|
|
|
| P R I N T E R - F R I E N D L Y F O R M A T | Return to Article |
D-Lib Magazine
July/August 2012
Volume 18, Number 7/8
Domain-Independent Mining of Abstracts Using Indicator Phrases
Ron Daniel, Jr.
Elsevier Labs
r.daniel@elsevier.com
doi:10.1045/july2012-daniel
Abstract
Abstracts contain a variety of domain-independent indicator phrases such as "These results suggest X" and "X remains unknown". Indicator phrases locate domain-specific key phrases (the Xs) and categorize them into potentially useful types such as research achievements and open problems. We hypothesized that such indicator phrases would allow reliable extraction of domain-specific information, in a variety of disciplines, using techniques with low computational burden. The low burden and domain-independence are major requirements for applications we are targeting. We report on an analysis of indicator phrases in a collection of 10,000 abstracts, and a more detailed analysis of the automated tagging of 100 abstracts from ten different disciplines. We found that a modest number (18) of regular expressions can achieve reasonable performance (F1 ~= 0.7, Precision ~= 0.8) in extracting information about achievements, problems, and applications across the 10 different disciplines.
Keywords: Artificial Intelligence, Natural Language Processing, Discourse, Text analysis
1. Purpose
We seek to mine abstracts, on the fly, to provide the user of a search service with more in-depth information about the current set of search results. For example, we might provide sidebars which contain:
- A list of open research problems mentioned in the abstracts,
- A list of potential applications of the research, or
- A list of experimental methods and devices used.
The information needed in those sample applications is frequently marked with indicator phrases, such as "X remains unknown" or "Our technique could be useful for X". The existence of such indicator phrases is well-known. For example, [5] used them in abstract generation as early as 1980, and they were not a new idea at the time. A very interesting alternative to the use of predefined lists of search terms is given in [1]. They use an unsupervised learning technique to start from a small set of sample indicators and develop a indicator phrase spotter with better recall and better handling of false positives than manually constructed ones. However, their method requires a dependency parse of the input text. That is a concern given the small amount of processing we can do on-the-fly and still offer acceptable performance.
Different applications need different types of information. While [6] noted the existence of "seven or eight" different types of indicator phrases it did not provide a clear taxonomy of them. There are many different categorizations of the kinds of structures used by authors to convey information of various types. Well-known is Teufel's "Argumentative Zoning"[8] which categorizes every sentence into one of seven zones: Aim, Textual, Own, Background, Contrast, Basis, or Other. However, we do not seek to categorize every sentence. Instead, we are interested in extracting portions of a few sentences. We also need more specific typing information. For example, open problems vs. potential applications are not clearly identified in that scheme. Two papers that provide a survey of other classifications are [2] and [9]. The taxonomy in Table 1, taken from [9], was a good match to our initial intuitions about the problem and was used as a starting point for our experiments.
Table 1: Epistemic Taxonomy from [9]
| Segment | Description | Example |
| Fact | a claim accepted (by the author) to be true | "mature miR-373 is a homolog of miR-372" |
| Hypothesis | a proposed idea, not supported by evidence | "This could for instance be a result of high mdm2 levels" |
| Problem | unresolved, contradictory, or unclear issue | "further investigation is required demonstrating the exact mechanism of LATS2 action" |
| Goal | research goal of the current paper | "To identify novel functions of miRNAs..." |
| Method | experimental method | "Using fluorescence microscopy and luciferase assays" |
| Result | a restatement of the outcome of an experiment | "all constructs yielded high expression levels of mature miRNAs" |
| Implication | an interpretation of the results, in light of earlier hypotheses and facts | "our procedure is sensitive enough to detect mild growth differences" |
Most work on using discourse for information extraction has been conducted in the biomedical domain. Our target applications must work for researchers in any scientific, technical, or medical domain. Our focus on speed and domain-independence distinguishes this work from previous work such as [7], which looks at biomedical articles and uses a phrase-structure parser to extract the most information. A key question, of course, is how much accuracy will be lost as a result of this focus. That is the third of three main questions we investigated for this paper.
