing takes place to create OCR and the encoded text over which searches are conducted.
Few of the volumes in the online collection are corrected, fully-encoded SGML. The rough OCR that sits behind the scenes provides an effective mechanism for users to navigate the vast quantities of material (650,000 pages), but users are presented only with brief navigational information in HTML. The book itself is viewed on screen or is printed by using the images of the pages. The 600dpi images are an excellent source for creating printed volumes, and because of the relatively high resolution, a number of different resolutions can be easily derived. Using tif2gif, a program developed by Doug Orr for University of Michigan Digital Library projects, GIF images suitable for several different display resolutions (reflecting the user's preference) are created in real time. The same single source can thus be used to create printed editions, and to serve a variety of different user needs. The choice to do this in real time, rather than pre-computing and storing these derivatives, does not adversely affect performance for users (i.e., it happens quickly enough that users are unaware that the version is being created), and helps us avoid the need to convert, store, and manage pages that are seldom or never used.
Data similar to those collected for the Encyclopedia Americana are not yet available for the Making of America project. However, because the printed materials were held in the Library's storage facility and were used only infrequently (e.g., once every twenty years), we assume that they will be used less frequently than the online reference sources. Historical resources such as these will probably exhibit overall less use and less repeated use. Regardless which type of collection, however, large numbers of books or articles go unused, except to report to the user of the full-text search that they do not contain results, or to present a "pick list" choice for a user that is subsequently unused.
2.2 "Re-purposing" and managing data
Maintaining the data in its original structured or high-resolution format rather than HTML or derived images allows DLPS to re-purpose the data in a variety of flexible ways. Texts, and especially portions of texts, are more easily re-purposed. Portions can be displayed for different uses. For example, section heads can be drawn from documents to create context-aware tables of contents. Moreover, the awareness (by the system) of the arrangement of documents--of parts to the whole--provides a powerful tool for collection management.
2.2.1 Flexible delivery
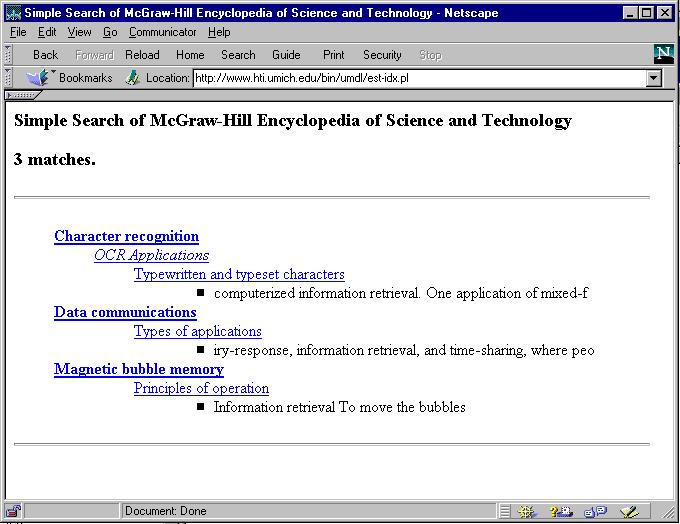
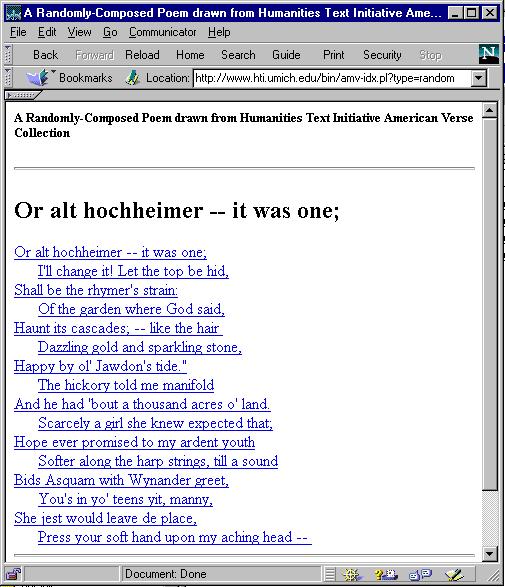
When the system "knows" about the structure of the document, different portions can be delivered to the user for different needs and in different contexts. A volume/issue browse can be generated from the same set of data as a search resulting in links from authors and titles. A system that provides relevance at the level of the subdivision can show the relationship, dynamically derived, of the part to the whole (see Figure 1). A small document subset, such as quotations in the OED, can be delivered as ends in themselves (see Figure 2) instead of links to dictionary entries that frequently exceed ten printed pages. Synthetic documents, assembled by pulling together parts from many different wholes, can be created for both real and whimsical purposes (see the poem in Figure 3, where each line was automatically extracted from a collection of several thousand poems in real time; cf. http://www.hti.umich.edu/bin/amv-idx.pl?type=random)
2.2.2 Collection management
For large document stores--especially large collections of large documents--a cached HTML approach results in version control issues of tremendous proportions. Consider, for example, the HTI's American Verse Project collection, where the current collection of seventy-four volumes is divided into 2,308 major sections (most of these too large for web-based delivery), 2,222 secondary sections, 629 tertiary sections, and so forth. A pure HTML approach will result in approximately 5,000 separately named objects for this relatively small collection and more than 40,000 objects by the time the project is complete. The need for frequent revision of the objects, if not accomplished through entirely automatic mechanisms, will present problems of collection management not present when the parts of the whole are represented through markup.
