James Frew
Michael Freeston
Randall B. Kemp
Jason Simpson
Terence Smith
Alex Wells
Qi Zheng
Alexandria Project
Department of Computer Science
University of California
Santa Barbara, CA 93106

The Alexandria Digital Library Project is one of six projects funded under the Digital Libraries Initiative (DLI), a joint program of the National Science Foundation (NSF), the Defense Advanced Research Projects Agency (DARPA), and the National Aeronautics and Space Administration (NASA). The Alexandria Project, which is based at the University of California, Santa Barbara (UCSB), brings together a unique blend of researchers, developers, and educators, spanning the academic, public, and private sectors, with the purpose of achieving two goals.
The first goal is to explore a variety of research and development problems related to a distributed digital library for geographically-referenced information. ``Distributed'' means the library's components may be spread across the Internet, as well as coexisting on a single desktop. ``Geographically-referenced'' means that it is possible to access information from the items in the library by some description of geographic locations on Earth, as well as by other characteristics of the information.
The second goal of the project is to build a testbed system that supports the research and development activities and provides a basis for an operational library. All the DLI projects are required to build a testbed system, both to ensure that their theoretical ideas are practically verified, and to give the rest of the world access to (and participation in) the intellectual ferment inside the DLI community.
The Alexandria Digital Library (ADL) is an online information system that is based on a traditional map library housed in the Map and Imagery Laboratory (MIL) in the Davidson Library at UCSB. The ADL is being implemented as part of the Project's testbed environment.
This remainder of this paper describes the ADL Testbed at a variety of levels. We begin with a brief description of the physical components of the Testbed, followed by a description of the logical system architectures that the Testbed is intended to support, followed by a detailed discussion of the physical architecture of the two digital library systems the Testbed has supported to date.
NOTE: All references herein to ``The Testbed'' refer to the ADL Testbed as of 01 July 1996.
This section describes the physical components (hardware, software, and network) that comprise the Testbed.
The Testbed includes 8 UNIX workstations (6 Digital Equipment Corp. Alpha-based and 2 Sun Microsystems SPARC-based) and 2 PCs. Half of the workstations are used exclusively by the Testbed development team, and the others host the Testbed's database, HTTP, and FTP servers. The PCs are used for scanning, data modeling, and metadata entry.
Testbed workstations have from 64 to 256 MB RAM and from 1 to 18 GB local disk storage. The Testbed's FTP server also supports 30 GB of RAID (redundant array of independent disks) storage and a 100 GB optical disk subsystem.
Commercial software packages supported by the Testbed include database management systems (Access, Illustra, O2, Oracle, Sybase), geographic information systems (ARC/INFO, ArcView), information retrieval systems (RetrievalWare) and Web servers (AOLserver [1]). Significant freeware packages supported by the Testbed include the Java, Perl, Python, and Tcl/Tk languages, and the Inter-Language Unification (ILU) object interface system (ILU is a partial implementation of the industry-standard Common Object Request Broker Architecture [CORBA]).All Testbed hosts are connected to a single 10 Mbit/sec local-area network (LAN). The Testbed LAN is gatewayed onto UCSB's 100 Mbit/sec backbone network, which is in turn gatewayed onto a 1.54 Mbit/sec (i.e. T1) connection to the Internet backbone. The single T1 connection for the entire UCSB campus is admittedly a bottleneck, for which we are exploring alternatives.
The Testbed's current logical architecture is described in detail in the Alexandria Project's 1996 Annual Report. At the highest level, the architecture has four components:
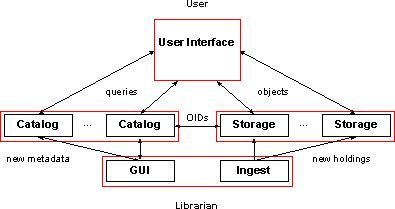
The storage component maintains and serves up the digital holdings of the library; these correspond to the ``stacks'' of physical holdings (books, journals, etc.) in a traditional library. The catalog component manages, and facilitates searches of, the metadata describing the holdings, analogous to a traditional library card catalog. Catalog metadata are associated with storage objects by unique object identifiers, analogous to traditional library call numbers. The ingest component comprises the mechanisms by which librarians and other authorized users populate the catalog and storage components. Finally, The user interface component is the collection of mechanisms by which one interacts with the catalog (to conduct a search) or the storage (to retrieve objects corresponding to search results).
