
This paper is a abbreviated version of The Warwick Framework: A Container Architecture for Aggregating Sets of Metadata. It describes a container architecture for aggregating logically, and perhaps physically, distinct packages of metadata. This "Warwick Framework" is the result of the April 1996 Metadata II Workshop in Warwick U.K.
With the rapid increase in the number and variety of networked resources, there is a growing need for an architecture for associating diverse types of metadata with those resources. This requirement is increasingly obvious in the current World Wide Web, where the primary tools for finding networked resources are "web-crawlers" or "spiders" that index the full-text of HTML pages. While the value of these tools should not be underestimated, their shortcomings become obvious when one, for example, searches for documents about "Mercury" and finds a mixture of pages about the planet Mercury, the element Mercury, the Greek God Mercury, and articles from the San Jose Mercury-News. More importantly, these tools are completely useless for the many non-textual documents - images, audio, video, and executable programs (accessible through CGI scripts) - that populate the Web.
A series of metadata workshops, the first in March 1995 in Dublin Ohio and the second in April 1996 in Warwick U.K, were convened to address this issue and propose solutions. The Dublin Workshop resulted in the Dublin Core, a set of thirteen metadata elements intended to describe the essential features of networked documents. The Dublin Core metadata set is meant to be both simple enough for easy use by creators and maintainers of Web documents and sufficiently descriptive to assist in the discovery and location of networked resources. The thirteen elements of the Dublin Core include familiar descriptive data such as author, title, and subject. A few fields in the Core, such as coverage and relationship, are less familiar.
The Warwick Workshop was convened a year later to build on the Dublin results and provide a more concrete and operationally useable formulation of the Dublin Core, in order to promote greater interoperability among content providers, content catalogers and indexers, and automated resource discovery and description systems. The April 1996 workshop also was an opportunity to assess a year of experimentation with the Dublin Core by a number of researchers and developers.
While there was consensus among the attendees that the concept of a simple metadata set is useful, there were a number of fundamental questions concerning the real utility of the Dublin Core as it was defined at the end of the preceding workshop. Does the very loosely defined Dublin Core really qualify as a "standard" that can be read and processed programmatically? Should the number of the core elements be expanded, to increase semantic richness, or reduced, to improve ease-of-use by authors and/or web publishers? Will authors reliably attach core metadata elements to their content? Should a core metadata set be restricted to only descriptive cataloging information or should it include other types of metadata such as administrative information, linkage data, and the like? What is the relationship of the Dublin Core to other developing work in metadata schemes, particularly in those areas such as rights management information (terms and conditions)?
The workshop attendees concluded that the answer to these questions and the route to progress on the metadata issue lay in the formulation a higher-level context for the Dublin Core. This context should define how the Core can be combined with other sets of metadata in a manner that addresses the individual integrity, distinct audiences, and separate realms of responsibility of these distinct metadata sets.
The result of the Warwick Workshop is a container architecture, known as the Warwick Framework. The framework is a mechanism for aggregating logically, and perhaps physically, distinct packages of metadata. This is a modularization of the metadata issue with a number of notable characteristics.
The separation of metadata sets into packages does not imply that
packages are completely semantically distinct. In fact, it is
a feature of the Warwick Framework that an individual container
may hold packages, each managed and maintained by distinct parties,
which have complex semantic overlap.
The organizers of the 1995 Dublin Metadata Workshop intentionally limited its scope, avoiding, as the workshop report states, "the size and complexity of the resource description problem". While this strategy was effective for reaching consensus at the first workshop, it became obvious at the second workshop that it was an impediment to moving beyond the Dublin Workshop results. By the end of the first day of the Warwick Workshop, three questions had surfaced, each of which made clear the need to broaden our perspective.
We can answer these questions by stepping back from our focus on core metadata elements and examining some of the general principals of metadata.
Descriptive cataloging is but one of many classes of metadata. Yet, even if we restrict ourselves to this category, we observe that there exists and is legitimate reason for a variety of cataloging methodologies and interchange formats. The Anglo-American cataloging rules (AARC2) and MARC interchange format (and its numerous variations) are well established in the library world. MARC records are generally the domain of professional catalogers because of the complex rules and arcane structure of the MARC record. In addition there are a number of simpler descriptive rules, such as that suggested by the Dublin Core. These are usable by the majority of authors, but do not offer the degree of precision and organization that characterizes library cataloging. Finally, there are domain-specific formats such as the Content Standard for Digital Geospatial Metadata (CSDGM) that is the result of work by the Federal Geographic Data Committee (FGDC).
Descriptive cataloging alone, however, does not cover the complete set of descriptive information required in the information infrastructure. We list below some of the other metadata types that are required for real work applications.
