|
|
|
| P R I N T E R - F R I E N D L Y F O R M A T | Return to Article |
D-Lib Magazine
January/February 2011
Volume 17, Number 1/2
DataONE: Data Observation Network for Earth — Preserving Data and Enabling Innovation in the Biological and Environmental Sciences
|
William Michener |
Dave Vieglais |
|
Todd Vision |
John Kunze |
|
Patricia Cruse |
Greg Janée |
doi:10.1045/january2011-michener
Abstract
This paper describes DataONE, a federated data network that is being built to improve access to, and preserve data about, life on Earth and the environment that sustains it. DataONE supports science by: (1) engaging the relevant science, library, data, and policy communities; (2) facilitating easy, secure, and persistent storage of data; and (3) disseminating integrated and user-friendly tools for data discovery, analysis, visualization, and decision-making. The paper provides an overview of the DataONE architecture and community engagement activities. The role of identifiers in DataONE and the policies and procedures involved in data submission, curation, and citation are discussed for one of the affiliated data centers. Finally, the paper highlights EZID, a service that enables digital object producers to easily obtain and manage long-term identifiers for their digital content.
Keywords: data centers, data citation, digital object identifiers, digital preservation, digital repositories, identifiers, preservation
Introduction
Numerous grand environmental challenges face humankind in the next decades including climate change, decreased water availability, and loss of ecosystem services. The science required to understand and mitigate these challenges will require unprecedented access to data that cross scientific domains, distance (meters to the biosphere), time (seconds to centuries), and scales of biological and physical organization. Principal data challenges lie in discovering relevant data, dealing with extreme data heterogeneity, and converting data to information and knowledge. Addressing these challenges requires new approaches for managing, preserving, analyzing, and sharing data, which are equally challenging from technical and socio-cultural perspectives. One such challenge relates to how data and metadata objects are identified within and across repositories, as well as how publishers and data contributors cite data.
This paper first provides an overview of the DataONE architecture and community engagement activities. Second, particular attention is paid to the role of identifiers in DataONE — one of the initial data challenges addressed by the project. Third, specific examples focusing on data submission, curation and preservation, and citation are presented for one of the DataONE Member Nodes — i.e., Dryad, a digital repository that supports publishers and scientific societies. Fourth, the paper describes EZID — a service that enables easy acquisition and management of long-term identifiers.
DataONE
DataONE is a federated data network that is being built to improve access to data about life on Earth and the environment that sustains it, and to support science by: (1) engaging the relevant science, data, and policy communities; (2) facilitating easy, secure, and persistent storage of data; and (3) disseminating integrated and user-friendly tools for data discovery, analysis, visualization, and decision-making.
DataONE is being designed and built to provide a foundation for innovative environmental research that addresses questions of relevance to science and society. Five activities are central to the DataONE mission:
- Discovery and access: Enabling discovery and access to multi-scale, multi-discipline, and multi-national data through a single location.
- Data integration and synthesis: Assisting with the development of transformational tools that shape our understanding of Earth processes from local to global scales.
- Education and training: Providing essential skills (e.g., data management training, best practices, tool discovery) to enhance scientific enquiry.
- Building community: Combining expertise and resources across diverse communities to collectively educate, advocate, and support trustworthy stewardship of scientific data.
- Data Sharing: Providing incentives and infrastructure for sharing of data from federally funded researchers in academia.
DataONE Architecture
The overall design is based on several precepts. First, it is recognized that data are best managed at the data repositories that already support particular communities of users. Second, DataONE software must provide benefits for scientists today, and yet be able to adapt to software and standards evolution. Third, DataONE cyberinfrastructure development activities should support and adapt existing community software efforts, emphasizing free and open source software.
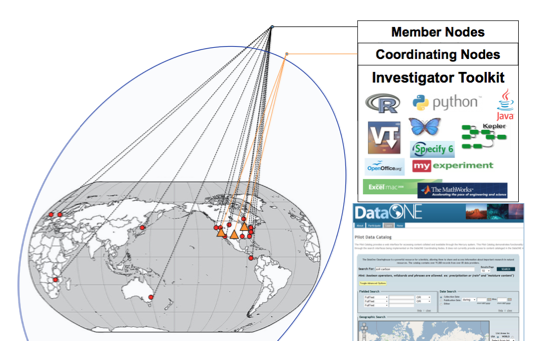
Figure 1. DataONE is comprised of three principal components: (1) Member Nodes (circles); (2) Coordinating Nodes (triangles); and (3) an Investigator Toolkit. Access to data, services, and tools is supported through the DataONE web site.
