Caching for Large Scale Systems
Lessons from the WWW
Robert E. McGrath
Computing and Communications Group
National Center for Supercomputing Applications
University of Illinois, Urbana-Champaign
[email protected]
D-Lib Magazine, January 1996
Robert E. McGrath
Computing and Communications Group
National Center for Supercomputing Applications
University of Illinois, Urbana-Champaign
[email protected]
D-Lib Magazine, January 1996
A key to performance in any distributed system is effective caching, transparently replicating and locating information for faster access. The development of large scale digital libraries will need effective information caching, not only for quick access, but to conserve network bandwidth and reduce the load on servers. This article examines the state of caching for the WWW, and draws inferences about the problems digital libraries will face, and what directions may be followed.
Large scale digital libraries will make huge collections available to thousands of people over wide geographical distances using wide area computer networks, and will be some of the largest distributed systems yet built. The realization of this dream will require solutions to the problems of creating and managing huge digital collections and indexes, containing a great variety of digital information. To accomplish this, the problems common to all large distributed systems problems, particularly, the secure and efficient use of networks, will have to be solved.
In a widely distributed system, the key to good performance is effective caching: information should be transparently replicated or relocated to be ``near'' the point of access at the time of access. The goals of caching are to:
Users directly benefit from faster and more reliable access to information. Service providers and the whole user community benefit by the conservation of expensive network and server resources.
In order to grasp the problem of caching for large scale digital libraries, let's examine the largest information system available today, the World Wide Web. Current Internet services such as the WWW have rudimentary caching. Web browsers and servers implement some types of caching, and Web proxy servers can be configured to act as shared caches for departments, campuses, or organizations. Let's briefly examine these types of caching, and how effective they are.
Most Web browsers save recently loaded documents and images in local storage. When an object is first requested it is retrieved from the server and saved in the cache. Subsequent visits to the object, through a new link or following the history (e.g., via a ``back'' button) will use the cached copy rather than retrieving it from the originating server. This cache can be very effective, especially for the small icons and images commonly used in Web documents. However, caching by the client uses up substantial resources on the client computer, and since the caches are not shared each browser session may have its own cache. The same object may well be cached many times, with each copy used by only a few people--this is not an optimal use of storage or networks.
Web servers also use caching of various types. For example, some servers cache frequently requested objects in memory for a much faster response. However, it is very important to realize that, no matter how efficient the Web server may be, clients must still access it across the Internet, and the delay and cost of the network traffic will often dominate all other costs of accessing the information on the server.
A popular alternative is to use an intermediary, or proxy server. A caching proxy server is located between the client and the server and transparently mediates all requests for Web objects. Caching proxy servers are typically located ``near'' the client systems, on department or campus servers (Figure 1). Web browsers are configured to send Web requests to the appropriate local proxy server. When an object is first requested, the proxy server acts as a Web client to retrieve the object and returning it to the client. The object is saved by the proxy server, and if another client requests the same object, the proxy acts as a server and returns the cached copy.
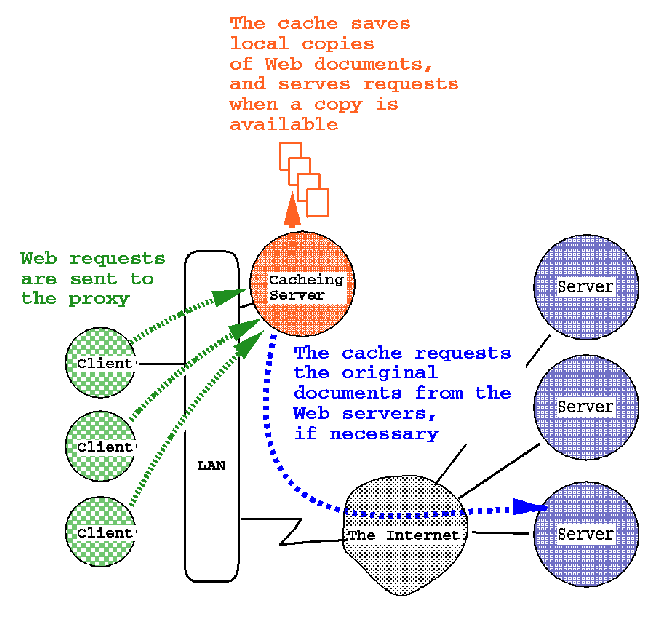
Figure 1. Diagram of a caching proxy server.
