|
|
|
| P R I N T E R - F R I E N D L Y F O R M A T | Return to Article |
D-Lib Magazine
July/August 2010
Volume 16, Number 7/8
Semantically Enhancing Collections of Library and Non-Library Content
|
James E. Powell |
Linn Marks Collins |
Mark L. B. Martinez |
doi:10.1045/july2010-powell
Abstract
Many digital libraries have not made the transition to semantic digital libraries, and often with good reason. Librarians and information technologists may not yet grasp the value of semantic mappings of bibliographic metadata, they may not have the resources to make the transition and, even if they do, semantic web tools and standards have varied in terms of maturity and performance. Selecting appropriate or reasonable classes and properties from ontologies, linking and augmenting bibliographic metadata as it is mapped to triples, data fusion and re-use, and considerations about what it means to represent this data as a graph, are all challenges librarians and information technologists face as they transition their various collections to the semantic web. This paper presents some lessons we have learned building small, focused semantic digital library collections that combine bibliographic and non-bibliographic data, based on specific topics. The tools map and augment the metadata to produce a collection of triples. We have also developed some prototype tools atop these collections which allow users to explore the content in ways that were either not possible or not easy to do with other library systems.
"Keep an open mind, but not so open that your brain falls out" – Richard P. Feynman
Introduction
Bibliographic metadata is ready to make its debut as a first class object alongside all the other structured information we deal with, if we just give it a little nudge. But we need to rethink how we represent this data, to ensure that it can co-exist with other data. Representing this metadata using semantic web technologies opens the door to opportunities for data fusion: a title for a journal article becomes equivalent to a title for a book, and a subject or keyword associated with a paper may link to an entry in DBpedia. A 2008 report by the U. S. Government's JASON Advisory Group concerned with the problem of analyzing large heterogeneous data sets noted that "the use of web technologies such as Resource Description the Framework (RDF) and XML makes it possible to translate from a number of data sources which can include relational data bases all the way to unstructured text." [1]
Semantic digital libraries are still rare, and the reasons for this include data issues (privacy, intellectual property), lack of motivation (current indexing and discovery viewed as sufficient), lack of expertise, and a lack of adequately scalable repository solutions. Although wholesale conversion of large metadata collections to semantic web data may not be a viable option yet, there's a middle path which may open the door to more advanced user tools while at the same time increasing the relevance of digital libraries. It involves generation of semantically enhanced, focused collections of data. This data is harvested, augmented, mapped to a new format, integrated with other data, and exposed to users in an environment specially designed for information fusion and exploration.
Online search is, as we all know, far from a solved problem. One of Google's primary competitors is a search product called Bing, from Microsoft. In a recent article about Bing's capabilities, a Microsoft executive suggests that they've caught up with Google in terms of search quality. And yet, Google itself acknowledges that "search ... is still an unsolved challenge." [2] Various competitors in this field have, or are currently dabbling in structured browsing (e.g. faceted search), user-contributed tags, and more novel interfaces, such as Google's Wonderwheel. But all the major search engines must balance technical prowess in searching with the need to generate revenue via ads and value-added services from partners. Bing, for example, is developing the capability for "users looking for music [to] stream full versions of songs within the search window with links to buy from iTunes." [3] The ability to download a music video or ensure click-throughs to advertisers may be desirable for Bing, Google, and their respective users, but this capability does little for the advancement of science, or facilitating knowledge discovery in an emergency. Researchers and emergency responders expect tens or hundreds of relevant results, and at times, serendipitous discovery of related content may be just as important as discovering the "right" information.
