
The Dublin Core Workshop Series is an ongoing effort to form an international consensus on the semantics of a simple description record for networked resources. It is expected that a simple and widely-understood set of elements will promote interoperability amongst heterogeneous metadata systems and improve resource discovery on the Internet.
The present report describes the results of the fourth workshop in this series (DC-4), held at the National Library of Australia in March, 1997. The 65 workshop participants included digital library researchers, Internet networking specialists, content specialists, and librarians from 12 countries on 4 continents.
The Dublin Core Metadata Element Set emerged as the primary deliverable of the first workshop in this series (The OCLC/NCSA Metadata Workshop). The scope of this first workshop was limited to identifying the semantics of a core set of descriptors that might improve discovery for Web resources that could be thought of as Document-Like-Objects.
Subsequent workshops have gradually extended the scope of the Dublin Core effort. The second workshop, co-sponsored by the UK Office of Libraries and Networking (UKOLN) and OCLC, resulted in the Warwick Framework, a conceptual model for a container architecture for metadata packages of various types. The organizing principle that emerged from this workshop was that there will be many packages of metadata, independently developed and maintained for different purposes by various communities, and that this modularization will allow for coherent evolution of different components of the metadata landscape under a single metadata architecture.
The CNI/OCLC Image Metadata Workshop focused on the use of the Dublin Core (DC)to describe images. Consensus formed around the assertion that, with some modifications of element names and definition, the Dublin Core would serve quite adequately for description of a large class of image resources, particularly those that share characteristics with the document-like objects that were the original focus of DC.
Extensive mailing list discussions following the third workshop resulted in additions and modifications to the original 13-element set. The result was a 15-element Dublin Core with slightly modified element names. The consolidation of this set can be thought of as marking the end of the element set development phase of the Dublin Core and the beginning of a deployment phase. While details of some of the elements remain to be elucidated, there is sufficient agreement to move forward. The many issues raised by the task of actually deploying Dublin Core helped to define the agenda for the Canberra meeting.
Each of the Dublin Core workshops to date has taken on a particular character reflecting some central emergent concern of the group. The results of DC-4 are best understood as the manifestation of the tension between two pragmatic camps: the Minimalists and the Structuralists.
It is an oversimplification to suggest that these two groups are distinct and mutually exclusive; in fact, they are two poles of a continuum, and conferees were distributed throughout this continuum.
The Minimalist point of view reflects a strong commitment to the notion that DC's primary motivating characteristic is its simplicity. This simplicity is important both for creation of metadata (for example, by authors unschooled in the cataloging arts) and for the use of metadata by tools (for example, indexing harvesters, which will probably not make use of detailed qualifiers or encoding schemes). The goal of semantic interoperability across communities can only be achieved if there is a simple core of elements that are understood to mean the same thing in every case. Additional qualifiers support specifying, modifying, and particularizing the meaning of an element. Since this will probably be done in different ways by different groups at different times, it will potentially lead to semantic drift in the elements, and consequent loss of semantic interoperability.
The Structuralists as a group accept the danger of this semantic drift in exchange for the greater flexibility of a formal means of extending or qualifying elements such that they can be made more useful for the needs of a particular community.
Resolution of the tension between the Minimalist and Structuralist positions will result only from experience in the real world of resource discovery. The real world is a messy place with conflicting constraints. It may be helpful, however, to understand these positions as points on a coherent continuum:
Unstructured, inverted-file indexing of full-text resources; this is the approach of most of the various harvesters such as AltaVista and the like.
Unfielded SurrogatesAn undifferentiated collection of terms assigned to a resource as metadata, either by authors, software agents, or human indexers. No substructure tagging (so, one might be able to retrieve resources containing the string "Tim Berners-Lee", for example, but would not be able to distinguish resources about him from resources created by him).
Minimally Fielded SurrogatesA limited number of fields with known semantics (Creator, Subject, Title, for example). Identified element names (roles) support fielded searching. This requires specified fields in a formally managed name space (element set). This is the point on the continuum closest to the Minimalist camp in the Dublin Core community.
