
Abstract
This paper describes our study on the text data description rules for Japanese classical literature. We investigated the various functions for the text data description by analyzing Japanese classical materials. As the result, we have defined and developed the rules with three functions, calling these KOKIN Rules. Many Japanese classical texts have been electronically transcribed using these rules. We have evaluated their availability especially for their application to databases, CD-ROMs, and publishing. Recently, as SGML has become a popular markup language, we have conducted a study of conversion to SGML compliant text. A full-text database system has been produced based on the string search system conforming to SGML.
The National Institute of Japanese Literature (NIJL)
is one of the inter-university research institutes of Japan founded
in 1972. The purpose of its establishment is to survey the printed
and handwritten Japanese classical materials from the Edo period
(1603-1863) and before, and to collect their original and/or microfilm
reproductions in order to preserve these and also to provide public
access. Over more than two decades of activity, the NIJL has become
the center of archival activity. The Research Information Department
has been engaged in design, production, management, and maintenance
of an information system of classical Japanese materials for academic
researchers both in Japan and foreign countries. At present, we
provide three catalogue databases: the Catalogue of Holding Microfilms
of Manuscripts and Printed Books on Japanese Classical Literature,
the Catalogue of Holding Manuscripts and Printed Books on Japanese
Classical Literature, and the Bibliography of Research Papers
on Japanese Classical Literature. Other catalog databases (The
Union Catalogue of Japanese Classical Materials, The Catalogue
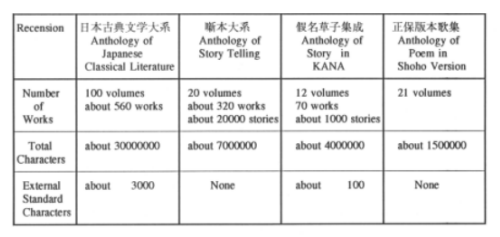
of Historical Materials), full-text databases (Table 1), and image
databases (Image Database for the Study of Japanese Literature)
are under preparation.
The NIJL's information system is composed of a mainframe
computer and a network system. All data processing for data compiling
and correction, database services, and publishing are executed
on the mainframe computer system. The idea of an integrated text
processing seems a matter of course today. Considering that the
basis of the system was designed more than fifteen years ago,
it can be considered a fairly ambitious system. However, over
its fifteen-years' existence, the information system has encountered
many problems requiring solutions in both software and hardware.
To solve these problems, NIJL has initiated a new project for
the digital library of Japanese classical literature. This project
will gradually replace the mainframe computer system with a so-called
distributed computer system over several years. The key words
for the project are "standardization of data," "system-independent
data" and "multimedia-oriented."
This paper will present our new project from the
perspectives of data description and its application of a full-text
database. In the following discussion, section two describes our
markup rules (KOKIN Rules ). Our case study on conversion of KOKIN
text to SGML text is described in section three. Finally, some
problems to markup Japanese classical texts are summarized.
At the time we began constructing full-text databases, Standard Generalized Markup Language (SGML) was not popular in Japan. Unfortunately, there were no SGML applications that could process Japanese language. Therefore, we created our own text markup rules that resembled SGML in its basic idea [Yasunaga 1992]. These rules were designed for ease of understanding and for use by researchers of Japanese classical literature. We call the rules "KOKIN Rules" ("KOKubungaku", meaning Japanese literature, Information; "KOKIN" is also a title of a famous Japanese classical poem anthology). KOKIN Rules are composed of three sub-rules: Tag Rule, Flag Rule, and Value Added Rule.
This section describes KOKIN Rules. "The Anthology of Story Telling" is used for an example. This anthology is a collection of short stories of citizens in Edo, the former name of Tokyo. The original material contains complex structures, such as annotations, editorial corrections, phonetic representations and so on. The text was transcribed by two of our co-researchers at NIJL [Mutoh and Oka 1976], then marked up in electronic form by us using KOKIN rule. Figure 1 shows the example of the original text, and Figure 2 shows the example of its transcribed book.