The DataONE architecture is illustrated in Figure 1. The cyberinfrastructure implementation of DataONE is based on three principal components: Member Nodes which are existing or new data repositories that support the DataONE Member Node APIs; Coordinating Nodes that are responsible for cataloging content, managing replication of content, and providing search and discovery mechanisms; and an Investigator Toolkit which is a modular set of software and plug-ins that enables interaction with DataONE infrastructure through commonly used analysis and data management tools. There are three major development phases of the project: (1) prototype development for proof of concept; (2) release of a stable, secure, reliable core data management and discovery infrastructure; and (3) progressive addition of new features and functionality. The project is currently ending the first of these three phases.
Member Nodes
Data are principally acquired and maintained by Member Nodes that include a wide variety of institutions including Earth observing institutions, research projects and networks, libraries, universities, and governmental and non-governmental organizations. Each Member Node supports a specific constituency through its own implementation and often provides value-added support services (e.g., user help desk). It is, therefore, expected that DataONE will accommodate highly geographically distributed and diverse Member Node implementations.
The prototype DataONE infrastructure is being tested and presently includes three Member Nodes: the Distributed Active Archive Center for Biogeochemical Dynamics at Oak Ridge National Laboratory (ORNL-DAAC); the Dryad repository being developed in conjunction with the National Evolutionary Synthesis Center; and the Knowledge Network for Biocomplexity (KNB) which was developed at the National Center for Ecological Analysis and Synthesis. The three initial Member Nodes were selected so as to represent a diversity of communities and data that would be encompassed by DataONE as well as the different software platforms, services, metadata standards, levels of curation, and data submission mechanisms that are supported by each Member Node (Table 1).
| ORNL-DAAC | Dryad | KNB | |
| Community Served | Agency repository | Journal consortium | Research network |
| Data types | Terrestrial ecology and biogeochemical dynamics | Basic and applied biosciences (incl. ecology and evolution) | Biodiversity, ecology, environmental |
| Size | 900 data products, ~ 1 TB | ~ 900 data products, ~ 3 GB | 20,000 data products, ~ 100s GBs |
| Services | Tools for data preservation, replication, discovery, access, subsetting, and visualization | Tools for data preservation, replication, discovery and access | Tools for data preservation, replication, discovery, access, management, and visualization |
| Metadata Standards | FGDC subset | Dublin Core application profile | EML, FGDC |
| Degree of Curation | High | Medium | Low |
| Data Submission Mechanisms | Staff-assisted submission and curation of final data product | Web-based data submission at time of journal article submission | Self-submission via desktop tool at any time |
| Sponsor | NASA | NSF/JISC/societies/publishers | NSF |
Table 1. Characterization of the three Member Nodes initially included in the DataONE prototype (Note: FGDC-Federal Geographic Data Committee; EML-Ecological Metadata Language; NASA-National Aeronautics and Space Administration; NSF-National Science Foundation; JISC-Joint Information Systems Committee).
Coordinating Nodes
Coordinating Nodes are designed to be tightly coordinated, stable platforms that provide network-wide services to Member Nodes. These services include network-wide indexing of digital objects, data replication services across Member Nodes, and mirrored content of science metadata present at Member Nodes. The initial three Coordinating Nodes are located at Oak Ridge Campus (a consortium comprised of Oak Ridge National Laboratory and the University of Tennessee), the University of California Santa Barbara Library, and the University of New Mexico. A simple series of user interactions with a DataONE Member Node and the behind-the-scenes interactions with other Member Nodes and the Coordinating Nodes are illustrated in Figure 2.