When a document is available in the cache, the response is likely to be much faster than accessing the originating server. In addition, if many requests are successfully served by the cache, the load on networks and servers is greatly reduced. Since the proxy server is shared by many users, greater savings are possible as a popular document need only be retrieved once no matter how many times it is subsequently used.
The caching proxy must deal with two difficult issues: What should be cached? and How can the information in the cache be kept up to date? What types of information should be cached may be subject to policy decisions. For instance, information from local servers might not be worth caching. Or, some rarely used and extremely large items, such as MPEG movies, might be excluded from a cache in order to conserve storage space.
When an original document is modified or deleted, how can the
cache know that its copy is obsolete? The HTTP protocol provides
rudimentary support to allow caches to inquire if the document
has changed, or to conditionally fetch it if the cached copy is
out of date. Caches may use the HEAD method to fetch the headers
for an object to see if it has been modified since the copy of
it was cached. Alternatively, the cache server can use the GET
method with the optional header If-modified-since:.
This will retrieve the document only if it is newer than the specified
date. These inquiries create nearly the same load on networks
and servers as retrieving the whole document would, so it is infeasible
to check every time the document is requested.
The HTTP protocol provides that servers may optionally specify the ``time to live'' for a document, explicitly indicating how long the document will remain valid. An immediate expiration date effectively means ``don't cache this.'' Few Web servers implement a formal publishing mechanism, though, so they are not able send an accurate expiration time.
Web caches usually apply heuristics, reusing a cached copy for a time before refreshing it. The retention time may be fixed or may be calculated based on the size, age, source, or content type of the document. These methods are imperfect. If the document changes before the expiration of the cached copy the users will receive out of date information until the cache is refreshed. Thus, for documents that change frequently, it may be difficult to effectively cache them. On the other hand, if the document never changes, it is wasteful to repeatedly check it.
This is the best that can be done with the current protocols. Web caches and servers operate independently, and the server is unaware of where information is cached. For that matter, many Web servers are unaware when the information they serve changes. And even if the Web server knows the document has changed, and knows it as been cached, there is no protocol for servers to notify caches to discard or refresh the information.
Web caching is usually a relatively simple ``flat'' scheme, consisting of a single cache between the client and the servers of the Web. (Figure 2) If the document is not in the cache, it is fetched from the original source. Each cache is independent, and the caches do not cooperate with each other or with the Web servers. This design is simple, organizations can deploy a caching proxy or not, as they wish. But the independent caches are duplicating each other's efforts, fetching and caching documents that are already available in other nearby caches. This duplication causes unnecessary network traffic and wastes storage space in the caches. Furthermore, it is difficult to keep the documents in the caches up to date when necessary, unless the caches cooperate with the Web servers. As the number of people using the Web grows and the load on networks and servers increases greatly, the need for better caching will become more urgent.[6]
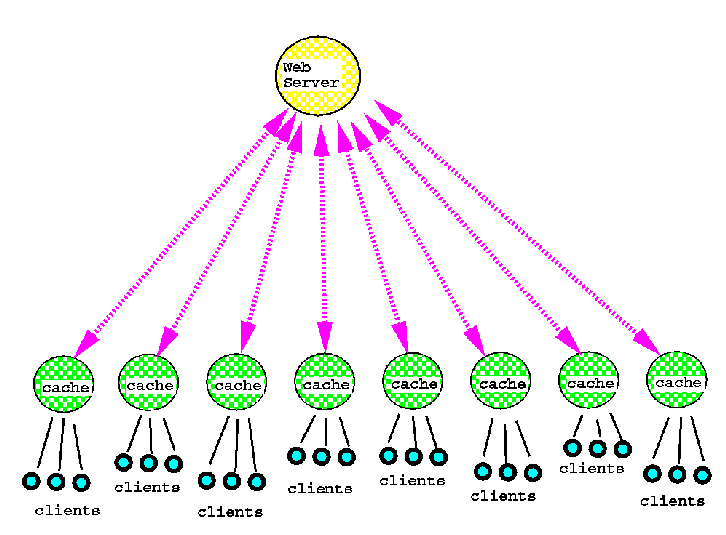
Figure 2. A ``flat'' caching architecture.
One possible improvement is the use of hierarchies of caches. In addition to the local cache, there can be ``regional'' caches, holding information for a cluster of networks. Figure 3 shows how this might work. When a document is not found in a local cache, the caching server will check with the regional cache(s), which may check with other ``supercaches'', connecting to the originating Web server only as the last resort. From the point of view of the server the essential difference is each server and cache serves a relatively small number of ``children'' and caches data from a small number of ``parents''.