Figure 2. Recension text of The Anthology of Story Telling
2.1 Tag Rule
Texts contains various kinds of "logical elements" (i.e., titles, chapters, etc.). "Tag" is an identifier that marks up logical elements of text; a "markup" reflects the way a researcher sees and analyzes text. We decided that the definition of text structure and the identification of logical elements should be done by researchers themselves. However, to formalize the tag-setting for data circulation, we introduced Tag Rule as a guideline to define basic logical structure of text. Below, we show the syntax of Tag Rule:
| <Logical Record> | ::= <Tag Begin><Tag><Tag End> | <Tag Begin><Tag><Data><Tag End> |
| <Tag Begin> | ::= 'Japanese-Yen-Mark' |
| <Tag End> | ::= 'Star-Mark" |
| <Tag> | ::= <Tag Symbol> | <Tag Symbol><Tag Attribute> |
| <Data> | ::= <Line>|<Original Data>|<Repeating Symbol><Original Data> |
| <Line> | ::= <Original Data> | <Number><Original Data> |
| <Repeating Symbol> | ::= ';' |
| <Original Data> | ::= see 2.2 |
| <Tag Symbol> | ::= see Table 2 |
| <Tag Attribute> | ::= see Table 2 |
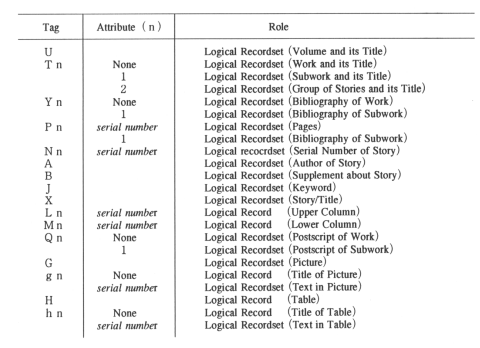
Table 2. Tag Symbols and Attributes of the Flag Rule (a part)
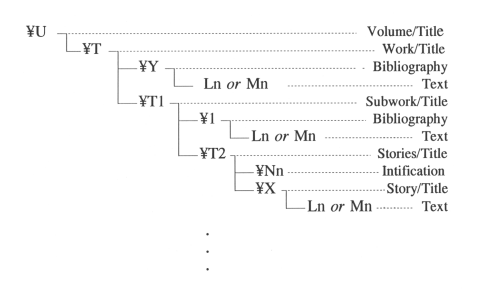
Tag Rule is analogous to SGML elements. The basic syntax of the Tag Rule is "Japanese Yen mark" followed by alphabetic characters (i.e., 'T' for title, 'P' for page, and 'G' for insert position of an illustration). Figure 3 shows our view of "The Anthology of Story Telling" and Appendix 1 shows an example of its markup data. Here, we define a physical line as the basic text structure and call it a "logical record." Then, we define a series of logical records as "logical record set." A series of several lines that determine a region of a story is an example of the logical record called "Story." Thus, KOKIN rules can describe a hierarchical structure of text.
2.2 Flag Rule
The layout of Japanese classical texts is designed
in two dimensions; that is, the texts are constructed from main
sentences and supplementary sentences (i.e., annotation, side
notes, etc.), which are parallel to the corresponding main sentences.