While different project imperatives should necessarily lead to different approaches, the relatively large collections of richly represented documents in the University of Michigan Digital Library has led to an approach that favors "just-in-time" rather than "just-in-case" conversion. Real-time transformation of high-resolution page images and richly encoded documents has proven possible without noticeably diminishing performance for end-users. This strategy has allowed us to store materials in forms that pre-date the web and continue to exceed the Web's capabilities for display, and yet to make them available in Web-capable formats, in increasingly attractive or informative ways. The WWW will continue to change with remarkable speed, and choosing to store these large collections in their richest form while dynamically converting to today's HTML makes it possible for us to continue to keep these rich libraries alive while avoiding the creation and maintenance of a series of interim collections.
The speed and direction of the Web's improvements makes it seem likely that this dichotomy of dynamic and static conversion will become increasingly moot. At the same time that we see continuing enhancements being made to HTML, we are also witnessing an increased interest in native support for richer formats. The recent creation of XML, sponsored by the W3C, may make it possible to send natively encoded SGML documents to Web browsers. For our page image systems, the native TIFF compression scheme by Cartesian Inc., CPC, should begin to make it possible to send the TIFFs themselves, rather than derivatives. At the same time, by continuing to rely on the richer encoding, especially of SGML documents, we are better able to support navigation and the display of partial documents as needed.
The strategy of "just-in-time conversion" paired with "just-in-case storage" goes to the heart of digital libraries. We cannot reliably predict which materials will be used or relevant for research. Effective digital libraries will be those that make their resources available in ways that do not influence research by using predictive methods that penalize the user who steps outside the mainstream. Relying on dynamic transformation methods for large digital collections positions the digital library in ways that allow us to take advantage of future capabilities without losing access to historical collections.
Table 1: Encyclopedia Americana use from August 1996 to March 1997
| Aug-Dec ‘96 | Jan-Mar ‘97 | Total | Percent of total articles | |
| Total EA transactions: | 24,073 | 19,886 | 43,959[6] | |
| Total article retrievals: | 2,767 | 1,237 | 4,004 | 9.3% |
| Total unique retrievals: | 1,962 | 870 | 2,625[7] | 6.1% |
| Total articles in EA: | 42,882 |
Table 2: Representative DLPS collections
| Collection | Type/Domain | Format |
| Encyclopedia of Science and Technology; | Document retrieval, sciences | SGML using unique DTDs from different publishers |
| Encyclopedia Americana; | Document retrieval, general reference | SGML using unique DTDs from different publishers |
| Bryn Mawr Classical
Review; Bryn Mawr Medieval Review |
Document retrieval, humanities | journal articles, using TEI encoding |
| American Verse Project; | Document retrieval and analysis, humanities | SGML locally-encoded using TEI |
| Elsevier Science journals | Document retrieval, sciences etc. | rough OCR behind scenes (no encoding--simple use of file system for management); 300 dpi bitonal TIFF page images for viewing |
| Making of America | Document retrieval and document analysis, humanities | loosely-encoded TEI of OCR behind scenes, 600 dpi bitonal TIFF page images for viewing |
Notes
[1] Price-Wilkin, John. "A Gateway between the World Wide Web and PAT: Exploiting SGML Through the Web." The Public-Access Computer Systems Review 5, no. 7 (1994): 5-27.
[2] As one might assume from this position, not all DLPS collections rely on real-time derivation of Web-friendly sources. In our high resolution imaging projects in support of papyrology and manuscript study, we store a variety of reduced resolution versions for different types of applications. Of course this practice may change with available tools. A brief synopsis of some of the more notable DLPS projects and their formats is appended in Table 2.
[3] A fuller discussion of two DLPS initiatives and their collections will appear in a forthcoming issue of D-Lib. For a brief discussion of some DLPS collections, see also "Just-in-time Publishing; Just-in-case Libraries: Cooperation at the University of Michigan." Presented at Rice University, April 10, 1997. Available on the WWW.
[4] We might hope or expect that more and different documents will be read or printed by virtue of the increased level of access available in full-text search. The digital library should indeed affect the way that we conduct research and the results that come out of that research, but researchers will not necessarily use significantly larger amounts of material.
[5] Because not all article retrievals take place in the same way through the CGI mechanisms, this process excluded 361 "cross-reference" article retrieval transactions in the '96 (11% of all article retrievals in the period) and 199 "cross-reference" article retrieval transactions in '97 (14% of all article retrievals in the period).
[6] The difference between total transactions and article retrievals is accounted for by a higher number of searches than actual article use, and by browse transactions for parts of the articles represented in article retrievals.
[7] This figure is not a sum of the figures to the left. Instead, duplication across the entire period was taken into account.



hdl:cnri.dlib/may97-pricewilkin
{kind=link}
{kind=link}
{kind=link}