Qualified SurrogatesBasic field names have additional attributes that support refinement and qualification of the element names or their content. This is the point on the continuum closest to the Structuralist camp in the Dublin Core community.
Richly-Structured SurrogatesRichly-elaborated structured data; a MARC record, for example, or a fully developed Text-Encoding Initiative (TEI) record.
Each of these points on the resource description continuum represents compromises among cost, ease of creation and maintenance, and utility. At one end there is the virtue of simplicity: harvesting is done with no concern for the domain, the structure, or the purpose. The scale of the collection and delivery of the information is challenging, but the description model is simplistic: word-level indexing. Search result sets are generally very large; high recall, but typically very low precision. Even with such coarse-grained retrieval, the results can be useful.
At the other extreme of the continuum, records are more costly to construct and maintain, but hold the promise of higher precision, and greater organizational coherence. The interpretation and use of such records, either by humans or software agents, is also more complex and requires more sophistication (training of humans, rich knowledge representation schemas in software).
The intended domain of Dublin Core description is between these extremes, aimed at intermediate precision and high interoperability in a record that should be relatively inexpensive to create and maintain. The Dublin Core element set, having evolved as a consensus among many stakeholders, should be an adequate foundation for this middle ground, whether one takes a purely Minimalist approach or chooses a somewhat more elaborate strategy of the Structuralists.
Above all, it is the value of the elements that should be the primary focus. Applying the continuum argument delineated above, this implies that one might well be able to drop away all qualifiers (including, perhaps, the element names themselves) and still have a surrogate for the resource that is useful for retrieval.
The underlying assumption of those who would deploy qualifiers is that the added structure and richness that they can provide can be used to good effect to enhance discovery. Every decision to deploy qualifiers should be measured against the question "Will this qualifier improve discovery?"
The metadata community should take to heart the physician's admonition: above all, do no harm! In this case, doing no harm means keeping systems as simple and easily manageable as can be accomplished while supporting the discovery tools appropriate to a given domain. Qualifiers should be kept to a minimum.
Figure 1 illustrates the metadata model currently embraced in the Dublin Core effort. It involves a metadata package (perhaps one of many) comprised of some number of metadata elements. Each element has subcomponents (either explicit or implied).
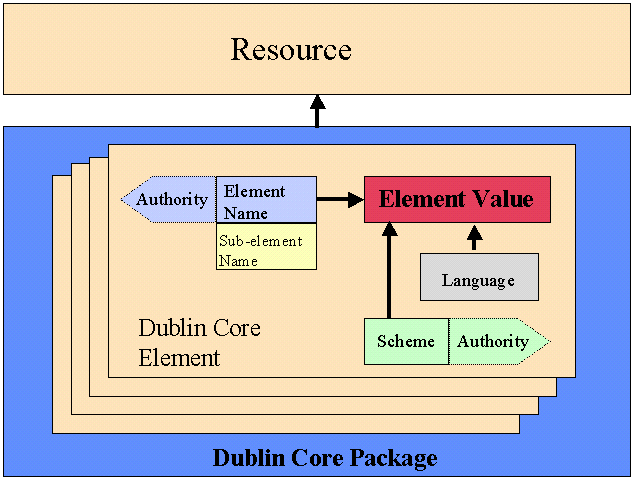
The data of central interest is the Element Value itself. Indeed, an index of the undifferentiated collection of these values would probably serve for many resource discovery purposes.
There are several ways by which such data can be qualified to make it more useful. The most obvious is to identify the role of the descriptive content. That is, the element name of the field in which a particular descriptor best fits. Thus, Weibel, Iannella, and Cathro have the role CREATOR in the metadata of this report. The Dublin Core has 15 such roles or Element Names as its basic fields. (See the reference page at http://purl.org/metadata/dublin_core_elements).
The DC-4 Workshop formalized additional qualifiers (the Canberra Qualifiers) that had been discussed at other workshops and on the mailing list, but had never been elaborated formally.
This qualifier specifies the language of the element value of the descriptor field (not the resource itself). This is increasingly important as issues of multilinguality come to the fore on the Web. English has been the presumptive language of the Web to date, but as this changes, it is important to be able to identify both the language of the resource and the language of the resource description.
