|
|
|
| P R I N T E R - F R I E N D L Y F O R M A T | Return to Article |
D-Lib Magazine
January/February 2011
Volume 17, Number 1/2
Quality of Research Data, an Operational Approach
Leo Waaijers
leowaa@xs4all.nl
Maurits van der Graaf
Pleiade Management and Consultancy
m.vdgraaf@pleiade.nl
doi:10.1045/january2011-waaijers
Abstract
This article reports on a study, commissioned by SURFfoundation, investigating the operational aspects of the concept of quality for the various phases in the life cycle of research data: production, management, and use/re-use. Potential recommendations for quality improvement were derived from interviews and a study of the literature. These recommendations were tested via a national academic survey of three disciplinary domains as designated by the European Science Foundation: Physical Sciences and Engineering, Social Sciences and Humanities, and Life Sciences. The "popularity" of each recommendation was determined by comparing its perceived importance against the objections to it. On this basis, it was possible to draw up generic and discipline-specific recommendations for both the dos and the don'ts.
Introduction
Scientific and scholarly research nowadays results not only in publications but increasingly also in research data, i.e. collections comprising the data on which the research is based but which comes to live a life of its own — subsequently or parallel to the actual publications — as an independent source of information and analysis for further research: the "Fourth Paradigm of Science". For this to be possible, such collections of data need to be traceable and accessible in just the same way as actual publications. Quality also plays a major role in both types of research product. But whereas for publications this aspect has been operationalised — not always without controversy — via peer review and citation indices, it is still in its infancy as regards research data.
SURFfoundation — the ICT partnership between the Dutch Higher Education institutions — is following these developments closely and in 2010 devoted three studies to the topics of selection, organisation, and quality of research data. The third of these studies was carried out by Pleiade Management and Consultancy (Maurits van de Graaf) and Leo Waaijers (Open Access consultant). The present article is based on the results of that study.
Summary
The study investigated the operational aspects of the concept of quality for the various phases in the life cycle of research data: production, management, and use/re-use. Nine potential recommendations for quality improvement were derived from interviews and a study of the literature. The desirability and feasibility of these recommendations were tested by means of a national survey of university professors and senior lecturers, with a distinction being made in this regard between the three disciplinary domains applied by the European Science Foundation: Physical Sciences and Engineering, Social Sciences and Humanities, and Life Sciences. The "popularity" of each recommendation was determined by setting off its perceived importance against the objections to it. On this basis, it was possible to draw up generic and discipline-specific recommendations for both the dos and the don'ts.
Survey of the literature
Literature dealing with the quality of research data is a recent development but is rapidly increasing in volume. The importance of the quality aspect of research data is broadly recognised. This virtually always concerns the quality of the metadata and documentation, but sometimes also the quality of the actual data itself. No generic definition of the term "quality" could be identified. In general, further study is recommended; this matter is still in the pioneering phase. (For examples, see [3] and [9].)
One important milestone was the 2007 OECD publication Principles and Guidelines for Access to Research Data from Public Funding [15], which adopts the basic principle that such data is a public good which must be made as accessible as possible. Our study makes a number of comments on this, particularly where data from the life sciences is concerned.
The RIN report [12] takes the first step towards operationalising the quality aspect by linking it to the various phases in the life cycle of research data: production, management, and use/re-use. This tripartite categorisation is frequently followed in subsequent literature, for example in the present study.
A new milestone is the recent report by the High Level Expert Group on Scientific Data, which develops an impressive vision regarding the issue of "how Europe can gain from the rising tide of scientific data" [1]. The report includes a plea for the development of methods for measuring the impact and quality of datasets and for the production and publication of high-quality datasets to be made relevant to the career development of scientists/scholars. Our recommendations would operationalise that plea.
Some specific findings include:
- The publication by Marc van Opijnen [5] focuses on the structuring of information (in the legal field) and creates a link between the topic of our study (the quality of research data) and a central theme of the SURFshare programme (enhanced publications), concluding that it is not technology that is the main challenge but scientific/scholarly professionalism.
- The dissertation by Jinfang Niu [6] gives a lengthy analysis of the importance of good documentation for the re-use of research data in the social sciences.
- The Interim Business Plan 2008/9 by Australian National Data Services (ANDS) [10] announces that an annotation service will be set up for the research data for the Australian Life Atlas as a means of improving the quality of that data.
