|
|
|
| P R I N T E R - F R I E N D L Y F O R M A T | Return to Article |
D-Lib Magazine
January/February 2014
Volume 20, Number 1/2
Synthesis of Working Group and Interest Group Activity One Year into the Research Data Alliance
Beth Plale
Indiana University
plale@indiana.edu
doi:10.1045/january2014-plale
Abstract
The Research Data Alliance (RDA) uses Working Groups and Interest Groups to carry out its work. Groups form when a concerned community develops around a topic for which there are well defined issues, common goals, and an opportunity to create a framework for timely action. One year in, RDA has 26 Working Groups and Interest Groups whose activities are focused on overcoming barriers to successful research data sharing, publishing, referencing and archiving, and on developing the infrastructure necessary to support those tasks.
Introduction
The work of the Research Data Alliance is carried out in its Working Groups and Interest Groups, two types of groups that together accommodate both development of community around a subject, and rapid progress on well defined issues. Working Group (WG) and Interest Group (IG) topics often emerge organically from within the RDA community. A Working Group poses a new problem area by means of a written case statement. RDA then works with the WG to ensure that its outcomes can be delivered within a 12-18 month time frame and can be actionable, two key RDA criteria for maximum potential impact. IGs are often convened to allow communities time to coalesce around short-term WG objectives. The Technical Advisory Board (TAB) works on behalf of the RDA community to facilitate WG and IG success, define a technical roadmap for RDA, and identify and address gaps. One year in, the Research Data Alliance has 26 Working Groups and Interest Groups, all of which have formed organically.
Focus Areas
Current activity of the RDA WGs and IGs can be categorized into the following five areas, reflecting just a snapshot in activity of this rapidly moving organization that sees new groups emerging all the time.
Science Domain
Engagement of RDA community members around a science domain tends to be directed at overcoming technical and social barriers to data sharing within a fairly narrow discipline. This is accomplished through shared data models, in the case of structural biology; shared vocabularies or taxonomies; or joint cross-border agreements in the case of materials data management. As shown in the accompanying figure, present effort is concentrated in four areas: biology (including toxicogenomics, structural biology, and biodiversity), agriculture, social science (specifically, digital history and ethnography), and engineering (specifically materials science).
Data Archiving and Publishing
This area currently has five groups addressing key issues facing repositories/archives as they expand their data holdings. The groups generally are striving towards shared approaches, shared tools, and with an eye towards reduced operational costs. Specific activity includes common ways to represent data provenance through the data lifecycle; open, cost-effective, and shared standards for certifying repositories of data; bibliometrics; serving the needs of the long tail of research; and getting a better handle on the costs of data publishing.
Data Sharing and Reuse Needs in Research and Education
A set of groups are using targeted approaches to better capture the needs of communities of research data users. This is through profiles, and through targeted efforts such as a focus on educational materials in cloud computing for developing countries.
Data Referencing
There are barriers at numerous levels to global data sharing when the objective is reuse of research data. The three groups in this area examine different barriers. Data that is cited in a publication can be part of a larger and time-indistinct whole as in the case of time series data. Citing subsets of this data should be done in an agreed upon manner, and a group in RDA is attempting to forge agreement. Digital data objects are expressed in any number of human-spoken languages. Having a single coding for human-spoken language facilities interpretation of objects. Finally, data sharing across borders encounters numerous legal barriers that are the subject of a joint RDA/CODATA group.
Infrastructure
Infrastructure, the largest of the areas with eight WGs and IGs, is divided into concrete and elaborative categories where the former have outcomes that are demonstrated through service-level running code and the latter are architectural in nature. Current activity in the concrete category includes:
- A reference data model and attendant vocabulary that are together a foundational need for building tools for interoperability,
- Shared actionable policies for repository management, that once identified, can simplify certification and enhance transparency of repositories and archives
- A directory of metadata standards, and
- A data type registry.
The latter two together help in the interpretation of data objects once they are discovered. The elaborative group in Big Data Analytics is, for instance, building off of the NIST Big Data Public Working Group. Federated Identity Management is looking at advancing international federation of identity.