The Flag Rule was introduced to indicate the starting and ending
position of the supplementary sentences. In other words, the Flag
Rule is used to convert two dimensional layout to one dimensional
string by embedding supplementary sentences into the corresponding
main sentences. We show the syntax of the Flag Rules below:
| <Original Data> | ::=<Flag Begin><Data
Element><Flag End><Supplement>
|<Data Element><Space Flag><Supplement><Data Element> |<Data Element> |
| <Data Element> | ::= <String> |
| <Flag Begin> | ::= '/' |
| <Flag End> | ::= '/' |
| <Space Flag> | ::='/' |
| <Supplement> | ::= <Right Supplement> | <Left Supplement> | <Bi-Supplement> |
| <Right Supplement> | ::= <Right Supplement Begin><Supplement Element><Supplement End> |
| <Left Supplement> | ::= <Left Supplement Begin><Supplement Element><Supplement End> |
| <Bi-Supplement> | ::= <Supplement Begin><Supplement
Element> '|'
<Supplement Element> <Supplement End> |
| <Supplement Element> | ::= <Single Supplement> | <Double Supplement> |
| <Single Supplement> | ::= <Supplement Element> |
| <Double Supplement> | ::= <Supplement Element><Supplement Separator><Supplement Element> |
| <Right Supplement Begin> | ::= '(' |
| <Left Supplement Begin> | ::= "(|" |
| <Supplement End> | ::= ')' |
| <Supplement Separator> | ::= '#' |
| <Supplement Element> | ::= <String> |<String><String Separator><String> |
| <String Separator> | ::= '=' |
| <String> | ::= see 2.3 |
In its core concept, Flag Rule resembles the MECS
system used in "Wittgenstein Archives" [Robinson 1994]
and the TEI <app> element [McQueen and Burnard 1994].
The basic syntax of Flag Rule starts with a string enclosed by
a pair of '/'s to indicate the region that is annotated by a following
supplementary string enclosed by '(' and ')'. Figure 4 shows an
example markup of the Flag Rule.

2.3 Value Added Rule
One of the main purposes of textual study is to create an index. However, there are no spaces between words in Japanese text, which makes lexical procedures to pick up words within sentences very difficult. In other words, researchers have to separate a sentence into words before lexical studies can be initiated. The problem is that the criteria to identify word are different for each researcher. Moreover, Japanese words have word-forming features to form compound words, and this feature is different from work to work, genre to genre, and period to period. Thus, Japanese lexical analysis is very difficult.
As mentioned above, we believe that these tasks require a high degree of expertise and should be done by researchers themselves. The "Value Added Rule" is provided as the third guideline to separate a sentence into words and to put some attributions (i.e., phonetic representation of Chinese ideograph characters) to the words in preparation for further analysis. Below, we show the syntax of the Value Added Rule.
| <String> | ::= word | <Value Added Begin> word <Value Added End><Value Added> |
| <Value Added> | ::= <Value Begin><Values><Value End> |
| <Values> | ::= <Value 1> | <Value 2>
| <Supplement Value>
| <Value 1><Binding Symbol><Value 2> |
| <Value 1> | ::= Phonetic Representation of
a Chinese Ideograph
<Attribution 2 Begin> Chinese Ideograph <Attribution End> | <Repeating Symbol><Value 1> |
| <Value 2> | ::= <Attribution 1 Begin><Variation><Attribution
End>
<Attribution 2 Begin> Information <Attribution End> | <Repeating Symbol><Element 2> |
| <Value Supplement> | ::= Not Use |
| <Variation> | ::= Part of Speech | Name | Location | Position |
| <Value Added Begin> | ::= ' ' |
| <Value Added End> | ::= ' ' |
| <Value Begin> | ::= '(' |
| <Value End> | ::= ')' |
| <Attribution 1 Begin> | ::= '[' |
| <Attribution 2 Begin> | ::= "[," |
| <Attribution End> | ::= ']' |
| <Binding Symbol> | ::= '!' |
| <Repeating Symbol> | ::= ';' |
The basic syntax of the Value Added Rule starts with a word enclosed by a pair of blank ' ' that is followed by attributions enclosed by '[' and ']'. Since the identification of words and their attributions depend on the objectives of research, it is impossible to define all eventualities ahead of time. Thus, the Value Added Rule is incomplete.
2.4 Evaluation
Using KOKIN Rules, we marked up some classical materials as shown in Table 1. The example of "The Anthology of Story Telling" by KOKIN format is shown in Appendix 1. The correctness of the data is verified by constructing a parser.