- In 2008, the Data Archiving & Networked Services (DANS) introduced a "Data Seal of Approval" for the social sciences and humanities that has since gained international recognition [19]. To qualify for the Seal of Approval, data producers, data repositories, and data consumers must comply with certain minimum quality requirements.
- The String of Pearls Initiative [25] collects clinical data and biomaterials, stores them, and makes them accessible according to a strict code of conduct.
Interviews
The findings of the survey of the literature were presented during interviews with sixteen"data professionals", i.e. data managers and researchers.
The above-mentioned tripartite categorisation as regards the life cycle of research data was used to define three types of quality control:
- quality control in the production of data;
- data management: ensuring permanence and accessibility (including metadata, documentation, formats, rights);
- actual content quality: "the scholarly merit of the dataset".
All those interviewed considered this to be a useful categorisation.
Quality during the production phase
An elementary distinction can be made between data produced by equipment and data resulting from the registration of human behaviour and findings. This distinction does not necessarily correspond with the division between the exact sciences and the humanities. Digitised collections of texts in the humanities, for example, belong to the first category of data while the social and economic sciences work with collections of data from both categories. This is an important distinction in the context of the present study because there are different ways of looking at the issue of quality for the two categories. See also [8].
In the first category, it is the accuracy of the equipment and the refinement of the applied algorithms that are central. To assess the accuracy of measurements, the calibration details of the measuring equipment are required, for example. The calibration of the measuring equipment may be changed or a better algorithm may be developed to perform the necessary calculations. This may therefore mean that it must be possible to recalculate the dataset using the improved calibration details and/or the improved algorithm.
In the second category, methodological issues play a primary role. This involves such questions as: is the chosen method for collecting data the most appropriate for this research objective? Has the method been applied correctly (for example random sampling, double-blind testing)? Does the dataset adequately describe the phenomenon that is being studied (for example representativeness)? How have the integrity aspects of the data been dealt with when cleaning up the dataset (for example contradictory data, presumed measuring errors, incomplete data, etc.)? Have the relevant ethical requirements been complied with (for example privacy or animal welfare)?
For both categories of data, the documentation accompanying the dataset must account for these matters. The documentation is an essential component of the dataset and effectively determines its quality. If the documentation is not written during or immediately after the production phase, it usually never gets done.
Quality of data management
Data management focuses on ensuring the long-term accessibility of the dataset. Doing so involves, in part, the same considerations as ensuring long-term access to published digital articles. There are some differences, however.
The first difference has to do with technical permanence. Someone must guarantee this; the researcher's own hard disk or the vulnerable repository of a small institute are not good enough. In the case of articles, many publishers guarantee accessibility, or there may be the e-depots of libraries (including national libraries) such as the National Library of the Netherlands. This is not usually the case with research data, however. Data archives are set up all over the place, generally on the basis of a particular discipline or subject, and often on a national or international scale. As yet, there appears to be no acute shortage of memory capacity, but the need for selection in the future is recognised. This topic goes beyond the scope of the present study.
There is then the question of retrievability, for which good metadata is a basic requirement. The metadata for data collections is more complex than that for articles. (For example, see [23].) The documentation forms part of the metadata but the data formats also need to be recorded. These can be extremely varied, and they relate to a wide range of technical aspects of the data collection. Whether digital objects — in this case collections of data — can be traced is also determined by the application of standards.
Finally, there is the issue of accessibility. The software applications for research data are very varied and often specific to particular disciplines. These applications need to be maintained so as to provide continued future access to the data. It is therefore an obvious step to bring together the research data for particular disciplines or subjects in specialised (international) data archives.
As with articles, access to research data may be affected by copyright considerations. A dataset, for example a body of texts, may be made up of subordinate collections that are subject to different copyright rules. In these cases an Open Access system with standard provisions such as the Creative Commons licences would provide an effective solution.
Scientific/scholarly quality: scholarly merit
When discussing the assessment of the scientific/scholarly quality of research data, our interviewees often referred to some form of peer review. This could either be peer review prior to storage and provision of the data — as part of the peer review of an article based on that data — or subsequent peer review in the form of annotations by reusers (as in [4] and [7]).
In general, the interviewees had their doubts about the feasibility of peer review in advance because of the demand it would make on the peer reviewer's time. (See also [11].) It was also pointed out that such a system would lead to an unnecessary loss of time before the dataset could be made available. (See also [2]). Some respondents thought that it was theoretically impossible to assess the "scholarly merit" of a dataset in isolation; the dataset exists, after all, in the context of a research question.