2. Procedure
This paper reports on an investigation into the following questions:
| Q1) | Do abstracts in all domains use similar indicator phrases, or do we have many indicators that are domain-specific? |
| Q2) | Are domain-independent indicator phrases reliable features for extracting and typing domain-specific information? |
| Q3) | What is the precision and recall of an extractor based on regular expressions (regexps), and how does its speed and accuracy compare to methods based on more extensive processing? |
2.1 Domain-Specific vs. Domain-Independent Indicator Phrases (Q1)
[4] has already noted differences in the indicator phrases between linguistics and biomedical texts. The question before us is if the differences are big enough to significantly affect the accuracy of a domain-independent tool.
To investigate Q1, a dataset of 10 specialties was created. We define a specialty as a search query restricted to content tagged with a particular subject domain. SCOPUS, a broad-coverage bibliographic database, already provides tagging by subject domains. Ten domains were selected, based on the most frequent subject domains in SCOPUS. Query strings for concepts within the domains were either provided by an expert in the domain, or created by the author of this study. The specialties are shown in Table 2. Each of the queries was run on SCOPUS, restricted to the appropriate domain, and the results sorted by their citation frequency. The abstracts for the ten most-cited papers in each specialty were used as the data set for the work described in the rest of this paper. The first four results in each domain were the training set, the next four were used in validation stages, and the last two were the test set.
Table 2: Domains and Specialties Used
| Domain | Speciality Query |
| Agriculture | "farm crops soil pesticide" |
| Astronomy | "exoplanet imaging" |
| Biology | "induced pluripotent stem cells" |
| Chemistry | "nanocrystallites synthesis" |
| Computer Science | "suffix arrays" |
| Earth Science | "monazite geochronology" |
| Engineering | "pavement durability" |
| Materials Science | nanoporosity" |
| Mathematics | "lemma theorem proof" |
| Medicine | "exercise factors for GH release" |
To see what kinds of indicator and key phrases exist, the training set was manually annotated for any apparent indicator phrases and the domain-specific key phrase(s) they mark. For Q1, a sentence could contain multiple indicator phrases and accompanying key phrases. Isolated key phrases were not marked up; there had to be an indicator phrase as well. This resulted in a set of 232 annotations, each with one indicator phrase and its accompanying key phrase(s). Each of the 232 annotations was analyzed to:
| 1) | Categorize the indicator as being domain-independent or domain-specific. |
| 2) | Note whether the indicator phrase occurred before, after, or in the midst of its key phrase. |
| 3) | Classify the overall structure of indicator and key phrases according to the taxonomy of [9] plus any extensions thought useful1. |
| 4) | Classify the key phrase(s) inside the structure according to the taxonomy plus any useful extensions. |
For example, consider the sentence "Soil N2O emissions were estimated from 25 year-round measurements on differently managed fields". The indicator phrase "were estimated from" was marked and the overall annotation was categorized as a 'Result' structure. The material before the indicator ("Soil N2O emissions") was categorized as a Result span, and the material after the indicator was categorized as a Method span. The results from this initial analysis of the indicator phrases are provided and discussed in section 3.1.
2.2 Reliability of Domain-Independent Indicators (Q2)
Q1 looked at a wide variety of indicator phrases with no limitations on the type of information to be extracted. In Q2 and Q3 we will focus only on the types of information of interest in our initial target applications (shown in Table 3). The indicators were thinned out by eliminating 1) indicators for types other than those in Table 3, 2) any domain-specific indicators, and 3) indicators that were in an "infix" position. After elimination, 121 indicator phrases remained from the original set of 232.
To investigate Q2, a sample of 10,000 abstracts with no particular relation to the original specialties was obtained and loaded into a concordancing tool2. Each of the 121 remaining indicator phrases was analyzed to see: 1) how common they were in the larger sample, 2) how reliable they were as an indicator of the particular types of marker and spans, and 3) whether they could be generalized to include similar cases. For example, an indicator phrase like "is not clear" can be generalized with additional phrases like "is unclear", "remains unclear", "remains uncertain", etc. This generalized indicator can be written as a regexp such as "(is|remains) (unclear|unknown|uncertain)".
The 121 indicator phrases were analyzed as described above and rewritten as regexps. For each candidate regexp, the number of hits in the sample of 10,000 abstracts was recorded. Regexps with few hits were dropped, or merged into another candidate regexp as part of the generalization. For the remaining regexps, the precision of the results, in terms of correctly indicating the type of the key phrase, were estimated from small samples (19 items, corresponding to the first screen of results in the concordancing tool). For example, the regexp "(is|remains) (unclear|unknown|uncertain)" returned 1200 hits. No misclassifications were found in a sample of the first 19 results. Candidate regexps with more than 2 precision errors in the first 19 results were dropped, or checked against a larger sample. This procedure resulted in a set of 10 regexps. Those regexps, and other results from this analysis, are provided and discussed in Section 3.2.