Next we constructed full-text databases to evaluate the usability of KOKIN data. We examined three types of full-text databases. The one is a CD-ROM database that is constructed on Sony's "MediaFinder". MediaFinder uses a kind of hyperlink to realize the hierarchical string search of text [Hara 1993]. The second type is an SGML database that is discussed in the next section. The third type is an ordinal database. Here, the markup is based on the Tag Rule and the Flag Rule. The nested and repeating structures of the KOKIN data are normalized to comply with relational data model. This database will be made public in next fiscal year. Figure 5 shows an example display of this database.

As KOKIN Rules were designed for ease of understanding and for use by researchers of Japanese classical literature, their syntax is simple and all of the full-text data in NIJL are compiled based on these rules. However, as KOKIN Rules are independent from other standards, there were few tools to parse and check KOKIN text. Recently, SGML [ISO 1976, JIS 1992] has been considered as an encoding scheme for transmission of text data among the systems [Herwijnen 1994]. Consequently, we decided that we should convert our KOKIN-marked text to SGML-marked text to support interoperability among data. Since SGML has also become popular in Japan, we set up a new project to construct full-text database using SGML [Hara 1995, Hara 1996].
This section describes our case study to transcribe
Japanese classical text using SGML. We have conducted following
four experiments.
This section also uses "The Anthology of Story Telling" as sample text. The tools used in this experiment are MARK-IT (Sema Software Technology) for a parser, and OPEN-TEXT (Open Text Co.) for string searching.
3.1 DTD Creation
DTD is basically obtained from Figure 3. However,
there are some ambiguous symbols in KOKIN Rules. For example,
the symbol '(' is used in Flag Rule (as <Supplement Begin>);
however, the same symbol also appears in Value Added Rule (as
<Value Begin>). We can easily differentiate these usages
by finding the locations where these symbols appear. That is,
'(' of the <Supplement Begin> appears after '/' of the <Flag
End>, on the other hand, '(' of the <Value Begin> appears
after the ' ' of the <Value Added End>. This is a context
dependent class, but SGML (context free class) cannot accept this
feature. To resolve these ambiguities, we analyzed the syntax
of KOKIN rules using E-R model to check the precise relationships
between tags and flags defined in KOKIN Rules. The DTD of "The
Anthology of Story Telling" was created during this work.
The correctness of this DTD was checked by a DTD compiler.
Japanese use about 2000 characters in ordinary life. Japanese characters are comprised of Chinese ideograph characters called KANJI, two styles of Japanese phonetic characters called KANA and KATAKANA, Roman characters called ROMA-JI, and some symbols. Since there are many characters, we use a 2 bytes to coding system to express characters [Lunde 1993]. Thus, we have to modify the SYNTAX definition in SGML declaration [Bryan 1988]. The SGML declaration and DTD of "The Anthology of Story Telling" are shown in Appendix 2.
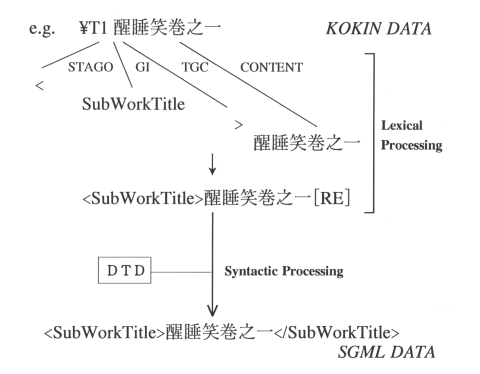
3.2 Text Data Conversion
The basic data conversion procedure from KOKIN to
SGML is simply to replace the string of "Japanese Yen Mark"
followed by "Tag" to the corresponding string of START-TAG(<)
and END-TAG(>) of SGML (Figure 6). Lexical processing is introduced
for this process. Another role of the lexical processing is to
insert some SGML starting tags to identify the elements marked
by Flag Rules as mentioned above. This process creates pre-processed
SGML data that contains a lot of omit tags. Syntactic processing
checks the correctness of the pre-processed data then converts
it to full tagged SGML data by referring to DTD.