The simplest mapping of this architecture onto a wide-area network environment like the World Wide Web yields two sets of refinements, one obvious, one deceptively subtle:
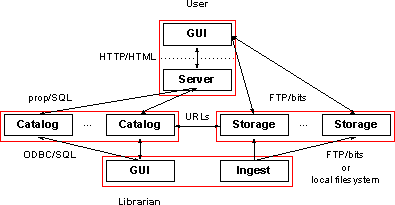
The obvious refinement is the greater specificity of information flowing between the components: queries are expressed in SQL over a database client-server connection; storage objects are referenced by URLs and retrieved by FTP; etc.
The less-obvious refinement is the partitioning of user interface functionality between the Web server and client (browser; e.g. Netscape). At the highest level at which our architecture is specified, there is really no difference between the Web client and server; collectively, they implement a user interface. However, the limited capabilities of (pre-Java) Web browsers, coupled with the relative extensibility of Web servers (particularly the AOLserver), leads to the use of the Web server as a de facto ``middleware'' layer between the catalog and the user interface. We will examine this notion in more detail in the Conclusions section below.
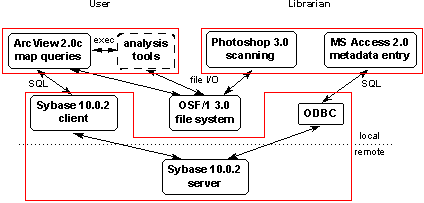
All components of the Rapid Prototype system ran on a single host, except the Sybase database server, which managed the catalog metadata. Even this level of distribution was not essential -- a demo version of the Rapid Prototype used a dBase file in lieu of a database system to manage the metadata, allowing the entire demo system to be freely distributed on a CD-ROM.
Almost all the Rapid Prototype's functionality was implemented within the ArcView GIS, by scripts written in ArcView's internal Avenue language. This reliance on a large, expensive commercial application made the Rapid Prototype inherently unscalable, so it is no longer being developed or supported.
The second, current version of the ADL implemented by the Testbed is the ``Web Prototype'', whose primary goal is making the ADL accessible from the World Wide Web.
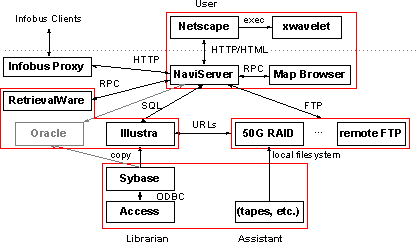
The remainder of this section focuses on the Testbed-specific aspects of the Web Prototype implementation.
The Web Prototype uses three database management systems. Any metadata that must be entered manually are entered through Microsoft Access. The primary reason for using Access that it permits the librarians entering the data to build their own customized user interfaces, thus maximizing entry speed and minimizing errors. Access' ODBC interface allows it to function as a front end to any of our other DBMSs.
All metadata entering the Web Prototype, either manually (through Access) or automatically (by batch scripts) is staged through a Sybase database. This is partly a historical artifact, since Sybase was our first DBMS; however, it also gives us the opportunity to quality-check the metadata under a standard relational schema (i.e. one without vendor-specific type, function, or rule extensions). We are thus assured that metadata exported from the Sybase schema will not only be reasonably free of internal inconsistencies, but will also be supportable in any relational database. Finally, performing the staging and Q/A in a separate database keeps a substantial burden off our primary catalog database server.
The database that actually supports catalog searches is currently implemented in Illustra. This is primarily because only Illustra (of our current databases) supports SQL-level spatially-indexed searches (i.e., ``contains'' or ``overlaps'' operations on polygonal data types.) This extension reduces the time required by a typical spatial search by at least a factor of 10, so we find it compelling. To preserve database independence, we add the Illustra polygon attributes to the basic catalog schema without disturbing the rest of the attributes.
We are also evaluating various Oracle DBMS products, especially the spatial data extensions, in close cooperation with Oracle engineers. We will evaluate other DBMSs as time and resources permit.