2.3 Automatic Tagging Accuracy (Q3)
The 10 regexps were crafted into a set of rules for JAPE, a pattern-matching language provided in the GATE collection of NLP tools[3]. The JAPE rules were matched against each sentence. Once a rule matched, the rest of the sentence to the left or right of the indicator was marked according to the category of the rule. Only one match was applied per sentence3. A dev set was created by tagging 40 new abstracts with the rules and manually correcting the results. The rules were further adjusted to improve accuracy on the combined training+dev set. At this point, there were 18 rules in the JAPE grammar.
A test set was created by tagging an unseen set of 20 abstracts and manually correcting the tags. The accuracy of the automatic tagging vs. the manually corrected tagging was then measured using GATE's Inter-Annotator Agreement (IAA). Results from this analysis are provided and discussed in Section 3.3.
3. Results
3.1 Analysis of Indicator Phrases
Domain-independent indicators such as "these results show" dominated the indicator phrases marked in the training set. Only 8 of the 232 annotations were domain-specific. Two examples of such domain-specific indicators were 1) the use of "record" as a verb in three geology abstracts, and 2) the use of "was formed" in chemistry and materials, where it could indicate a major achievement for the paper, rather than an intermediate Result as in other domains.
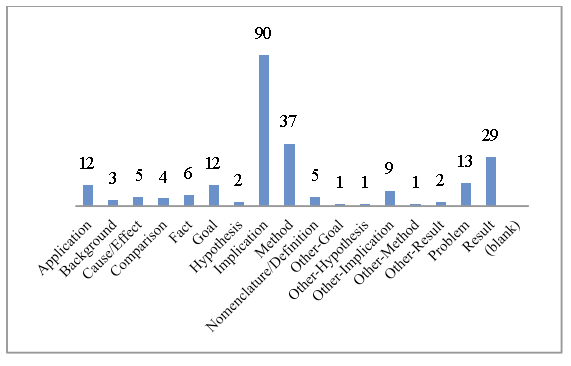
Figure 1: Frequency of Annotation Types
Figure 1 shows the frequencies of the various annotation types used in this portion of the study. Several things are immediately noticeable including the low counts for many of the types. Some indicators did not fit any of the categories from Table 1, leading us to add five new categories: Application, Background, Cause/Effect, Comparison, and Nomenclature/Definition. Only one of those, Application, was used more than a handful of times in the training set. It is also worth noting that Implication was used frequently, but about half of the time the annotation would be better named as Achievement. Detecting Results was difficult as they blended into both the Methods and the Implications. Finally, it should be noted that Geology and Computer Science abstracts in particular were more awkward to categorize. Computer Science abstracts strongly blurred the boundaries between Result, Implication, Fact, and Nomenclature. Some of the geology abstracts studied eschewed the use of stock phrases, thus they did not provide common indicators.
3.2 Frequency and Reliability of Rules
Based on the results discussed in the previous section, we defined a new taxonomy to use, shown in Table 3. The new taxonomy focuses on the types of key phrases that are most applicable to our target applications. Other applications with different purposes would make different choices.