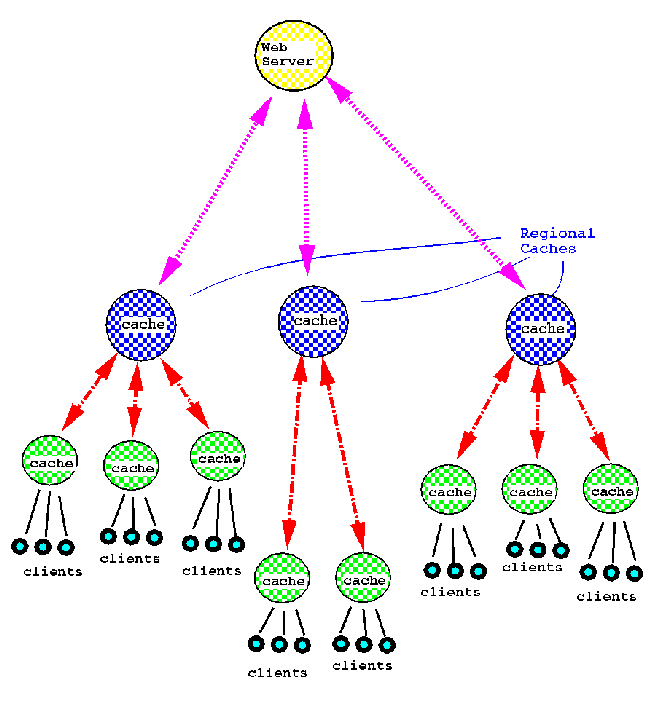
Figure 3. A hierarchical caching architecture.
Using a hierarchy may have important technical and economic advantages. A large regional cache will serve many more users and have many more hits than a local cache. Strategically placed, these regional caches can have a very large storage capacity and high-speed network links, so accessing them should be almost as fast as a local network. The regional caches might also serve as distribution points where publishers automatically deposit information.
One way to set up a hierarchy of caches is to extend the simple flat caching scheme to have each cache configured to know where to look for documents it lacks. The hierarchy could be constructed from simple caching proxy servers, such as the CERN caching proxy.[5] This hierarchy is relatively easy to set up, but has limitations. The caches in the hierarchy use HTTP to fetch and save documents as they are requested but they do not collaborate. The hierarchy itself is constructed ad hoc by the caching server administrators: the caching servers are manually configured with the sequence of where to look for documents and in what order.
In such a hierarchy of independent caches, the different caching servers may each have a copy, and possibly different copies, of the same original document. The information provider has no way to guarantee the users will get the current version, nor any way to even know where copies are cached, or what version a user might be receiving. Thus, the problems of maintaining cache consistency are greater in the hierarchy, mainly because the Web servers and caches do not communicate with each other to keep the information up to date.
The experimental Harvest system provided answers to many of these issues.[2,3] Harvest provides a hierarchy of caching servers which can be accessed by Web browsers. The local Harvest object cache is used by Web browsers just as other caching servers, but they have several advanced features that make them far more effective than simple proxy servers. The Harvest caching servers can store information from many sources, including the WWW, and are integrated with the Harvest indexing and searching mechanisms. The caches communicate with each other and transfer data using their own protocol, which is more efficient and flexible than using HTTP.
While the potential advantages of schemes like Harvest are great, they also face problems. Cooperation among caches and servers requires standardization of protocols and coordination among diverse administrative domains. It is easy for an organization to set up its own caching server on its own network, but it is much more difficult to set up a regional caching server, to serve many different networks and organizations. Who will run the regional and national caching servers? How will they be funded? These questions must be answered before hierarchical caching can be widely implemented.
The diversity of information available on the Internet poses a serious challenge to any caching scheme. The output of scripts and other dynamic documents cannot be cached at all, since the result will be different each time. This is very unfortunate, as many of the most interesting uses of the Web are scripts, gateways, and dynamic documents. Future developments such as Java[9] and VRML [8] may create new ways for dynamic documents to be implemented, but even should they turn out to be widely adopted, there will still be many dynamic resources on the Internet that will reduce the effectiveness of caches.