The range of metadata needed to describe and manage objects is likely to continue to expand as we become more sophisticated in the ways in which we characterize and retrieve objects and also more demanding in our requirements to control the use of networked information objects. The architecture must be sufficiently flexible to incorporate new semantics without requiring a rewrite of existing metadata sets.
Each logically distinct metadata set may represent the interests of and domain of expertise of a specific community; for example, catalogers should create and maintain descriptive cataloging sets and parties with legal and business expertise should oversee terms and conditions metadata sets. The syntax and notation of each should be determined by the responsible party and fit the semantic requirements of the type of metadata. For example, textual representations might be sufficient for descriptive cataloging data, but are inappropriate for terms and conditions metadata, which may be expressible only through executable (or interpretable) programs.
Just as there are disparate sources of metadata, different metadata sets are used by and may be restricted to distinct communities of users and agents. Machine readability may be a high priority for some types of metadata, whereas others may be targeted for human readability. The terminology in some types of metadata may be domain specific. Each "user" of metadata should be able to directly access that metadata that is relevant to it. From the opposite perspective, there may be reason to selectively restrict access to certain types of metadata associated with an object to certain communities of users or agents. Finally, metadata related to an object may have an independent existence as separately owned and separately priced intellectual property.
Strictly partitioning the information universe into data and metadata is misleading. What may appear to be metadata in one context, may look very much like data in another. For example, some critic's review of a movie qualifies as metadata - it is a description of the content, the movie. However, the review itself is intellectual content that can stand alone as data in many instances. Like other data it may have associated metadata and, notably, terms and conditions that protect it as an intellectual object. This recursive relationship of data and metadata may nest to an arbitrarily deep level.
If we allow for the fact that metadata for an object consists of logically distinct and separately administered components, then we should also provide for the distribution of these components among several servers or repositories. The references to distributed components should be via a reliable persistent name scheme, such as that proposed for Universal Resources Names (URNs) and Handles. We note that indirect reference to distributed components also implies that individual metadata sets may be shared. For example, assume a repository with many content objects, some of which have common terms and conditions for access (e.g. a university digital library with a site license for a set of periodicals). We should be able to express this by linking, by a name reference, one encoding of the terms and conditions to the set of objects. Similarly, we should be able to modify the terms and conditions for the set of objects by changing the one shared encoding. The shared terms and conditions metadata may reside in a repository managed by an outside provider that specializes in intellectual property management.
The result of this analysis at the Warwick Workshop is an architecture, the Warwick Framework, for aggregating multiple sets of metadata. The Warwick Framework has two fundamental components. A container is the unit for aggregating the typed metadata sets, which are known as packages.
A container may be either transient or persistent. In its transient form, it exists as a transport object between and among repositories, clients, and agents. In its persistent form, it exists as a first-class object in the information infrastructure. That is, it is stored on one or more servers and is accessible from these servers using a globally accessible identifier (URI). We note that a container may also be wrapped within another object (i.e., one that is a wrapper for both data and metadata). In this case the "wrapper" object will have a URI rather than the metadata container itself.
Independent of the implementation, the only operation defined for a container is one that returns a sequence of packages in the container. There is no provision in this operation for ordering the members of this sequence and thus no way for a client to assume that one package is more significant or "better" than another. At the container level, each package is an bit stream. One implication of these properties is that any encoding (transfer syntax) for a container must allow the recipient of the container to skip over unknown packages within the container (in other words, the size of each package must be self describing at the container level).
Each package is a typed object; its type may be inferred after access by a client or agent. Packages are of three types:
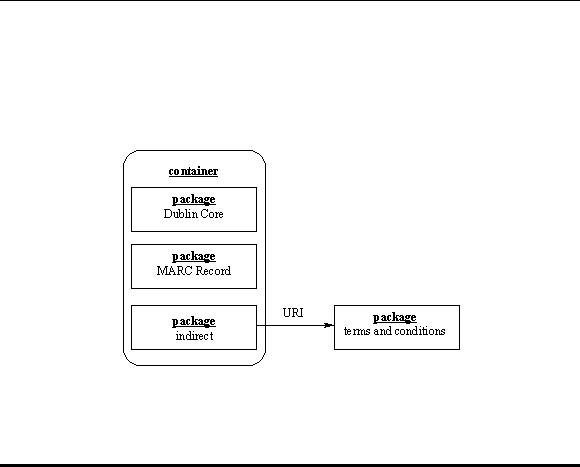
The figure below shows a simple example of a Warwick Framework container. The container in this example contains three logical packages of metadata. The first two, a Dublin Core record and a MARC record, are contained within the container as a pair of packages . The third metadata set, which defines the terms and conditions for access to the content object, is referenced indirectly via a URI in the container. Note that the syntax for terms and conditions metadata is not yet defined.