Table 3: Revised Taxonomy of Discourse Types
| Category | Definition | Sample Indicator |
| Achievement | Claimed contribution to knowledge. | "Our results show X" |
| Application | Potential use for techniques described in paper. | "...may be useful in X" |
| Previous Achievement | Achievements in an earlier paper, by these authors or others. | "It has previously been shown that X" |
| Problem | Issue that is not understood. | "X remains unknown" |
Table 4: Frequency and Reliability of Regexps
| Class | Rule | Hits | False Pos. |
| Achv. | (characterize|claim|clear|demonstrat\w+|determin \w+|devis\w+|discover\w*|emerge\w*|establish \w*|expla\w*|find\w*|found|conclude|impl\w+|indicat \w+|predict\w*|present\w*|produce\w*|re port\w*|reveal\w*|show\w*|suggest\w*) that X |
4949 | 2/19 |
| Achv. | (Here(,)?|We)\s X | 4362 | 0/19 |
| Achv. | (Thus|In conclusion|Consequently)(\,)?\s X | 465 | 0/19 |
| Prob. | X (is|are|remains?)( yet| largely| currently)? (unclear|unknown|uncertain|undefined|unexplained)\. |
298 | 0/19 |
| Prob. | X (remains?| is| not| are| poorly)+( \w+){0,2} (clear|understood)\. | 217 | 0*/19 |
| Prob. | ([Ll]ittle|[Ll]ess) is( \w+){0,2} known about X | 78 | 0/19 |
| Prob. | X has( \w+){0,2} un\w+\. | 27 | 0/19 |
| Prev. Achv. | (Recent\w*|Previous\w*|Earl\w*|Prior) (advances?|analys\w+|conference|created|data|developed |discover\w+|estimat\w+|evidence|findings? |innovation|insights?|issue|models?|observ\w+ |paper\w*|propos\w+|reports?|research|show\w* |stud\w+|theory|trials|work|clinical trials)" X |
135 | 0/19 |
| App. | applications (in(cluding)?|to)\s X | 23 | 0/19 |
| App. | (could|might|may|potentially |eventually) be use(d|ful) (in|for|as|to|against) X | 23 | 2/23 |
As described in the Procedure section, a set of 10,000 abstracts was loaded into a concordancer to test the domain-independent patterns for their generalizability, frequency, and reliability. This resulted in the 10 regexps shown in Table 4. The X indicates the position of the key phrase relative to the indicator. All the text between the indicator and the start or end of the sentence will be annotated as the key phrase. Based on these results we believe that domain-independent indicator phrases are, in fact, reliable features for extracting and typing domain-specific information, at least for the set of types shown in Table 3.
3.3 Accuracy of Automatic Tagging
As described in Section 2.3, the 20-item test set was automatically tagged and its accuracy compared to the manual annotations using GATE's IAA tool. The results are shown in Table 5. For comparison, the accuracy reported by [1] using their learning method was F1 = 0.88.
Table 5: Precision, Recall, and F1 for Automated Tagging
| Precision | Recall | F1 | |
| Strict | 0.66 | 0.56 | 0.61 |
| Lenient | 0.82 | 0.69 | 0.75 |
GATE's IAA tool reports two types of numbers, strict and lenient. The strict figures require that the automatically and manually annotated spans have exactly the same starting and ending points. Lenient scores a match if the two spans have any overlap. This raises concern about how permissive such matches are. In these experiments, the length of the key phrases between the manual and automatic annotations never varied by more than two words, and was usually identical. The effect of this difference is to leave some easily-ignored noise on one end or the other of the key phrase. For example, consider the sentence "We carried out a comprehensive search for studies that test the effectiveness of agri-environment schemes in published papers or reports". If the trigger phrase is marked as "We" instead of "We carried out", the effect is that the Achievement in the paper is recorded as "carried out a comprehensive search..." instead of "a comprehensive search...". Either formulation of the key phrase seems acceptable. This kind of effect was common, so the lenient numbers seem closer to the truth than the strict ones.
While the regexp-based method does not give state-of-the-art accuracy, it does surprisingly well for such a simple method. In terms of speed, an unoptimized Perl implementation of the regular expressions tagged all 100 abstracts in ~ 0.9 seconds on a small laptop computer. The method of [1] requires a dependency parse of the text before the indicator phrases can be found. Using an unoptimized configuration of MaltParser4, a very fast dependency parser, and using SENNA5 to perform the Part of Speech tagging needed by MaltParser, takes approximately 17 seconds. We have no estimate for the additional running time of the method from [1]. We assume it is small compared to the preprocessing. Even so, it seem that the simple regexp method has more than a 10x speed advantage.
4. Conclusion
Our results show that it is possible to mine certain types of domain-specific information from abstracts, with reasonable accuracy and at high speed, using an approach based on domain-independent indicator phrases. Most significantly, we have tested the extraction on material from 10 different academic disciplines. We are not aware of other studies that have looked at as broad a range.
This paper reports early results and our experiments have several limitations. First, the size of the test set must be increased to improve confidence in the results. Second, the test data should be made public so others can repeat the results and/or extend the collection6. Third, queries need to be obtained from real experts in all the domains. Fourth, the issue of key phrases running to the ends of sentences instead of being limited in length needs to be investigated. Our initial target application does not display the key phrases to the user, so extra terms may not be objectionable, but their effect on the accuracy of our other processing has yet to be determined. Fifth, the taxonomy of interesting types should be broadened to include methods, and possibly additional types. This may help with the categorization difficulty noted in the results section.