Another challenge for caches is what to do about restricted information. Caching documents may create problems for information providers who wish to control the distribution of their documents according to security policies or to preserve rights. It is not clear how to implement caches for such information. The problem is that the access controls are imposed by the originating servers, that is, by the information provider. In general, a caching server is neither authorized nor able to enforce such restrictions. Confidential or proprietary information should be stored only by authorized parties, and a caching server should not store restricted information unless specifically authorized to do so. In the case of for-a-fee services, the information provider usually does not want the information paid for once, and then cached for many subsequent users! If each user must contact the originating server to arrange authorization or payment, much, if not all, of the benefit of the cache is lost.
The uniform enforcement of access controls is a crucial problem for digital libraries, which seek to make information widely available while preserving copyrights and licenses. A new infrastructure for rights preservation will be needed.[4]
Digital libraries can implement software ``wrappers'' (also know as ``middleware'') to allow diverse systems to interoperate. For example, the Stanford Digital Library project is creating a software ``virtual bus'' which seamlessly connects a variety of online services.[7] The Stanford software provides protocols that support the caching of many types of information, including documents, result sets, search histories, and queries.
Digital libraries may also use ``software agents'', autonomous programs capable of negotiating complex access methods and terms. For instance, the University of Michigan Digital Library project is exploring a complex architecture of collaborating agents, capable of customized searching of many repositories.[1]
Agent technology is notable for the fact that it can move the computation to the information, making searches much more efficient, and returning only the results desired. This might seem to make caches unnecessary, but even with fully mobile agents, caching will be needed--if only to support the activity of all the agents. Fortunately, agents are extremely flexible, and should be able seek out caches of needed information. In fact, agents are ideal for creating extremely effective caching, as they can negotiate the best combination of where to locate the information and the computation.
Caching has not been a prominent feature of digital library projects to date, but it will surely be important behind the scenes. Digital library projects are creating technology that will make it possible to have very flexible and effective caching, which will be much more effective than is now possible with the Web. The large scale digital libraries of the future will almost certainly have cooperating caches as part of the infrastructure at many levels.
Robert E. McGrath is the coauthor (with Nancy Yeager) of the new book, Web Server Technology: Inside the World Wide Web, to be published by Morgan Kaufmann Publishers in early 1996.
1. Birmingham, W.P., ``An Agent-Based Architecture for Digital
Libraries,'' D-Lib Magazine, July, 1995.
[URL:http://www.dlib.org/dlib/July95/07birmingham.html]
2. C. Mic Bowman, Peter B. Danzig, Darren R. Hardy, Udi Manber,
and Michael F. Schwartz. ``The Harvest Information Discover and
access system.''
3. Anawat Chankhunthod, Peter B. Danzig, Chuck Neerdaels, Michael
F. Schwartz, Kurt J. Worrell, ``A Hierarchical Internet Object
Cache'', Technical Report CU-CS-766-95, Department of Computer
Science, University of Colorado, Boulder, Co, March, 1995.
5. Carl Lagoze ``A Secure Repository Design for Digital Libraries''
D-Lib Magazine, December 1995.
5. Ari Luotonen and Kevin Altis, ``World-Wide Web Proxies'', Proceedings
of the First International WWW Conference, 1994.
6. National Laboratory for Applied Network Research (NLANR), ``A
distributed testbed for national information provisioning'', 1995.
7. Andreas Paepcke, Steve B. Cousins, Hector Garcia-Molina, Scott
W. Hassan, Steven K. Ketchpel, Martin Roscheisen, and Terry Winograd,
``Towards Interoperability in Digital Libraries: Overview and
Selected Highlights of the Stanford Digital Library Project'',
Working document, 1995.
8. Mark Pesce, VRML: Browsing and Building Cyberspace,
New Riders, Indianapolis, IN, 1995.
9. Sun Microsystems, ``Java Home Page'', 1995.
hdl://cnri.dlib/january96-mcgrath
[URL:http://www.ncsa.uiuc.edu/SDG/IT94/Proceedings/Searching/schwartz.harvest/schwartz.harvest.html]
[URL:ftp://ftp.cs.colorado.edu/pub/cs/techreports/schwartz/HarvestCache.ps.Z]
[URL:http://www.dlib.org/dlib/december95/12lagoze.html]
[URL:http://www1.cern.ch/PapersWWW94/luotonen.ps]
[URL:http://www.nlanr.net/Cache/]
[URL:http://www-diglib.stanford.edu/cgi-bin/WP/get/SIDL-WP-1995-0013]
[URL:http://java.sun.com/]