In an increasing number of cases, datasets are published along with the articles on which they are based, certainly in the case of "enhanced publications". In such cases, the peer review of the article can also take account of the dataset. In many cases, however, it is only the supplementary data that is published along with the article, i.e. a selection of the data necessary to support the article. Respondents doubt whether reviewers actually immerse themselves in that data when arriving at their quality assessment. Here too, pressure of time plays a role.
A new variant in this context involves special journals for "data publications", i.e. separate articles describing the data collection. These articles can make their own contribution to the prestige of the person who produced the data through citations and the impact factor of the journal concerned. Examples include the journals Earth System Science Data [17] and Acta Crystallographica Section E [6].
In the case of subsequent peer review, researchers who re-use the dataset are requested to write a brief review of it. These reviews or annotations are then linked to the dataset. (See also [14]). The question that arose was whether such re-users would in fact be prepared to produce a review. This could perhaps be made a condition for being permitted to re-use the dataset.
Finally, it was suggested that, rather than setting up a separate quality assessment system for data, one could create a citation system for datasets, which would then form the basis for citation indices. The thinking behind this was that citation scores are a generally accepted yardstick for quality.
Classification of datasets
If research datasets are categorised according to origin, one can draw the following broad conclusions as regards quality control.
A. Datasets produced for major research facilities with a view to their being used/re-used by third parties. Examples include data generated by large-scale instruments (LHC, LOFAR), meteorological data (Royal Netherlands Meteorological Institute), data collected by oceanography institutes (NOCD), and longitudinal data on Dutch households (LISS panel). In this situation, there are a number of mechanisms for monitoring and improving the quality of the datasets, with peers being involved in many cases. The quality control for this data is of a high standard; this category of data was therefore not surveyed as regards quality improvement measures.
B. Supplementary data and replication datasets that are published along with scientific/scholarly articles. This often involves subsets of larger datasets. The data concerned should basically be taken into consideration during the peer review process for the publication. In actual practice, this only happens on a limited scale. Matters are different, however, with the specialised data publications referred to above; here, the documentation that belongs with the dataset is published as a separate article in a specialised journal. This article, and with it the dataset, is then subjected to a specific peer review. At the moment, there are only a few such journals [16] and [17].
C. Datasets included in data archives as required in some cases by the body that funds the research, for example the Netherlands Organisation for Scientific Research (NWO) [20]. This may also involve category B datasets if the publisher does not have the facilities to guarantee permanent storage and accessibility of the dataset. In many cases, the staff of the data archive subject the metadata and the documentation accompanying the dataset to a quality check and also, if applicable, a check on whether the content of the dataset actually falls within the scope of the particular data archive [18]. DANS issues datasets that meet certain quality requirements with its Data Seal of Approval [19]. Tailor-made checks on content quality are found in the case of large data collections such as the Genographic Project [13], the RCSB Protein Data Bank [22], and the World Ocean Database 2009 [21].
A few data archives have also set up a kind of "waiting room" where researchers can deposit their datasets without these being subject to prior quality control. A selection of the datasets thus deposited is then subjected to a quality check and included in the data archive. The criteria for selection have not been made explicit.
D. Datasets that are not made (directly) available. This is by its nature a large and virtually unknown area. In the light of the interviews held in the course of our study, it would seem sensible to distinguish between datasets that have been created primarily for the researcher's own use — for example by a PhD student — and datasets created by larger groups or by several groups (including international groups), often with a view to their being used by a large number of people and over a lengthy period. In the latter case, the parties concerned often reach agreement regarding quality and set up mechanisms for monitoring and enforcing it. Datasets created for a researcher's own use will not generally be accompanied by any documentation.
Questionnaire
Based on the literature survey and the interviews, a list of nine measures was drawn up for improving the quality of collections of research data. These measures were submitted in the form of a questionnaire to a representative sample of all Dutch professors and senior lecturers (UHDs), in all a total of 2811 persons.
The response rate was 14%, which can be classed as good. Another 14% explicitly declined to participate, often giving reasons. The large number of explanations accompanying the answers was striking and it seems justifiable to conclude that the topic is one that is of interest to Dutch scientists and scholars.