The Excalibur RetrievalWare package currently supports a specialized user interface function. When querying relational databases, it is much more efficient to request exact matches for string-valued attributes than to request subset (e.g. ``leads with'', case-insensitive, etc.) matches. However, the domain of many of our catalog attributes is so large (e.g., our placename list has over 6 million entries) that discovering exact matches by exhaustive search is impractical. We therefore use RetrievalWare's ``fuzzy'' match capability (a semantic network built from various dictionaries and thesauri) to suggest possible exact matches for imprecisely specified attributes (e.g., ``san ba'' matches both ``SANTA BARBARA'' and ``SAN BUENA VENTURA''). The user can then select any combination of the suggested values to rapidly search the actual catalog.
The nexus of the Web Prototype system is the AOLserver Web server. In addition to supporting the WWW standard HTTP protocol, the AOLserver supports two important additional capabilities.
First, the AOLserver can connect directly to a DBMS, instead of having to spin off a separate process to manage each database transaction. This dramatically increases the speed of catalog accesses from the Web. This feature is also used for state maintenance, so that the notion of a ``session'' with the Web Prototype can be sustained over the stateless HTTP protocol. The current state of the user interface is saved into and restored from a separate Illustra database after each HTTP transaction.
Second, the AOLserver has an embedded interpreter for the Tcl/Tk scripting language. The server can assign URLs to a Tcl script, causing that script to be invoked when a user (through their Web browser) requests the URL. This dramatically increases the speed of dynamic Web page generation, compared to the more common CGI mechanism, whereby the server invokes a separate process for each dynamically-generated page.
The Stanford University Digital Libraries Project is developing an interoperability infrastructure for digital libraries, called the InfoBus, from CORBA-based distributed object technology. The Web Prototype includes an interface (via the AOLserver) to a local (to Santa Barbara) InfoBus ``proxy'' (i.e., a software module that accepts incoming InfoBus queries and translates them to a form understood by the Web Prototype). The InfoBus query language is currently strongly oriented toward bibliographic queries, as opposed to spatial queries, so it is not optimal for querying ADL. However, we expect that to change.
The ADL Testbed is very much a work-in-progress. In the space remaining, we will list some of the more significant findings we will be applying to the next systems that the Testbed will host.
The scripting capability of the AOLserver, coupled with the ubiquity of Web browsers, has led to the most significant architectural feature of the Web Prototype: a user interface predicated on a ``dumb client - smart server'' model. The client is assumed to be capable of rendering HTML 2.0 with very few extensions (most notably Netscape tables), and of supporting the basic HTTP protocol plus Netscape cookies. Not only must we make the AOLserver go to heroic lengths to simulate statefulness over a stateless protocol, but we must also attempt to paint a rich, compelling user interface using an extremely restricted palette. The single most salutary consequence we expect from a world of Java-enabled Web browsers is a more equitable distribution of user interface creation between client and server.
Just as Avenue provided the ``glue'' for the Rapid Prototype, so Tcl/Tk, running in the AOLserver, provides the glue for the Web Prototype. The importance of having a layer in the architecture that is scriptable, and thus highly malleable, cannot be overstated. For example, connecting the InfoBus proxy to the Web Prototype was a single day's work once we realized that we could build an alternative ``HTML-less'' interface to the AOLserver in Tcl/Tk that was almost exactly what an previously-coded proxy expected.
More importantly, a middleware layer is crucial to our database independence strategy. The user interface to the Web Prototype expresses its queries as simple boolean expressions in conjunctive normal form (CNF). The middleware reads from the underlying database a definition schema that describes the mapping from the Web Prototype's uniform logical schema to the particular database's physical implementation thereof, and then translates the CNF query into database-specific SQL.
The top-level four-component architecture, while a reasonable model of a physical library and one that has served well till now, is clearly in need of revision. In particular, several of the components, including the user interface and catalog components, need to be refined into a set of components that is more in keeping with the large variety of services that must be supported in a library environment, digital or otherwise. In traditional libraries, many of these services are provided by librarians while interacting with users. It is also necessary to provide a ``workspace'' in which a user may access the various services available for accessing information by content and for manipulating the retrieved information. The ADL Testbed is currently entering a new development cycle that is moving in the direction of implementing the next version of the system in part as a set of diverse services that interact using CORBA-based distributed object technology.



hdl://cnri.dlib/july96-frew