One peculiarity of "The Anthology of Story Telling" is that it has a lot of annotations such as phonetic reading and notes. Researchers believe that the digitally transcribed text should preserve original text features because of their importance to their work. In response to this request, we set some attributes to tags for expressing layout features. We give some examples in the following paragraphs.
Basic Annotation. Figure 7 shows a basic annotation that expresses a phonetic reading of the corresponded Chinese ideograph character (KANJI). The upper part of the figure shows an original SGML data. The middle part shows the same SGML data in English for convenience of explanation. The lower part is its printout, which will be discussed in section 3.4.

In our markup, an annotation is expressed with two components. One is an identification of the region in a main sentence line where the annotation is attached. This region is marked up as <SuppElement>. The other is the annotation itself. This is marked up as <Supp>. <SuppElement> has one attribute named "fg." This is a flag that indicates whether the annotation is comprised of more than one line, that is, an annotated region in the main sentence is comprised of more than one line. Here, fg="OFF" means that this annotation is a single line.
Divided Annotation. Figure 8 shows the example of an annotation that is comprised of more than one line. This is indicated by fg="ON" in the <SuppElement>.

Double Annotation. Figure 9 shows an example of a double annotation: annotations appear on both sides of a main sentence line. <BiSupp> after the region of <SuppElement> means the beginning of the double annotation. Here, <RightSupp> means that this annotation appears on the right side of the main sentence line, and <LeftSupp> means that this annotation appears on the left side of the main sentence line.

Inserted Note. Figure 10 shows an example of an inserted note. Here, an inserted note is marked up as <Insert>, which indicates the position of the inserted note. An inserted note itself is sometimes comprised of more than one line. An element <ln> in <Insert> means the order of lines in the inserted note. <Insert> has an attribute "fg." This is the flag that indicates whether the inserted region is over two main sentence lines. For example, fg="OFF" means the inserted note is not over two main lines.
The example of markup data by SGML format is shown in Appendix 3. This is the same text as Appendix 1.

3.3 Full-Text Searching
There are many problems in text searching. At first, we constructed full-text database using a relational database system. Though a relational database has standard query languages based on an elegant mathematical model (i.e., SQL, QBE), the relational database imposes fairly strict restrictions on data structure. In other words, a relational database for structured text is comprised of many "pointer tables," which decreases the searching effectiveness. However, an object-oriented database is suitable for complicated data structures, but it has neither standard search methods nor a standard language such as SQL.
Text searching can be regarded as a "search for a string in a desired element in data." This means that a full-text database system can be constructed on a string searching system. In the study of Japanese classical literature, searching a string of interest is a common task. There are fast string searching machines or software, and some of these products can handle Japanese SGML data. Consequently, we are conducting a new examination into constructing a full-text database system using string searching software (i.e., OPEN TEXT).
3.4 Publishing
SGML data can be seen as intermediate data for storage, data conversion, data interchange, database publishing, electronic publishing, and publishing. We intend to establish an in-house publishing system of the transcribed materials. At present, since we have no Document Style Semantics and Specification Language (DSSSL)-compliant tools, our in-house publishing system converts SGML data to LaTeX data in order to print out text. Figure 11 shows an example printout of "The Anthology of Story Telling" that is the electronic reproduction of Figure 2.

There remain difficulties in compiling SGML data of Japanese classical literature. This section describes several examples.
4.1 Non-Nesting Structure
The first problem is a text structure that is illegal to SGML. For example, there are missing pages in the classical materials because of damage resulting from deterioration, worms, and so on. These missing pages can be seen as layout information. In this case, the empty tag to indicate the missing pages is available. However, some researchers consider the missing pages as the essential information of the original materials. The problem is that if the ordinary tag is used to indicate the region of missing pages, these tags would override another region. Following is an example.
..........<Chapter>.................<MissingPage> ...... Recovered Text by using Another Materials ....