Discussion
We set out to solve a corner of the search problem that involves fusing bibliographic data with data from other sources. We used an approach that is essentially the strategy described by Hawkins and Wager: "interactive scanning." They suggest that the user starts with a large set of documents generally related to the problem area, retrieved by a few general terms, and then performs additional queries within that collection. [4] We have prototyped tools that generate focused semantic collections from disparate sources including OAI data providers, newsfeeds, and structured metadata results returned in response to broad queries against our own internal collection of 95 million bibliographic records. These collections have high recall with respect to a given query, but may not have high precision. These focused collections, in which all incoming data is normalized as triples, are then presented through a dynamic ajax-driven, skimmable results interface coupled with graph-centric tools, which we call InfoSynth [5]. The remainder of this paper is focused on the methods used for mapping and augmenting data for this environment.
Methods for Mapping and Augmenting Data
The semantic web depends upon simple statements of fact. A statement contains a predicate, which links two nodes: an object and a property. The semantic web allows for the use of numerous sources for predicates. This enables making fine grained-assertions about anything. A set of statements about a thing, represented by a unique URI is a graph. This graph can grow over time without regard to its structure, unlike a relational database which has to have a predefined structure and for which the addition of a new column is nontrivial. But as Feynman noted, it doesn't always pay to be too open-minded. Data fusion and knowledge discovery in the semantic web works best when there is a shared understanding of meaning.
Data fusion is defined by Wikipedia as the "use of techniques that combine data from multiple sources and gather that information in order to achieve inferences, which will be more efficient and potentially more accurate than if they were achieved by means of a single source." [5]
Core components facilitate data integration/data fusion by:
- Converting data elements to triples using a standard set of predicates from a few pre-selected ontologies
- Performing a lossy mapping, so that we only carry over data which we can match in other sources either directly, or through augmentation
- Augmenting data to the extent possible by making implicit relationships among data elements explicit, and by incorporating relevant data from external sources
- Considering relationships that benefit from being represented as graphs
- Exposing the collection for further exploration by users via an end-user interface, graph visualization tools, and web services
Conversion
Much of our source data is bibliographic metadata. Since much of it is harvested from OAI repositories, we use Dublin Core as the anchor ontology for many triples. We map the elements we are interested in from a Dublin Core XML representation to a triple where the record identifier serves as the subject, then various DC elements as predicates, and the textual values for these elements were mapped to objects. We also occasionally "overload" some Dublin Core elements such as title to enhance our ability to combine heterogeneous data. Researchers who have looked at the problem of fusing large data collections have noted that geospatial and temporal data elements work well for exploring and comparing data across a wide range of sources and types [1], so we use predicates from the SWRL temporal ontology for date information. We use properties from the Geonames ontologies to make assertions about places. [6]
As we have gained experience with various data sources, we have recognized the value of incorporating properties from non-obvious ontologies such as the Genealogical ontology Gentology [7] and Friend of a Friend (FOAF) [8]. Finally, we were especially interested in enabling user discovery of key individuals associated with a particular concept, in a particular field, e.g. experts, leaders, or frequent collaborators. The FOAF ontology turns out to be quite useful for representing co-authorship, though we also use the Dublin Core creator and contributor elements. We employ some basic name matching heuristics to attempt to determine if two name variants actually represent the same author, and we assume that the order of names in a record is significant to the degree that the first author of an item occurs first in the metadata record. This allows us to place the first author at the center of a co-authorship graph for that object, and to place the first author first in an rdfs:bag list of authors, though we make no further assumptions about the significance of the ordering of author names beyond first author.
In all, we use about 25 properties and classes from a dozen ontologies (some of which are noted in Figures 1 and 2) in our mapping of disparate data sources into instance data serialized as RDF/XML, and loaded into Sesame semantic repositories manually, and via the openRDF API [7].
Lossy mapping
What data actually exists consistently across the original sets of data which we intend to merge and explore? On the one hand, MARC XML carries a tremendous amount of data, and there are many elements that have no counter part in Dublin Core's original 15 elements. On the other, formats such as RSS contain just a few pieces of information about the the list of items they describe. Our answer to this question continues to evolve. At a minimum, we need an identifier to form the basis of any triples about an object (and to link back to the object in some way), a title for the object, and at least one individual responsible for the creation of the object. Maintaining only data which can usually be matched with data from other sources also reduces the number of triples we generate, which results in a more manageable collection.