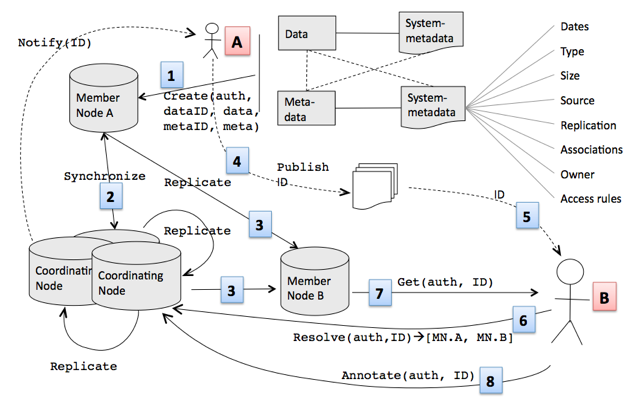
Figure 2. Typical user interactions with DataONE Member Nodes as well as the underlying services provided by the Coordinating Nodes: (1) The data originator (A) submits data and metadata to Member Node A (which automatically generates system metadata for the user-supplied data and metadata); (2) Member Node A synchronizes with a Coordinating Node providing the metadata for the new data product and initiating replication of the metadata across the other Coordinating Nodes as well as (3) the mirroring of the data product from Member Node A to Member Node B in synchronization with the Coordinating Nodes; (4) The data originator (A) includes the identifier for the data product in a published journal article (5) which is then viewed by another scientist (B) who wishes to view the data; communicating with the Coordinating Node to resolve the identifier (6) triggers access to the data product via Member Node B (7) and (optionally) notification to the original author that the data product has been accessed. Scientist B may also annotate the data (8), and such annotations would be available to other users.
Investigator Toolkit
DataONE provides a suite of software tools for researchers that are fully integrated with the infrastructure through the programmatic interfaces, and enable easy discovery of and access to relevant data. Communication is supported via service interfaces that enable low-level data access and higher-level business logic (e.g., packaging metadata and data, relationships between content). The overall objective is to support both general purpose (e.g., R, MATLAB) and domain-specific tools (e.g., GARP, Phylocom). DataONE emphasizes free and open source tools, but also will support commercial products like MATLAB and Microsoft Excel. Ultimately, a library of tools will be offered that support all components of the scientific data life cycle including: data management and preservation, data query and access, data analysis and visualization, process management and preservation. The Toolkit will be well documented and include examples for developers that illustrate how to interact with the infrastructure to enable support for new tools. The Investigator Toolkit currently has client libraries implemented in two widely used languages (Java and Python), includes command line clients as well as a plug-in for the R statistical and analysis package, and includes a proof-of-concept "DataONE drive" which enables users to mount the entire DataONE cloud infrastructure as a file system.
DataONE Community Engagement
Implementing the infrastructure requires that DataONE bring new communities together in new ways. This is achieved via Community Engagement Working Groups that engage participants in identifying, describing, and implementing the DataONE cyberinfrastructure, governance, and sustainability models. These working groups, which consist of a diverse group of graduate students, educators, government and industry representatives, and leading computer, information, and library scientists: (1) perform computer science, informatics, and social science research related to all stages of the data life cycle; (2) develop DataONE interfaces and prototypes; (3) adopt/adapt interoperability standards; (4) create value-added technologies (e.g., semantic mediation, scientific workflow, and visualization) that facilitate data integration, analysis, and understanding; (5) address socio-cultural barriers to sustainable data preservation and data sharing; and (6) promote the adoption of best practices for managing the full data life cycle.
The Role of Identifiers in DataONE
One of the central challenges faced by digital repositories and federated data systems is determining how digital objects will be identified and tracked. Here, we define the requirements for identifiers in DataONE and discuss how identifiers are being implemented broadly. Following sections describe how data and data citation are treated in one of the three prototype Member Nodes, and introduce EZID — which facilitates acquisition and management of persistent identifiers for data and other digital objects.
Identifiers are utilized by data providers as a mechanism to unambiguously identify the individual objects (documents, data sets, data records) they manage. Identifiers in use by the provider are unique at least within the scope of the data provider itself. In some cases the data provider will use a system that expands the scope of guaranteed uniqueness to a larger domain either through an algorithmic approach, in which the likelihood of duplication is statistically improbable, or through segmenting by namespaces, with values appearing within the namespace under the control of the identifier generator and namespace control enforced at a higher level to thus ensure uniqueness within the domain of interest.