This qualifier specifies a context for the interpretation of a given element. Typically this will be a reference to an externally-defined scheme or accepted standard. For example, a SUBJECT field might be SCHEME-qualified as LCSH data (Library of Congress Subject Heading).
One way to think of a SCHEME qualifier is that it provides a processing hint that may be used by an application or a person to make better use of the element that is qualified. Thus, in the previous example, one could ignore the SCHEME = LCSH and still have a useful subject descriptor.
There are other cases in which the SCHEME identifier would be critical to the use of the field, however. For example, consider the case where the SCHEME is DDC and the content of the SUBJECT field is a Dewey Decimal System number: such a descriptor is useless outside of the context of the DDC hierarchy.
Similarly, a SCHEME identifier might be critical to the interpretation of a date. Unambiguous parsing of a date requires knowledge of the encoding standard (SCHEME) used in the expression of the content (does the string 1997-10-07 specify the tenth day of July or the seventh day of October?).
Finally, SCHEME is particularly important to certain specific communities that have well defined ontologies or thesauri that are widely deployed for resource description. It is hard to imagine effective resource description in the realm of medicine, for example, without MESH (MEdical Subject Headings).
The TYPE attribute is the most controversial of the Dublin Core qualifiers. There is some logical difficulty in defining exactly what the acceptable types are and how they should be defined. In a sense, it is not a qualifier at all, but rather an hierarchical subdivision of the element name itself.
Indeed, the dot-encoding convention that was agreed upon in Canberra reflects this. For example, a facet of a particular element could be expressed thusly:
DC.creator.personalName = "John Smith"
This construct indicates that the string enclosed by quotes represents the creator of a given resource, and further, that the string in question represents a person's name (as opposed to a corporate name, for example). This example satisfies the criterion of a sub-element narrowing the semantics of the element which it modifies; a Personal Name is just one variety of a name. It might be useful to use it, but it does not violate the integrity of the CREATOR field to ignore it.
The unresolved problem with the application of sub-element names is how to identify the authority for the sub-element name. The existing convention for associating an element name with an authority (see the HTML-META convention in the succeeding section) does not specifically support hierarchical names. This will work fine if one assumes that the authority for the element name and the sub-element name are identical (the workshop agreed that a registry of sub-element names for Dublin Core elements is desirable). However, there will be many cases where one metadata authority will want to adopt the broad categories of another, but add their own sub-elements. Currently there is no recognized way to do this unambiguously.
Developments underway in Web Metadata Architecture (see subsequent discussion) will address this shortcoming. For the time being, HTML implementations attempting to deploy metadata built on complex metadata models will have to rely on informal conventions among early adopters to support the rich features they are developing in their metadata systems.
Note that Figure 1 includes an authority attribute associated with the Element Name and Scheme qualifiers. This is intended to demonstrate that these qualifiers may be part of a controlled name space, and that the naming authority for that name space may be optionally specified. In an online environment, this would be accomplished via a hyperlink. For example, DC.TITLE is an element name that is part of the Dublin Core metadata element set. Dublin Core is the naming authority, and is managed by some group with the responsibility to say what is in that name space. LCSH is the name of a SCHEME, which is also a controlled name space, the authority for which is the Library of Congress.
There may or may not be a machine-parseable link to the authority. However, the SCHEME identifier LCSH may well be useful even if there is no such link, because the identifier has public currency and credibility. An application may well take advantage of that currency without a link. Thus, links may be implicit or explicit. In either case, there is no assurance that a given application can make use of such a link. Such a mechanism can be exploited to the extent that a community adopts a particular convention or scheme and deploys it, and to the extent which applications are deployed to capitalize on such conventions.
It is important to maintain separation between the data content standard and its syntactic expression, but it is also useful to examine how the metadata model described above might be expressed in HTML because of the strategic importance of early deployment of network resource description on the Web. This has been from the start an exercise in the fine art of technological finesse.