Data Augmentation
Augmentation is an interesting problem, and a risky proposition. We don't want to add data that isn't appropriate, but we knew that we could leverage some web services and the Linked Data Web to enhance our data. We use the following services:
- OpenCalais
- Geonames
- Google Translate
- DBpedia
Reuter's OpenCalais [10] service offers some interesting opportunities for augmenting data. We elected to submit a request that included an object's title and abstract content. Calais responded with a semantic analysis of the submitted text. If Calais detects place names in the text, it not only notes this in its response, but also supplies geocoordinates for the identified place names. Use of Calais greatly enhances our ability to geocode the data, regardless of its original source format, and to subsequently allow users to explore a greater portion of the resulting focused semantic collection via its geospatial characteristics. Calais returns references to linked data in response to a request, for which we are actively exploring potential uses, but since it is primarily a business-oriented solution, it does not provide much in the way of author data or general subject information.
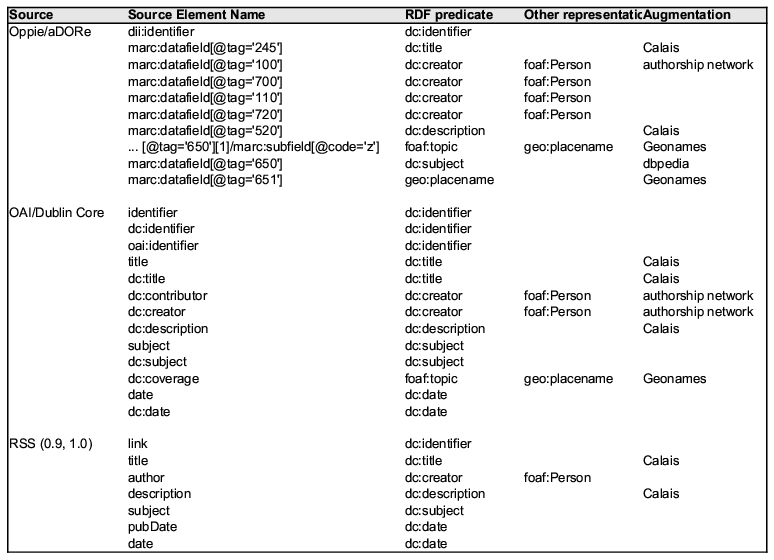
Figure 1. Mappings table
Geonames enables us to associate coordinates with place names. MARC XML records may occasionally include explicit fields such as the MARC 651 subfield a, which indicates a physical place name associated with the content described by the record. Other data sources included specific XML elements for place, such as country, city or state. Once we had a place name, we needed to geocode it in order to allow users to explore it in a geospatial context. For each place name, we call the Geonames place name lookup service [6], and then incorporate the longitude and latitude into a set of triples that associate the place with the object being described.
Some of our sources are non-English, and use non-Western character sets. We use Google's translation service, Google Translate [11], to generate translations of some content so that users who don't speak the language used in the original content can still review it alongside other information.
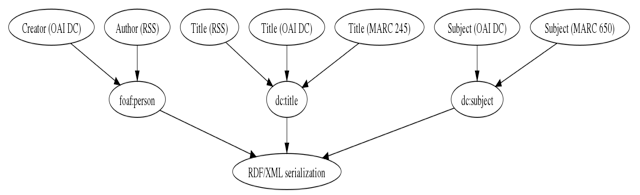
Figure 2. Example of metadata elements mapped to corresponding predicates
We developed a simple mechanism for associating subjects and keywords with resource pages in DBpedia, [12] turning matches into linked data elements, an approach consistent with other linked data discovery projects such as LODr [13, 14]. We convert the subject text into the format typical of a DBpedia resource page URI (e.g. for Russian language, the corresponding DBpedia URI is http://dbpedia.org/page/Russian_language) and check to see if that page exists. If it does, we store the URI. If there's a redirect, we store the URI to which we were redirected. If there is no page found, then we store the original subject text, and no URI.