Virtually all those who filled in the questionnaire are themselves peer reviewers (95%) and more than half (57%) are on the editorial board of a peer-reviewed journal. The respondents also have extensive experience with research datasets: 71% produce/co produce such datasets; 60% have at some point made a dataset available to third parties; and 50% (also) re-use datasets.
The responses were subsequently divided according to the disciplinary domains applied by the European Research Council (No. 24): Physical Sciences and Engineering, Social Sciences and Humanities, and Life Sciences (excluding some respondents who had indicated more than one discipline). Cross-analyses could also be made according to the subgroups of re-users, providers, and producers of datasets.
|
A. Peer review of datasets as part of the peer review of articles 1. In my field, many journals request that one make a replication dataset available. 2. In my field, the peer reviewer normally has access to the underlying dataset for a publication and that dataset is taken into account when assessing the publication. 3. In my field, it is feasible for a peer reviewer to simultaneously assess the publication and the underlying dataset. 4. I think it is important that the underlying dataset be assessed along with the publication during the peer review process. |
In the field of Life Sciences, 17% of the participating scientists said that journals in their discipline more or less require the author of a publication to also submit the underlying dataset. In this discipline, more than half (51%) of respondents consider it important that the dataset published along with an article be also taken into account during the peer review of the publication. Many of them have their doubts, however, as to the feasibility of this (42%: "not feasible"; 37%: "feasible"). Physical Sciences and Engineering and Social Sciences and Humanities follow the same trend but with somewhat lower figures.
|
B. Data publications: peer-reviewed publications about datasets 5. In my field, a peer-reviewed journal for data publications could play a valuable role in drawing attention to important datasets. |
More than half of the participants (51%) see a valuable role for such journals; more than a quarter (28%) are not in favour of such journals. The differences between the disciplines are only slight.
|
C. Comments on quality by re-users of datasets 6. These comments on quality could be useful for future re-users of datasets. 7. As a re-user, I would certainly take the trouble to add such comments regarding the quality of a dataset that I have re-used. 8. As the producer of a dataset, I would welcome such comments on quality from others. |
The proposal received a great deal of support, with hardly any differences between the various disciplines. More than 80% consider these comments to be valuable for future re-users of the datasets. More than 70% say that as a re-user they would take the trouble to add such comments regarding the quality of the dataset, with more than 80% saying that as data producers they would welcome such comments from re users.
|
D. Citation of datasets 9. As a re-user, I would certainly cite datasets where this was possible. 10. As a researcher, I would welcome the option for "my" dataset to be cited. |
This proposal too received a great deal of support and once again the answers given by the respondents from the three disciplines were virtually unanimous. If it were possible, more than three quarters would definitely cite the dataset as a re-user. More than 70% say that as data producers they would welcome the option of their own dataset being cited.
|
E. Support for quality control of datasets at an early stage 11. Training in data management would meet a need of many colleagues in my field. 12. In my field, data audits, examining how datasets are compiled and managed, would help improve data management. |
A significant majority (63%) of respondents in the Life Sciences consider that training in data management and auditing of datasets would be valuable. The figure is much lower in Physical Sciences and Engineering (37%), with Social Sciences and Humanities taking up a mid-range position.
Popularity index
In order to get an idea of how the above options rank in terms of priority, we asked both about the extent to which the above measures can improve the quality of datasets (= 'Do' in the table below) and the extent to which those measures meet with objections (= 'Don't'). A "popularity index" was then produced by subtracting these percentages from one another. The index was compiled for the above proposals plus three measures that are also referred to in the literature and the interviews:
- a mandatory section on data management in research proposals;
- Open Access provision of datasets, perhaps after an embargo period;
- a code of conduct for dealing with data.
In the table below, the various options are presented according to the different disciplines, listed according to their popularity.