Relevant Activities
The five broad categories convey the state of activity of RDA after its first year of existence. These areas and their relevant activity are shown in the figure below.
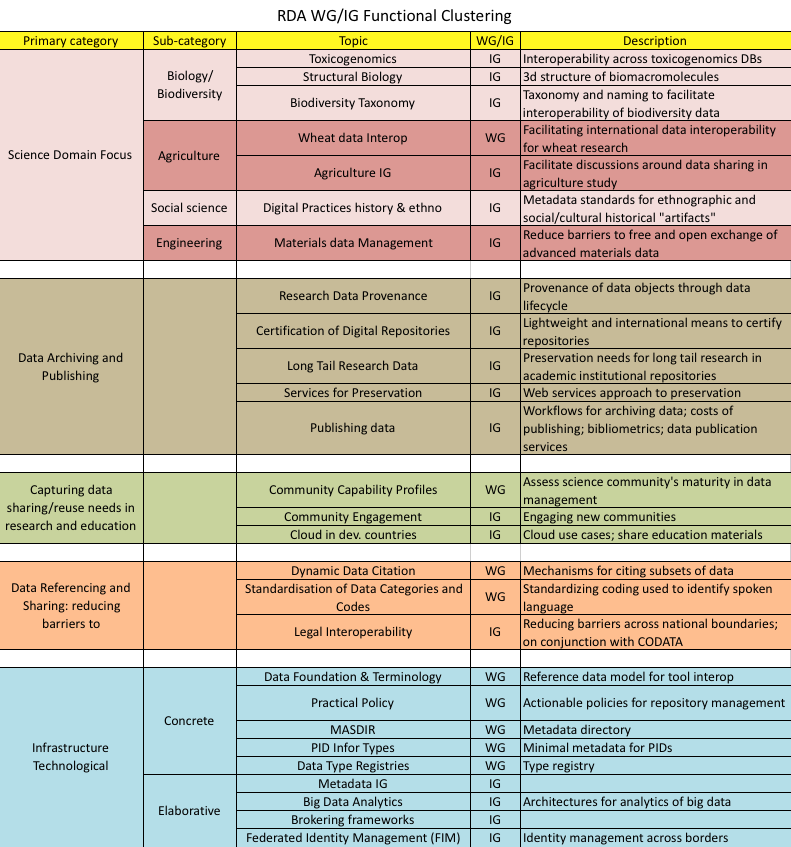
Figure 1: Areas of Activity
The group makeup is expected to change over time as certain hurdles to research data sharing are reduced and new ones emerge. New areas such as educating the data science workforce or facilitating specific cross-domain, cross national interoperability are just a couple areas expected to emerge as important in the future of RDA.
Acknowledgements
The author thanks members of the RDA Technical Advisory Board for discussion and suggestions on this article, in particular Peter Wittenburg of Max Planck Institute of Psycholinguistics, Andrew Treloar of Australian National Data Service, and Ranier Stotzka of Karlsruhe Institute of Technology.
About the Author
 |
Beth Plale is Director of the Data to Insight Center and Professor of Informatics and Computing at Indiana University. Professor Plale has broad research and governance interest in long term preservation and access to scientific data, and enabling computational access to large-scale data for broader groups of researchers. Her specific research interests are in tools for metadata and provenance capture, data repositories, cyberinfrastructure for large-scale data analysis, and workflow systems. She is deeply engaged in interdisciplinary research and education particularly in the geosciences, and has substantive experience in developing stable and useable scientific cyberinfrastructure. Professor Plale is Research Data Alliance-US Technology Co-Chair and co-Chair of the RDA Technical Advisory Board. She is Co-PI on the NSF DataNet funded Sustainable Environments-Actionable Data (SEAD) project, and Co-Director of the HathiTrust Research Center. Professor Plale can be contacted via: @bplale, www.linkedin.com/in/bethplale, and www.cs.indiana.edu/~plale. |
|
|
|
| P R I N T E R - F R I E N D L Y F O R M A T | Return to Article |