Graph considerations
What are the aspects of the data that are important to our users, and which lend themselves to network centrality measures and graph visualizations? Connections are key to answering this question. If the presence or absence of one type of connection that is possible between nodes is significant to a user, then a graph of this relationship among nodes is likely to reveal information to a user. For example, a co-authorship graph where the node representing a particular author is connected to many other nodes and clusters of nodes, likely represents an expert (or at least a prolific author) for a given topic.
A graph of this relationship, representing a large number of nodes, can be enhanced by using centrality measures to highlight nodes with high degree centrality (lots of connected nodes), or high betweenness centrality (connecting clusters of nodes), to name two. Such relationships are virtually impossible to discern from a textual listing of a result set. It is also necessary to give some thought to the significance of a particular centrality measure, when applied to a particular graph, and how to convey that to users. Degree centrality is likely to be of interest regardless of the relationship it describes, but a node with high degree centrality in a co-authorship graph means something dramatically different than, for example, a node in a graph showing the relationship among proteins in support of cellular functions in a living organism. The former may tell you who writes frequently about a given topic (centrality = expert) and the latter may help you identify a protein that you can or cannot safely suppress in a drug to treat cancer (centrality = lethality [15]). All you can say with certainty when comparing these is that they are both important in their respective domains.
With a social network, if a user has the ability to perform queries against the original metadata - for example against the title and descriptions within this metadata - then it becomes possible to generate a social co-authorship network that is constrained by that criteria, which lends itself to exploration via graph centrality measures. This type of analysis is normally beyond the reach of most users, but mapping metadata to a graph model makes it possible to expose constrained subgraph views and apply meaningful centrality measures on the fly to those graphs, thus opening up a whole new method for exploring the metadata. It may be possible to add a capability that would allow users to supply parameters for weighting relationships that might yield additional insights. This would be similar to the user having their own personal, configurable version of Google's PageRank [16] algorithm at their disposal.
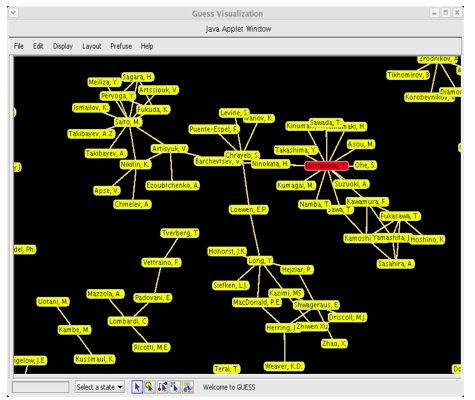
Figure 3. Example of a co-authorship graph with high betweenness centrality node highlighted
Summary
Our primary goal was to integrate digital library content with data from disparate sources, which may have originally existed in different formats. A secondary goal was to enable users to explore these moderately large collections effectively, using semantic web technologies and graph theory. A Google or Bing search might return a million results, but users rarely explore beyond the first page or two. Indeed, Google itself acknowledges that some result set variants are essentially designed to provide the user with a hint as to what types of content exist, with the hope that users will refine their search by adding additional words that might occur in the title or body of documents they've indexed, be part of a person or corporate name, or otherwise increase the specificity of the search. Our goal is to provide a set of a few hundred to a few thousand records, preselected based on their relationship to a topic of interest to the intended users, and then provide more sophisticated tools with which users can explore large portions, if not all, of the results at a time.
We have developed mapping tools that map and augment content in MARC XML format, and OAI Dublin Core content from OAI repositories, RSS and Atom news feed content, and we also have custom tools for processing structured (XML) content, and data from relational databases. The XML and database mapping tools currently must be adapted for each new data source, so they represent one of the more brittle, and labor-intensive aspects of the technologies.
Users can export files representing these graphs via web services. Supported formats include Pajek's net format, GraphViz's DOT formation, the Guess data format, and GraphML. This enables more sophisticated users to use other graph visualization tools for exploring the data, or to merge data from multiple sources.