The mechanisms for associating a Warwick Framework container with a content object (i.e., a document) depend on the implementation of the Framework.
The reverse linkage, that which ties a container to a piece of intellectual content, is also relevant. Anyone can, in fact, create descriptive data for a networked resource, without permission or knowledge of the owner or manager of that resource. This metadata is fundamentally different from that metadata that the owner of a resource chooses to link or embed with the resource. We, therefore, informally distinguish between two categories of metadata containers, which both have the same implementation.
The following figure shows an example of this relationship. Three metadata containers are shown. The one internally-referenced metadata container is embedded in the content object (it does not have a URI, nor does it have a linkage package that references the content). The two externally-referenced metadata containers are independent objects. They each have a URI and reference the content object via its URI.
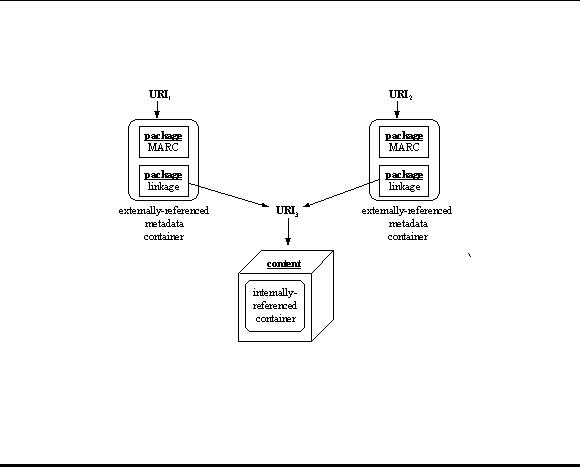
The internally-referenced metadata container in this illustration could also be indirectly referenced by the content. In this case it would have its own URI (say URI4) and would have a linkage package referencing URI3 (the content).
Time at the Warwick workshop did not permit a full exploration of all the issues involved in the proposed framework. There are several topics that urgently call for more detailed and extended examination prior to finalizing the framework. We briefly summarize those issues here.
Simplicity of design and rapid deployment were primary considerations in the design of the Dublin Core. At first glance it may seem that, with the Warwick Framework, we have forsaken this motivation and have proposed an architecture that does not fit with the current world of HTML, HTTP, and WWW browsers. In fact, the basic notion of the Framework, the ability to place a number of metadata sets in a container, can be expressed in the context of the existing WWW infrastructure.
We miss an important opportunity, however, if we constrain the design and possible implementations according to the existing Web. This infrastructure will surely evolve and may even be replaced by a more powerful information infrastructure. Research and development of such an infrastructure is being undertaken in the NSF/DARPA/NASA Joint Digital Library Initiative, other international digital library research projects, and a number of other venues.
The complete version of this paper provides details on a number of possible implementations. We briefly summarize these below.
multipart type in MIME, which is used for messages
that include multiple components, each with a possibly different
type. The body parts of a MIME multipart message directly correspond
to the packages in a Warwick Framework container. In addition,
the MIME content-type message/external-body can be
used to implement the Warwick Framework "indirect package".
<container>
element and the %PackageTypes parameter entity to
implement the container/package hierarchy. Parameter entities
are essentially text substitution macros for portions of a DTD.
Package which have their own DTDs are easily included using the
SGML idiom of overriding the definition of %md-set
parameter entity, and by providing the required DTD fragment in
the document's declaration subset. Packages in a non-SGML format
can be incorporated by use of the NOTATION attribute
on the <package> element.
MetaDataContainer
is an object with one method - GetPackages - that
returns the set of packages in the container. These packages are
of type MetaDataPackage, which is the root of a type
hierarchy that sub-types to all the possible manifestations of
a package in the Warwick Framework.
This paper would not have been possible without the contributions
of C. Lynch and R. Daniel, Jr., the co-authors of the complete
Warwick Framework paper. In addition, the author wishes to thank
the organizers of the metadata workshops, especially S. Weibel,
whose efforts provided an essential forum for this and other related
work. The ideas here draw extensively from discussions at the
Warwick workshop; they also reflect the influence of work done
on the still-incomplete White Paper on Networked Information Discovery
and Retrieval by C. Lynch, A. Michaelson, C. Preston, and C. Summerhill
that is being prepared for the Coalition for Networked Information.
We would also like to acknowledge the extensive work of E. Miller,
J. Knight, M. Tomlinson, L. Burnard, C.M. Sperberg-McQueen, and
L. Quin on the HTML, MIME, and SGML implementation proposals described
here.



hdl://cnri.dlib/july96-lagoze