The May 1996 W3C Workshop on Distributed Indexing and Searching resulted in a convention for the deployment of simple, unqualified metadata. This convention specifies a simple way of expressing metadata (while providing links to the reference implementation of the metadata schema) that stays within the HTML 2.0 specification (A proposed consensus for embedding metadata in HTML). Several prototyping efforts have applied this convention and extended it to support metadata with qualifiers.
The addition of qualifiers complicates the syntactical issues. There are two approaches to the specification of Canberra Qualifiers in existing HTML (HTML 2.0), each with particular advantages and disadvantages.
The first method, the Overloaded Content approach, stays within the HTML 2.0 syntax by embedding SCHEME and LANGUAGE information in the CONTENT attribute of the META tag as illustrated in the following example:
<META NAME = "DC.subject" CONTENT = "(SCHEME=LCSH) (LANG=EN) Computer Cataloging of Network Resources">
This approach has the significant disadvantage of cluttering the CONTENT field with qualifier information. Since the goal of embedded metadata is in part to make the metadata more readily visible to harvesters, the obfuscation of the CONTENT attribute is sub-optimal to say the least. A smart harvester might parse the CONTENT attribute intelligently and use (or ignore) the SCHEME and LANG identifiers sensibly, but it is unreasonable to expect this to be the norm.
The second method, the Additional Attribute approach, involves a cleaner representation of the data through the use of unofficial additional attributes (SCHEME and LANG) in the META tag as illustrated below:
<META NAME = "DC.subject" SCHEME = "LCSH" LANG = "EN" CONTENT = "Computer Cataloging of Network Resources">
The additional attributes should be ignored by most Web software agents, causing no particular harm, but some parsers will not validate HTML of this kind (an important consideration as formal document repositories evolve) and the behavior of editing software is undefined and potentially problematic.
Early deployment of qualified Dublin Core metadata requires choosing between these advantages and disadvantages. There are developments in the world of Web architecture that should eliminate these problems. At this writing, the details of the metadata architecture for the Web are still indistinct, but it is possible to portray with broad brush strokes some of the solutions on the horizon.
There is an increasing recognition of the need for a metadata architecture for the Web. The goal of such an architecture is to support the encoding and transport of many independently developed varieties of metadata in a manner that maximizes system interoperability. There are currently several initiatives underway under the auspices of the W3C that are addressing these issues. Current discussions among these working groups can be expected to converge toward a single architecture that will include the ability to accommodate Dublin Core style metadata. A brief description of these initiatives follows.
Cougar is the code name for W3C work on the next version of HTML. Cougar builds upon previous work on W3C's Recommendation for HTML 3.2. Among the extensions currently under discussion are (1) rich forms and interactive documents, (2) the ability for pages to be changed dynamically via scripting, frames and subsidiary windows, (3) improved access to HTML features for people with disabilities, (4) the addition of multimedia object capabilities, and (5) internationalization of HTML. Additional discussion is focusing on the need for enhancing the META element to allow for additional descriptive information to be embedded in the HTML resource.
The Extensible Markup Language (XML) is a data format for structured document interchange on the Web. XML is intended to be a standard "to make it easy and straightforward to use SGML on the Web: easy to define document types, easy to author and manage SGML-defined documents, and easy to transmit and share them across the Web." The goal of this working group is to enable generic SGML to be served, received, and processed on the Web in the way that is now possible with HTML. The extensible character of XML will also make the encoding of metadata easier and more flexible.
Web Collections is an application of XML that is used to describe the properties of some object. Web Collections uses XML to provide a hierarchical structure for these data. Each collection specifies a profile that allows applications to expect specific properties in that collection. For example, a collection describing a Web page might specify the "WebPage" profile which would allow a program to know that this collection describes a web page and has properties such as, for example, author and date-last-modified.
WEBDAV (Web Distributed Authoring and Version control) specifies a set of methods and content-types ancillary to HTTP/1.1 for the management of resource metadata, simple name space manipulation, simple resource locking (collision avoidance) and resource version control.
PICS (Platform for Internet Content Selection) is an infrastructure for associating labels (metadata) with Internet resources. The initial goal of this infrastructure, content filtering, is being expanded to address broader issues of generalized resource description, including organizational management, discovery and retrieval, intellectual property rights, and privacy protection tasks. This W3C working group will define a new format for labels in order to better address these issues. The new format will permit non-numeric values (eg., string values), structured values and element repeatability.