5. Acknowledgements
Many thanks to Anita de Waard and Ellen Hays of Elsevier Labs for discussions on discourse, NLP, and the work described in this paper. Thanks also go to Cell Press and to Dr. Christopher Daniel of Bucknell University for their contributions of expert queries. Finally, thanks to the anonymous referees for their helpful suggestions.
Notes
[n1] It may seem ad-hoc to make additions to the taxonomy in this tagging process. Bear in mind that the point of the Q1 experiment was not to test the taxonomy, but to determine the indicator and key phrases we found in abstracts from multiple disciplines and start to characterize them. The taxonomy was simply the closest starting point we found.
[n2] AntConc 3.2.4, http://www.antlab.sci.waseda.ac.jp/software.html
[n3] Note that these are somewhat different conditions than were applied to the markup in Q1, when the main objective was to learn about indicator phrases. The training, development, and test sets were manually tagged using these new conditions, since in Q3 the main objective is to evaluate accuracy of the tagging.
[n4] MaltParser 1.7.1, http://www.maltparser.org
[n5] SENNA 3.0, http://ronan.collobert.com/senna/
[n6] This was suggested by one of the referees.
6. References
[1] Abdalla, R. and Teufel, S. 2006. A Bootstrapping Approach to Unsupervised Detection of Cue Phrase Variants, In Proceedings of ACL/COLING 2006. Association for Computational Linguistics, Stroudsburg, PA, USA, 921—928.
[2] Blake, C. 2010. Beyond genes, proteins, and abstracts: Identifying scientific claims from full-text biomedical articles, Journal of Biomedical Informatics, Volume 43, Issue 2, April 2010, 173-189, http://dx.doi.org/10.1016/j.jbi.2009.11.001.
[3] Cunningham, H. et al. 2011. Text Processing with GATE (Version 6). University of Sheffield Department of Computer Science. 15 April 2011. ISBN 0956599311.
[4] Myers, G. 1992. 'In this paper we report ...': Speech acts and scientific facts, Journal of Pragmatlcs, 17, 1992, 295—313.
[5] Paice, C. D. 1980. The automatic generation of literature abstracts: an approach based on the identification of self-indicating phrases. In Proceedings of the 3rd annual ACM conference on research and development in information retrieval (SIGIR '80). Butterworth & Co., Kent, UK, 172—191.
[6] Paice, C.D. 1990. Constructing literature abstracts by computer: Techniques and prospects, Information Processing & Management, Volume 26, Issue 1, 1990, 171—186, ISSN 0306-4573, http://dx.doi.org/10.1016/0306-4573(90)90014-S.
[7] Sandor, A. 2007. Modeling metadiscourse conveying the author's rhetorical strategy in biomedical research abstracts. In Revue Française de Linguistique Appliquée 2007/2 Vol. XII, 97—109. http://www.cairn.info/revue-francaise-de-linguistique-appliquee-2007-2-page-97.htm.
[8] Teufel, S. and Moens, M. 2002. Summarizing Scientific Articles: Experiments with Relevance and Rhetorical Status; Computational Linguistics, Vol. 28, No.4, Dec. 2002. 409—445.
[9] de Waard, A. and Pander Maat, H. 2009. Categorizing Epistemic Segment Types in Biology Research Articles. In Linguistic and Psycholinguistic Approaches to Text Structuring, Laure Sarda, Shirley Carter Thomas & Benjamin Fagard (eds), John Benjamins.
About the Author
 |
Ron Daniel, Jr. is a Disruptive Technology Director at Elsevier Labs, where he works on RDF metadata standards, content enhancement methods and workflows, and natural language processing of scientific, technical, and medical content. Before joining Elsevier, Ron worked for eight years as a co-owner of Taxonomy Strategies LLC, a metadata and taxonomy consultancy. Prior to that he worked at Interwoven after it bought Metacode, Inc. for its automatic classification and metadata creation technology. Ron has worked on a number of influential metadata standards. He was an editor of the PRISM metadata standard, worked on the RDF committees, and was a co-editor of the first Dublin Core specification. Ron earned a Ph.D. in Electrical Engineering from Oklahoma State University, and carried out post-doctoral research at Cambridge University's Information Engineering Division and Los Alamos National Laboratory's Advanced Computing Lab. |
|
|
|
| P R I N T E R - F R I E N D L Y F O R M A T | Return to Article |