......... </Chapter> <Chapter> .......... </MissingPage> ....................
In this case, region <MissingPage> overrides
the region of two <Chapter>s. This is the illegal description
in SGML.
4.2 Non-Standard Characters
The second problem is KANJI. Some researchers say over 50,000 KANJI characters are needed to describe Japanese classical texts. However, only 12,546 characters are registered as a Japan Industrial Standard (JIS), and only 6,355 characters among those are actually available on the computer. Thus, many users define their own character set as extra-standard characters. NIJL also has made about 2,000 extra standard characters (KANJI) and more than 10,000 fonts for displaying and publishing. The problem is that most of the client computers on the network cannot display these extra character sets.
4.3 Difficulty of SGML Markup
It is indubitable that SGML is a more appropriate text markup language for data exchange and interoperability than the KOKIN Rules. However, as SGML description is rather complicated, many humanities researchers hesitate to use SGML for their data construction. One solution is the SGML editor, but we don't have any effective editors yet.
We do have the KOKIN-SGML converter, which can check the KOKIN text before converting it to SGML text. In another words, KOKIN rules can be seen as the pre-tagging system of SGML. Recently, we begun to think that KOKIN rules would be a good solution for transcribing the primary text.
This paper describes our study on the text data description rules for Japanese classical literature. We investigated the various functions for the text data description by analyzing Japanese classical materials. As a result, we have defined and developed the rules with three functions, calling these KOKIN Rules. Many Japanese classical texts have been electronically transcribed using these rules. We have evaluated their availability especially for their application to database, CD-ROMs, and publishing. Recently, as SGML has become a popular markup language, we have conducted a study of conversion to the SGML compliance text. A full-text database system has been produced based on the string search system conforming to SGML.
[Bryan 1988] Martin Bryan: SGML An Author's Guide to the Standard Generalized Markup Language, Addison-Wesley, 1988.
[Hara. 1993] Shoichiro HARA and Hisashi YASUNAGA: On the Fulltext Database of Japanese Classical Literature, Joint International Conference ALLC-ACH Conference Abstracts, pp.61-63, 1993.
[Hara. 1995] Shoichiro HARA and Hisashi YASUNAGA: On the Text Based Database Systems for Public Service: Joint International Conference ALLC-ACH Conference Abstracts, pp.43-45, 1995.
[Hara. 1996] Shoichiro HARA and Hisashi YASUNAGA: SGML Markup of Japanese Classical Text - A Case Study-Joint International Conference ALLC-ACH Conference Abstracts, pp.131-134, 1996.
[Herwijnen 1994] Eric van Herwijnen: Practical SGML, Kluwer Academic Publishers, 1994.
[ISO 1986] ISO 8879: Information processing - Text and office systems - Standard Generalized Markup Language (SGML), 1986.
[JIS 1992] JIS X 4151-1992: Standard Generalized Markup Language (Japanese), 1992.
[Lunde 1993] Ken Lunde: Understanding Japanese Information Processing, O'Reilly & Associates, Inc., 1993.
[Robinson 1994] Peter Robinson: The Transcription of Primary Textual Sources Using SGML, Office for Humanities Communication Publications No.6,1994.
[McQueen and Burnard 1994] C.M. Sperberg-McQueen and Lou Burnard: Guidelines for Electronic Text Encoding and Interchange (TEI P3), ACH,ACL,ALLC, 1994.
[Mutoh and Oka 1976] Sadao Mutoh and Masahiko Oka: Anthology of Story Telling (Japanese), Tokyo-Do, 1976.
[Yasunaga 1996] Hisashi
YASUNAGA: Text Data Description Rule for Japanese Classical Literature (Japanese),
Natural Language Vol.3, No.4, pp.3-29,1996.
Shoichiro HARA is associate professor of the National Institute of Japanese Literature. Hisashi YASUNAGA is professor of the National Institute of Japanese Literature.



hdl:cnri.dlib/july97-hara