Restricting ourselves to a handful of ontologies by no means limits us in the future. The semantic web allows us to add new triples, using new predicates, whenever the need arises. There is no database schema to update, and the SPARQL query language is forgiving enough to allow changes to the underlying data, with minimal or no changes necessary for queries to continue to work against old and new data.
There are often many ways to express the same idea, and it takes time and energy to select a particular way to express an assertion about an object (formulate a triple), and even more effort to design your own method for expressing concepts in a specific domain (design an ontology). Dublin Core may have opened the door to an "everything is optional" approach to metadata, but the semantic web has taken this approach to a whole new level.
References
[1] JASON. Data Analysis Challenges. The MITRE Corporation. December 2008. http://www.fas.org/irp/agency/dod/jason/data.pdf
[2] Sullivan, Danny. "Up close with Google Search Options." http://searchengineland.com/up-close-with-google-search-options-26985.
[3] "Bing executive: 'We have caught up' to Google in search quality" http://latimesblogs.latimes.com/technology/2010/06/bing-vs-google.html
[4] Hawkins, Donald T. and Wagers, Robert (1982). "Online Bibliographic Search Strategy Development.". Online. v6 n3 p12-19 May 1982
[5] Wikipedia: http://en.wikipedia.org/wiki/Data_fusion
[6] Geonames: http://www.geonames.org/
[7] SGentology: http://orlando.drc.com/SemanticWeb/daml/Ontology/Genealogy/ver/0.3.6/Gentology-ont
[8] FOAF: http://www.foaf-project.org/
[9] openRDF: http://www.openrdf.org/
[10] OpenCalais: http://www.opencalais.com/
[11] Google Translate: http://translate.google.com/#
[12] DBpedia: http://dbpedia.org/About
[13] LODr: http://lodr.info/
[14] Passant, Alexandre. LODr: A Linkining Open Data Tagging System. http://ceur-ws.org/Vol-405/paper2.pdf
[15] Jeong, H., Mason, S.P., Barabasi, A.L., "Lethality and centrality in protein netowrks." Nature 411, 41-42 (2001). doi:10.1038/35075138
[16] Levy, Steven. "How Google's Algorithm Rules the Web." Wired. March 2010. http://www.wired.com/magazine/2010/02/ff_google_algorithm/all/1
About the Authors
 |
James E. Powell is a Research Technologist at the Research Library of Los Alamos National Laboratory, and a member of the Knowledge Systems and Human Factors Team where he develops digital library, semantic web, and ubiquitous computing tools to support various initiatives. He has worked in libraries off and on for over 20 years, including eight years at Virginia Tech University Libraries, where he worked on the Scholarly Communications project and participated in several collaborations between the library and the Computer Science department's digital library group. He later went on to assume the position of Director of Web Application Research and Development at Virginia Tech, and to lead the Internet Application Development group, before joining LANL. |
 |
Linn Marks Collins is a Technical Project Manager at the Los Alamos National Laboratory, where she leads the Knowledge Systems and Human Factors Team at the Research Library. Her team focuses on applying semantic web and social web technologies to challenges in national security, including situational awareness, nonproliferation, and energy security. She received a doctorate in educational technology from Columbia University in New York, where her dissertation was on semantic macrostructures and human-computer interaction. Prior to LANL she worked at IBM Research on Eduport and the Knowledge and Collaboration Machine, and at the Massachusetts Institute of Technology on Project Athena. |
 |
Mark L. B. Martinez received a BA from Harvard College eons ago and more recently, a BS in Computer Science from the University of New Mexico. He is a R&D Engineer supporting the Research Library at Los Alamos National Laboratory. Along with traditional library services, Research Library staff investigate tools and technology for delivering knowledge services, scientific collaboration, and connecting LANL researchers with the information they need. |
|
|
|
| P R I N T E R - F R I E N D L Y F O R M A T | Return to Article |