Several ad hoc working groups formed around unresolved issues that arose in the course of the workshop. Some of these activities have led to working papers describing the ongoing work of these groups. While the conclusions of these groups have not necessarily been widely vetted, they represent an important aspect of the evolutionary development of the Dublin Core.
The COVERAGE element has had strong proponents from the very first workshop. Advocates argue that this element is a potentially indispensable tool for improving discovery for many types of data (especially geo-spatial data). The difficulty with this element is that providing guidelines for application is domain-dependent and potentially complex.
The Coverage Element Working Group has brought forth a position paper (http://alexandria.sdc.ucsb.edu/public-documents/metadata/dc_coverage.html) suggesting how this element might be deployed in the context of the hierarchical dot notation described in an earlier section of this paper.
As mentioned earlier, issues of multilinguality are assuming greater importance as the Web becomes more international in scope and expression. The mix of technical, cultural, and political factors that come into play in any solution to multilinguality problems are daunting at best. A working group formed around the multilinguality aspects of the metadata problem, and a position paper (http://www.cs.ait.ac.th/~tbaker/Cores.html) is available describing the some of the problems and possible approaches to solving these problems.
Name space management is prominent among the thorny impediments of deploying a world-wide metadata architecture. Who controls a given metadata name space (such as the Dublin Core, for example)? How can such a name space be partitioned such that it can be easily extended by others without re-inventing a particular wheel? What conventions are necessary to make a naming authority globally visible and accessible, and what sort of structured or unstructured data should be available online for humans or applications to process?
Many of these questions arose during the Canberra Workshop, along with the recognition that resolving them will require coordination beyond the Dublin Core group. A subgroup of the workshop began the large task of defining more clearly the `approved' list of sub-element names. The draft position paper on this work, still in progress, is accessible at http://www.loc.gov/marc/dcqualif.html .
Several of the DC-4 conferees will participate in a workshop that addresses just this topic, the Joint Workshop on Metadata Registries (http://www.lbl.gov/~olken/EPA/Workshop/index.html), sponsored by the U.S. Environmental Protection Agency and organized by staff at the Lawrence Berkeley Laboratory for July of 1997.
The broad agreements about syntax and semantics that emerged from the workshop discussions and subsequent exchanges on the META2 mailing list will be expressed in a series of four documents currently under development. These documents will be formalized as IETF Requests for Comment (RFCs) in an effort to seed the standardization process for Dublin Core metadata. These RFCs will comprise the following documents:
The Canberra Workshop resulted in progress on the metadata model that underlies the Dublin Core and clarified the qualifiers necessary to implement this model. Further, conferees emerged with a logical outline of the implementation details that need to be clarified to support wider deployment; these details will be the subjects of the RFCs outlined in the preceding section.
It has become clear in the intervening months that some of these details will be difficult to resolve, requiring consensus not only among those directly involved with the Dublin Core effort, but also many other groups involved in Web standards and other metadata initiatives.
Nonetheless, the continued, incremental progress towards a common goal encourages further effort, and planning for a 5th workshop is underway. DC-5 is tentatively planned for October 6-8 in Helsinki, Finland. The focus of this meeting will be to promote convergence among the early implementers, and to reconcile issues of syntax with the rapidly emerging metadata infrastructure of the Web.
DC-4: The Canberra Workshop
http://purl.org/dstc/dc4
DC-3: CNI/OCLC Image Metadata Workshop
http://purl.oclc.org/metadata/image
DC-2: OCLC/UKOLN Metadata Workshop
http://purl.oclc.org/oclc/rsch/metadataII
DC-1: OCLC/NCSA Metadata Workshop
http://purl.oclc.org/oclc/rsch/metadataI
The Warwick Metadata Workshop: A Framework for the Deployment of
Resource Description.