Uniqueness. Uniqueness of identifiers in DataONE is largely under the control of the Member Nodes (i.e., the data providers), with the requirement that an existing identifier (i.e., one that is already registered in the DataONE system) cannot be reused. This is enforced for new content by checking the uniqueness of a proposed identifier in the create() method, and for existing content by ignoring content with identifiers that are already in use. A mechanism is also available to reserve an identifier, so that a client may, for example, compose a composite object prior to committing the new content to storage on the Member Node.
Authority. DataONE treats the original identifier (i.e., the first assignment of the identifier to an object that becomes known to DataONE) as the authoritative identifier for an object. Although generally not encouraged, multiple identifiers may refer to a particular object and in such cases DataONE will attempt to utilize the original identifier for all communications about the object.
Opacity. Identifiers utilized by Member Nodes can take many different forms from automatically generated sequential or random character strings to strings that conform to schemes such as the LSID and DOI specifications. Identifiers are treated as opaque strings in the DataONE system, with no meaning inferred from structure or pattern that may be present in identifiers. The rules for identifier construction in DataONE are minimal and intended to ensure practical utility of identifiers.
Immutability. Once assigned and registered in the DataONE infrastructure, an identifier will always refer to the same set of bytes in the case of data and metadata objects. Generation of other representations of the objects may be supported by services (e.g., an image may be transformed from TIFF to JPEG), but the identifier will always refer to the original form.
Resolvability. A fundamental goal of DataONE is to ensure that any identifier utilized in the system is resolvable, that is, DataONE provides a method that will enable retrieval of the bytes associated with the object (the actual object bytes or metadata associated with the object). Resolution is handled by the Coordinating Nodes through the resolve() method. A guarantee of resolvability is a fundamental function of the DataONE infrastructure upon which many other services may be constructed, both within DataONE and by third party systems.
Granularity. The definition of "data" is somewhat arbitrary in that a data object may be a single record within some larger collection, or may refer to an entire set of records contained within some package.
It is not currently (version 1.x) possible to reference an offset or named location within an object since opacity of identifiers, in the context of DataONE, precludes the use of fragment identifiers, since there is no reliable way to determine if a string suffix does indeed indicate a fragment or is actually part of the identifier string. Instead, it is more likely that selectors will be used along with some convention of representation. A selector is an operator that is able to extract some piece of content from an object referenced by an identifier. Selectors will necessarily be of varied form. For example, xpath may be enabled as a selector that can be applied against XML or well formed HTML documents, and similarly a feature expressed in OGC WKT may act as a selector against a spatial data set object.
Data Citation in Dryad
Dryad is a repository for the data supporting peer-reviewed articles in the basic and applied biosciences. It works closely with partner journals in encouraging and enabling authors to archive their data during the article publication process (either prior to peer review, or between acceptance and publication). The partner journals govern repository policy through the Dryad Consortium Board. Data may be embargoed upon deposit (generally for one year post publication), but at the expiration of the embargo, the data are released into the public domain through a Creative Commons Zero (CC0) waiver.
A key incentive for authors to archive data is that they can have a measurable scientific impact above and beyond that of the article alone. Citations to articles are widely used by the academic community as a measure of scholarly impact and a sophisticated infrastructure exists for tracking such citations. Thus, for authors to receive professional credit for the data that they share, it would be desirable for reuse of data to be reliably tracked through data citations that leverage this tradition.
Dryad's policy is that those who reuse the data within their own research should, when publishing that research, cite the data in addition to the original article (which provides the context for understanding the collection and use of the data). Note that since the data in Dryad are made freely available for reuse through CC0, rather than a more restrictive license such as CC-BY, data citation is treated not as a legal obligation but rather as a matter of scientific convention.
Those who cite data in Dryad are asked to include the following elements: the author(s), the date of article publication, the title of the data package, which in Dryad is always "Data from: [Article name]", the name "Dryad Digital Repository", and the data identifier. An example is given below:
Sidlauskas B (2007) Data from: Testing for unequal rates of morphological diversification in the absence of a detailed phylogeny: a case study from characiform fishes. Dryad Digital Repository. doi:10.5061/dryad.20
This convention provides a human readable citation that contains enough information for the record to be attributed to the original authors, while also being suitable for inclusion within the bibliography of the article and processing by indexing services.