| Physical Sciences and Engineering, popularity index (n=61) | Do | Don't | Popularity |
| Open Access provision of datasets, perhaps after an embargo period | 59 | 14.8 | 44.2 |
| Setting up of data publications: peer-reviewed descriptions of datasets | 41 | 6.6 | 34.4 |
| Citing of datasets | 32.8 | 1.6 | 31.2 |
| Comments on quality by re-users, to be published with the dataset | 27.9 | 1.6 | 26.3 |
| Peer review of the dataset as part of peer review of the publication | 39.3 | 29.5 | 9.8 |
| Provision of training in data management | 6.6 | 4.9 | 1.7 |
| Code of conduct for researchers for data management and provision of datasets | 13.1 | 14.8 | –1.7 |
| Mandatory section on data management in research proposals submitted to bodies financing research | 4.9 | 39.3 | –34.4 |
| Periodic data audits | 6.6 | 44.3 | –37.7 |
| Social Sciences and Humanities, popularity index (n=153) | Do | Don't | Popularity |
| Citing of datasets | 37.9 | 4.6 | 33.3 |
| Setting up of data publications: peer-reviewed descriptions of datasets | 34 | 5.2 | 28.8 |
| Open Access provision of datasets, perhaps after an embargo period | 40.5 | 16.3 | 24.2 |
| Comments on quality by re-users, to be published with the dataset | 27.5 | 5.2 | 22.3 |
| Code of conduct for researchers for data management and provision of datasets | 22.9 | 7.2 | 15.7 |
| Provision of training in data management | 17 | 3.3 | 13.7 |
| Peer review of the dataset as part of peer review of the publication | 36.6 | 25.5 | 11.1 |
| Periodic data audits | 5.9 | 21.6 | –15.7 |
| Mandatory section on data management in research proposals submitted to bodies financing research | 11.1 | 30.7 | –19.6 |
| Life Sciences, popularity index (n=147) | Do | Don't | Popularity |
| Code of conduct for researchers for data management and provision of datasets | 32.7 | 6.1 | 26.6 |
| Comments on quality by re-users, to be published with the dataset | 34.7 | 8.2 | 26.5 |
| Citing of datasets | 25.2 | 1.4 | 23.8 |
| Provision of training in data management | 21.1 | 1.4 | 19.7 |
| Setting up of data publications: peer-reviewed descriptions of datasets | 25.9 | 8.8 | 17.1 |
| Peer review of the dataset as part of peer review of the publication | 42.2 | 25.2 | 17 |
| Periodic data audits | 24.5 | 19 | 5.5 |
| Open Access provision of datasets, perhaps after an embargo period | 29.9 | 26.5 | 3.4 |
| Mandatory section on data management in research proposals submitted to bodies financing research | 19.7 | 29.3 | –9.6 |
Analysis
Scientists and scholars in all disciplines would welcome greater clarity regarding the re-use of their data, both through citations and through comments by re users. Setting up special journals for data publications is also popular in all disciplines. The view regarding a mandatory section on data management in research proposals is also unanimous, but negative. The decisive factor here is a fear of bureaucracy.
It is striking that the high score in all disciplines for extending the peer review of an article to the replication data published along with it is largely negated by the objections. The reason given in the explanations is the excessive burden on peer reviewers. It would seem that it is here that the peer review system comes up against the limits of what is possible.
The popularity (or lack of popularity) of the various other measures is clearly specific to the disciplines concerned. Although open access to data is popular in Physical Sciences and Engineering and in Social Sciences and Humanities, those in the field of Life Sciences have major objections. At the moment, their primary need would seem to be a code of conduct for the provision of data. A need is felt for this in Social Sciences and Humanities too, although to a lesser extent. One reason for this opinion may be related to the two types of data referred to above: physical measurements as opposed to human-related data.
There is a certain correlation between data management training and data audits. For both, the score is low in Physical Sciences and Engineering, somewhat higher in Social Sciences and Humanities, and moderate in Life Sciences. In all the disciplines, training in data management scores better than data audits. This is possibly because training must precede audits.
If we round off the popularity indices at 10 points and show each 10 by a + or a —, the result is the following overview:
| Physical Sciences and Engineering |
Social Sciences and Humanities |
Life Sciences | |
| Setting up of data publications: peer-reviewed descriptions of datasets | +++ | +++ | ++ |
| Citing of datasets | +++ | +++ | ++ |
| Comments on quality by re-users, to be published with the dataset | +++ | ++ | +++ |
| Open Access provision of datasets, perhaps after an embargo period | ++++ | ++ | |
| Code of conduct for researchers for data management and provision of datasets | ++ | +++ | |
| Peer review of the dataset as part of peer review of the publication | + | + | ++ |
| Provision of training in data management | + | ++ | |
| Periodic data audits | – – – – | – – | + |
| Mandatory section on data management in research proposals submitted to bodies financing research |
– – – | – – | – |
Recommendations
The following three quality improvement measures meet a need in all the different disciplines and should therefore be implemented as soon as possible. Together, they form a synergistic package and serve to operationalise a current recommendation to the European Commission by the High Level Expert Group on Scientific Data [1].