Lorcan Dempsey and Stuart Weibel,
http://www.dlib.org/dlib/july96/07weibel.html
A proposed consensus for embedding metadata in HTML
from the W3C Distributed Indexing Workshop, May 28-29, 1996.
http://www.oclc.org:5046/~weibel/html-meta.html
OCLC/NCSA Metadata Workshop Report
Stuart Weibel, Jean Godby, Eric Miller, and Ron Daniel (June, 1995).
http://purl.oclc.org/metadata/dublin_core_report
Metadata: The Foundations of Resource Description
Stuart Weibel
http://www.cnri.reston.va.us/home/dlib/July95/07weibel.html
The World Wide Web Consortium
http://w3c.org
The organizers gratefully acknowledge the support of their home institutions, The National Library of Australia (NLA), The Distributed Systems Technology Centre (DSTC), and The OCLC Online Computer Library Center Office of Research, for sponsoring this meeting and supporting its organization.
Additional travel support from the National Science Foundation and OCLC, and the Committee on Electronic Information of the Joint Information Systems Committee of the Higher Education Funding Councils made possible the attendance of many who would otherwise have not been able to contribute their expertise to this workshop.
This Workshop is part of an ongoing series that has benefited from the sponsorship and participation of numerous other organizations, including the National Center for Supercomputing Applications (NCSA), The United Kingdom Office for Library and Information Networking (UKOLN), and the Coalition for Networked Information (CNI).
The essence of this series of workshops is the building of a multidisciplinary consensus on the nature of network resource discovery. Whatever success is achieved in this process is due to the commitment and collective wisdom of the participants. The support of the following individuals as workshop steering committee members is exemplary of this contribution.
| Tom Baker Asian Institute of Technology |
Lorcan Dempsey UKOLN |
Ricky Erway Research Library Group |
| Juha Hakala University of Helsinki Library |
John Kunze University of California, San Francisco |
Carl Lagoze Cornell University |
| Clifford Lynch University of California |
Andreas Paepke Stanford University |
Frank Roos CWI, The Netherlands |
| Diann Rusch-Feja Max Planck Institute for Human Development and Education |
Andrew Wells National Library of Australia |
Bemal Rajapatirana National Library of Australia |
The following is a list of projects deploying Dublin Core Metadata. It is by no means exhaustive, but provides examples of deployment approaches and illustrates some of the issues that must be addressed for early deployment.
| ADAM: Art, Design, Architecture & Media Information Gateway | http://adam.ac.uk/ |
| Arts and Humanities Data Service | http://ahds.ac.uk/ |
| The Berkeley Digital Library SunSite Librarian's Index to the Internet |
http://sunsite.berkeley.edu/InternetIndex/ |
| The Desire Project | http://www.nic.surfnet.nl/surfnet/projects/desire/ |
| The Distributed Systems Technology Centre (DSTC) Metadata Activities | http://www.dstc.edu.au/RDU/ |
| EdNA (Education Network Australia) | http://www.edna.edu.au/edna/owa/info.getpage?sp=auto&pagecode=5210 |
| A Mathematics Preprint Index | http://www.dstc.edu.au/DC4/roland/ |
| Metadata Server of the SUB Göettingen | http://www2.sub.uni-goettingen.de |
| MMM-interface for Creation of DC-Metadata Files | http://www.mathematik.uni-osnabrueck.de/projects/META/ |
| Monticello Project | http://www.solinet.net/monticello/monticel.htm |
| NewsAgent for Libraries | http://www.ukoln.ac.uk/metadata/NewsAgent/ |
| Nordic Metadata Project | http://linnea.helsinki.fi/meta/ |
| Nordic Web Index | http://nwi.ub2.lu.se/ and http://nwi.dtv.dk/nwi_info.html#metadata |
| The ROADS Project: Resource Organisation and Discovery in Subject-based Services | http://ukoln.bath.ac.uk/roads/ |
The sentence: " The second method, the Additional Attribute approach, involves a cleaner representation of the data through the use of an official additional attributes (SCHEME and LANG) in the META tag as illustrated below:" has been changed to read " The second method, the Additional Attribute approach, involves a cleaner representation of the data through the use of unofficial additional attributes (SCHEME and LANG) in the META tag as illustrated below:" at the request of the Author. Editor, June 27, 1997



hdl:cnri.dlib/june97-weibel