An important component of the citation is the Digital Object Identifier (DOI®), which serves the role of volume and page numbers in a traditional article citation. Dryad DOIs are registered at DataCite through the California Digital Library, as described in the following section. While all the other information provided by the citation is available as metadata registered for each resolvable DOI, it is important to the human reader that this information is presented directly within the printed article in the form of a traditional citation. In addition, since DOIs are familiar to researchers because of their use for articles, its use in this context is likely to be accepted more readily than would less standard identifier strings. The use of DOIs for data follows the lead of pioneering organizations such as PANGAEA and the ORNL-DAAC.
Authors may archive one or more data files in Dryad in association with each of their articles. All the data files that support one article, together with all the metadata for each file and the collection as a whole, constitute a "data package" within Dryad. Each data package is assigned a DOI (e.g., doi:10.5061/dryad.20). Partner journals print the data DOI within the original published article, and Dryad reciprocates by including the DOI for the article within the package metadata (and hyperlinked from the repository record). Should either the repository or publisher change the URL of the data record or article, future researchers will be directed to the updated location. Thus, there are persistent reciprocal linkages between the article and the data. This is made possible by having the data archived prior to publication even when it is under embargo.
Although identifiers in Dryad are compatible with the DataONE standards described above, Dryad places some additional semantics into identifiers for the convenience of human users. For example, Dryad allows authors to provide updates to data in the repository post-publication, and these updates can be tracked using version numbers within the DOIs. An update of any one file increments the version of that data file and also the corresponding data package. Each version is assigned a new DOI that bears a strict relation to the original DOI. Namely, the version number is appended to the original DOI string. For example doi:10.5061/dryad.20.2 can be used to refer specifically to the second version of the above data package.
In addition to the DOI that is assigned to the data package, each data file within that package is assigned an independent DOI. Data file DOIs take the package DOI as a base string, and extend it with a slash followed by an integer. For example, doi:10.5061/dryad.20.2/1 and doi:10.5061/dryad.20.2/2 would be assigned to the first and second data files of the package cited above. A single DOI can be also used to access a particular format of metadata or data file through the use of parameters. For example, doi:10.5061/dryad.20.2/3.1?urlappend=%3fformat=dc would provide the Dublin Core metadata.
Through these practices, Dryad hopes to lay a groundwork for a culture of data citation and electronic access that bridges the conventions of traditional scholarship and the needs of data-driven science.
EZID: Long-term Identifiers Made Easy
The California Digital Library (CDL) has long been active in creating standards and tools to support persistent identification, storage, and description of digital assets. A challenge with these materials has always been discovery and long-term identification; internet-wide search engines index text-based materials much better than they index data, which generally require stable identifiers and expensive metadata generation for minimal discovery and access.
In June 2010, CDL released a service called EZID (easy-eye-dee) with Dryad as its first customer. Both the University of California and Dryad needed such a service for several reasons:
- To register and point to many kinds of objects that have not been citable before, especially datasets and parts of datasets.
- To permit authors of scholarly articles based on one or more datasets to cite the data using the emerging international DataCite standard.
- To help users more reliably find and examine datasets.
- To support data sharing, so that others can replicate, confirm, correct, annotate, or challenge the findings.
- To support dataset citations in scholars' papers, CVs, providing valuable attribution for the hard work of data production that is beginning to be recognized as legitimate scholarly output alongside traditional journal publication.
- To make it easy for a researcher to keep track of versions of datasets, even before they are published.
- To make it easier for research sponsors, using persistent identifiers, to keep metrics on publication and retention.
- To enhance scholarly communication by providing publishers with a consistent and reliable way to reference "supplementary materials".
What EZID Does
EZID is a service that makes it simple for digital object producers (researchers and others) to obtain and manage long-term identifiers for their digital content. One can create identifiers for any kind of entity — physical, digital, abstract, etc. For identifiers of objects on the web, one can use EZID to maintain their current locations so that people who click on the identifiers are correctly forwarded.