- Establish journals for data publications;
- Make the citing of datasets possible;
- Promote the provision of quality-related user comments on datasets.
These measures will improve the quality of research data. They are endorsed by the research community and they encourage producers to circulate their data. It is recommended that an analysis be made of the structure, relevant parties, and financing for such measures. SURF could act as the initiator for such research, which should also be positioned within an international context.
Measures that are currently advised against are the introduction of a mandatory section on data management in research proposals and — except in the field of Life Sciences — the institution of periodic data audits. Opposition to these measures is significant, presumably based on a fear of bureaucracy. That fear should be removed by making clear that it is an effective, "light" approach that is being advocated. Research councils such as the Netherlands Organisation for Scientific Research (NWO) and university associations (the Association of Universities in the Netherlands, VSNU) should take the lead in this.
Where opinions of the other measures are concerned, there are significant differences between disciplines. Open access to data scores well in Physical Sciences and Engineering whereas this discipline expresses little need for a code of conduct, training in data management, or peer review of datasets as a component of peer review of the publication concerned. The response of Life Sciences is complementary. Social Sciences and Humanities take up an intermediate position. Where a code of conduct for Life Sciences is concerned, the initiative by the NFUMC [25] might provide a relevant context.
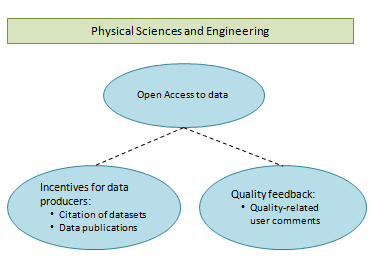 |
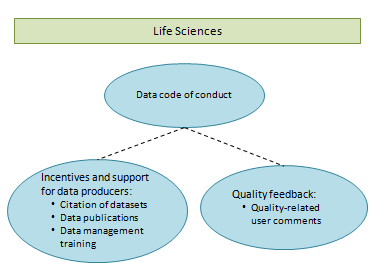 |
| The attitude in Physical Sciences and Engineering would seem to be that quality control of data can best be effectuated through citation of datasets and quality-related comments on those datasets which are made available through Open Access data publications. No need is expressed for codes of conduct, training in data management, or peer review of data that is published together with articles. | In Life Sciences, there is first and foremost a need for a code of conduct for dealing with data. Training in data management fits in with this. A direct judgment on quality can be given through peer review of the data that is published together with articles and through quality-related comments, a derived judgment through data publications and citations. Open access to data does not score highly. Interestingly enough, Life Sciences are ahead of the other disciplines as regards open access to articles. |
Acknowledgement
We thank Marnix van Berchum of SURFfoundation for his support in the realization of this article.
References
Publications (in reverse chronological order)
[1] Riding the wave — How Europe can gain from the rising tide of scientific data — Final report of the High Level Expert Group on Scientific Data - October 2010. http://ec.europa.eu/information_society/newsroom/cf/document.cfm?action=display&doc_id=707
[2] Open to All? Case studies of openness in research. A joint RIN/NESTA report. September 2010. http://www.rin.ac.uk/our-work/data-management-and-curation/open-science-case-studies
[3] Data Sharing Policy: version 1.1 (June 2010 update). Biotechnology and Biological Sciences Research Council UK. http://www.bbsrc.ac.uk/web/FILES/Policies/data-sharing-policy.pdf
[4] Quality assurance and assessment of scholarly research. RIN report. May 2010. http://www.rin.ac.uk/quality-assurance
[5] Rechtspraak en digitale rechtsbronnen: nieuwe kansen, nieuwe plichten. Marc van Opijnen. Rechtstreeks 1/2010. http://www.rechtspraak.nl/NR/rdonlyres/6F244371-265F-4348-B7BD-22EB0C892811/0/rechtstreeks20101.pdf
[6] Perceived Documentation Quality of Social Science Data. Jinfang Niu. 2009. http://deepblue.lib.umich.edu/bitstream/2027.42/63871/1/niujf_1.pdf
[7] The Publication of Research Data: Researcher Attitudes and Behaviour. Aaron Griffiths, Research Information Network The International Journal of Digital Curation Issue 1, Volume 4, 2009. http://www.ijdc.net/index.php/ijdc/article/viewFile/101/76