Two identifier types (schemes) are supported, ARKs (Archival Resource Keys) and DOIs (Digital Object Identifiers). In the future other identifier types will be supported such as URLs and URNs. Also being considered is support for data identifier types used by DataONE that are not normally considered "actionable" (clickable) on the web, such as PMID, GO, and EC.
EZID provides a uniform interface to creating and managing these different types of identifiers, hiding the technical details of interacting with the respective identifier providers. Additionally, EZID uniformly minimizes the requirements for creating identifiers. EZID requires that the creator of an identifier be a registered user having at least an email address as contact information. Otherwise, no metadata or even an object location need be supplied at the time of creation. (If no object location is supplied, EZID uses the location of the identifier's management page in EZID as an interim object location, thus in a sense making the identifier self-referential.) By lowering requirements EZID attempts to encourage early incorporation of identifiers in digital objects and workflows.
You can also use EZID to store citation metadata with identifiers to aid in interpreting and maintaining them. Several metadata profiles (schemas) are supported, including Dublin Core, Dublin Kernel, and DataCite Kernel. (The latter is an emerging international standard originating from the DataCite consortium, which was established to promote standards for citing and persistently identifying research datasets. As a founding member of DataCite, the California Digital Library (CDL) created EZID partly as an easy way for researchers to register dataset citations in the DataCite infrastructure.) The different citation metadata profiles are currently treated separately and independently by EZID, but we intend to develop a metadata cross-walk capability, giving users more flexibility in entering and viewing metadata.
EZID implements access control. All identifiers and citation metadata are publicly available, but only the "owner" of an identifier (the user that created it) may update it. Additionally, every user belongs to "group" (typically the user's institution) and the group may assign a new owner to an identifier if the original owner becomes unavailable for any reason. In this way EZID supports long-term maintenance of identifiers by building in support for handoffs of management responsibility over time.
EZID is available via both a programming interface (an "API" that software can use) and a web user interface. The API is important for automated operation, such as when another service needs to "call" EZID or an organization wants to update thousands of its identifiers at once. CDL's Merritt repository service for digital objects, for example, calls the EZID service when it needs to create identifiers or record citation metadata. Eventually EZID will itself be able to call Merritt so that users can deposit objects for which they will have just created identifiers.
What EZID Looks Like
The EZID user interface is available from http://n2t.net/ezid. It consists of one basic page with four tabs. One typically needs to be logged in to create and manage identifiers. In the screen shot in Figure 3, the user "dryad" is visiting the Create tab, with the option to create either a DOI or an ARK.
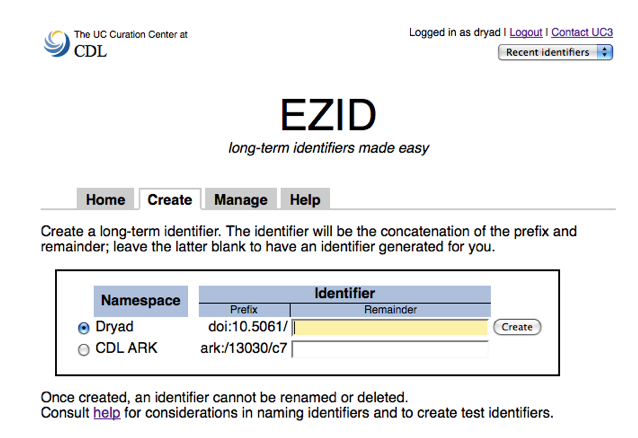
Figure 3. In this illustration of the EZID interface, the user "dryad" is visiting the Create tab, with the option to create either a DOI or an ARK. A prefix is displayed and the user can choose to enter the rest of the identifier and click the Create button, or to just click Create and let EZID generate a random-looking string that will become rest of the identifier to be created.
After clicking the Create button, the user is switched to the Manage tab and given the chance to enter metadata. An especially important element of metadata is the "object location", which is the web address where people will be redirected when they click on the "URL form".
Conclusion
Numerous data repositories exist worldwide. Nevertheless, there exist few common, seamless solutions for enabling data discovery, acquisition, citation, and use/re-use. The average scientist may be easily overwhelmed, for example, in attempting to discover and acquire relevant data that may be scattered across a dozen or more different repositories. DataONE is being built to address these and related challenges by focusing on developing the interoperability solutions and tools that enable scientists to focus on the science — i.e., reduce time spent searching for, managing, manipulating and citing data.
The need to develop and manage identifiers for data and other digital objects was one of the initial challenges tackled by DataONE and its partners, culminating in the approaches implemented by DataONE and Dryad, as well as the creation of a new tool of broad benefit to the community (i.e., EZID). Much work remains with respect to developing relevant interoperability solutions and adding new tools to the Investigator Toolkit so that scientists can more readily access, integrate, and analyze data using tools with which they are proficient at and comfortable with. Success in tackling these challenges rests on strong community engagement and the established collaboration among organizations that have multi-decade expertise in a wide range of fields including: existing archive initiatives, libraries, environmental observing systems and research networks, data and information management, science synthesis centers, and professional societies.
Acknowledgements
Work represented in this paper was funded by the U.S. National Science Foundation through "INTEROP: Creation of an International Virtual Data Center for the Biodiversity, Ecological and Environmental Sciences" (#0753138); "Data Observation Network for Earth (DataONE)" (#0830944); and "A Digital Repository for Preservation and Sharing of Data Underlying Published Works in Evolutionary Biology" (#0743720). The authors appreciate technical input from Matt Jones, Robert Cook, Ryan Scherle, Kayla Achen, and Joan Starr, as well as the DataONE team.
About the Authors
 |
William Michener is a Professor and Director of e-Science Initiatives for University Libraries at the University of New Mexico, and is Principal Investigator for DataONE. He has directed several large interdisciplinary research and cyberinfrastructure projects including the Development Program for the U.S. Long-Term Ecological Research Network, the Science Environment for Ecological Knowledge, and other programs that focus on developing information technologies for the ecological and environmental sciences. He serves as Data Archives Editor for the Ecological Society of America and as Associate Editor of the Journal of Ecological Informatics. |
 |
Dave Vieglais is a Senior Research Scientist at the University of Kansas Biodiversity Research Institute and serves as Director for Development and Operations for DataONE. He has played an active role in the development of standards and infrastructure for the broader dissemination of biodiversity information including authoring the first version of the Darwin Core (initially expressed as a Z39.50 profile) and participating in the formation of several networks for sharing natural history specimen and observation information (e.g., MaNIS, ORNIS, VertNet, FishNet, GBIF). |
 |
Todd Vision is an Associate Professor of Biology at the University of North Carolina at Chapel Hill and the Associate Director for Informatics at the National Evolutionary Synthesis Center. An evolutionary biologist by training, he is a principal investigator of the National Science Foundation funded Dryad repository project, and an advocate of open-source collaborative cyberinfrastructure development. |
 |
John Kunze is Associate Director of the University of California Curation Center in the California Digital Library, and has a background in computer science and mathematics. His current work focuses on dataset curation, archiving websites, creating long-term durable information object references using ARK identifiers and the N2T resolver, and promoting lightweight Dublin Core "Kernel" metadata. He contributed heavily to the standardization of URLs, Dublin Core metadata, and the Z39.50 search and retrieval protocol. |
 |
Patricia (Trisha) Cruse is the founding director of the University of California Curation Center (UC3) at the California Digital Library and is responsible for all services within UC3. She works collaboratively with the ten UC campuses to develop sustainable strategies for the curation and preservation of digital content that supports the research, teaching, and learning mission of the University. Trisha has developed and oversees several of CDL's major initiatives, including the NDIIP-funded Web Archiving Service, micro-services, a new and innovative approach to building infrastructure, the Merritt Repository, and the EZID Service. |
 |
Greg Janée is a software developer for the University of California Curation Center at the California Digital Library and for the Earth Research Institute at the University of California at Santa Barbara. He previously served as technical leader of the National Geospatial Digital Archive (NGDA), Alexandria Digital Library (ADL), Alexandria Digital Earth Prototype (ADEPT), and ADL Gazetteer projects. Greg has an M.S. in computer science and a B.S. in mathematics, both from the University of California at Santa Barbara. |
|
|
|
| P R I N T E R - F R I E N D L Y F O R M A T | Return to Article |