[8] Managing and sharing data, a best practice guide for researchers, 2nd edition. UK Data Archive. 18 September 2009. http://www.esds.ac.uk/news/publications/managingsharing.pdf
[9] e-IRG and ESFRI, Report on Data Management. Data Management Task Force. December 2009. http://ec.europa.eu/research/infrastructures/pdf/esfri/publications/esfri_e_irg_report_data_management_december_2009_en.pdf
[10] Australian National Data Service (ANDS) interim business plan, 2008/9. http://ands.org.au/andsinterimbusinessplan-final.pdf
[11] Peer Review: benefits, perceptions and alternatives. PRC Summary Papers 4. 2008. http://www.publishingresearch.net/documents/PRCPeerReviewSummaryReport-final-e-version.pdf
[12] To Share or not to Share: Publication and Quality Assurance of Research Data Outputs. RIN report; main report. June 2008. http://eprints.ecs.soton.ac.uk/16742/1/Published_report_-_main_-_final.pdf
[13] The Genographic Project Public Participation Mitochondrial DNA Database. Behar, D.M, Rosset, S., Blue-Smith, J., Balanovsky, O., Tzur, S., Comas, D., Quintana-Murci, L., Tyler-Smith, C., Spencer Wells, R. PLoS Genet 3 (6). 29 June 2007. http://www.plosgenetics.org/article/info:doi/10.1371/journal.pgen.0030104
[14] Dealing with Data: Roles, Rights, Responsibilities and Relationships, Consultancy Report. Dr Liz Lyon, UKOLN, University of Bath. 19 June 2007. http://www.jisc.ac.uk/media/documents/programmes/digitalrepositories/dealing_with_data_report-final.pdf
[15] OECD Principles and Guidelines for Access to Research Data from Public Funding. 2007. http://www.oecd.org/dataoecd/9/61/38500813.pdf
Websites (accessed in August and September 2010)
[16] Acta Crystallographica Section E: Structure Reports Online. http://journals.iucr.org/e/journalhomepage.html
[17] Earth System Science Data. The Data Publishing Journal. http://www.earth-system-science-data.net/review/ms_evaluation_criteria.html
[18] Appraisal Criteria in Detail. Inter-University Consortium for Political and Social Research. http://www.icpsr.umich.edu/icpsrweb/ICPSR/curation/appraisal.jsp
[19] Data Seal of Approval. Data Archiving & Networked Services (DANS). http://www.datasealofapproval.org/
[20] NWO-DANS data contract. http://www.dans.knaw.nl/sites/default/files/file/NWO-DANS_Datacontract.pdf
[21] World Ocean Database 2009. NOAA Atlas NESDIS 66. ftp://ftp.nodc.noaa.gov/pub/WOD09/DOC/wod09_intro.pdf
[22] RCSB Protein Data Bank Deposition Portal. http://deposit.rcsb.org/
[23] Data Documentation Initiative. http://www.ddialliance.org/
[24] European Research Council. http://en.wikipedia.org/wiki/European_Research_Council
[25] The String of Pearls Initiative. Netherlands Federation of University Medical Centres. http://www.string-of-pearls.org/
About the Authors
 |
Leo Waaijers has a long-term commitment to (inter-)national Open Access developments, first as the University Librarian of Delft University of Technology (1988) and later in a corresponding post at Wageningen University & Research Centre (2001). He concluded his career as the manager of the SURF Platform ICT and Research where he managed the national DARE programme (2004-2008). In 2008 he won the SPARC Europe Award for Outstanding Achievements in Scholarly Communications. After his retirement he advised about the Open Access infrastructure of the Irish universities (together with Maurice Vanderfeesten) and in 2009 he evaluated the Swedish national Open Access programme "Open Access.se" (together with Hanne Marie Kvaerndrup). |
 |
Maurits van der Graaf started Pleiade Management and Consultancy in 2000, focusing on archives, libraries and publishers. Its activities include market research and evaluation, and strategic studies. Recent assignments include a study on repositories in Europe, on digital-born cultural heritage in the Netherlands and on the usage of E-books (see http://www.pleiade.nl). Before Pleiade he held various jobs at publishers and libraries, including Product Manager Excerpta Medica database (Elsevier), Director of the Dutch Current Research Agency (NBOI) and Deputy-Director of the Netherlands Institute for Scientific Information Services (NIWI). He studied Biology at the University of Utrecht. |
|
|
|
| P R I N T E R - F R I E N D L Y F O R M A T | Return to Article |